要使测试用例达到灵活可复用,参数化是非常重要的。因为如果我们把所有的用例都写死,那么每次执行时,要修改的地方就太多了,所以,我们把通用的参数抽离出来。
下面总结一下实际应用中用到的几种参数化方式。
1、直接定义参数
比如:
请求中有个appid字段,很多个请求中都包含这个字段,如果我们写死了,那么如果换一个appid时,就得去每个请求里改一次。
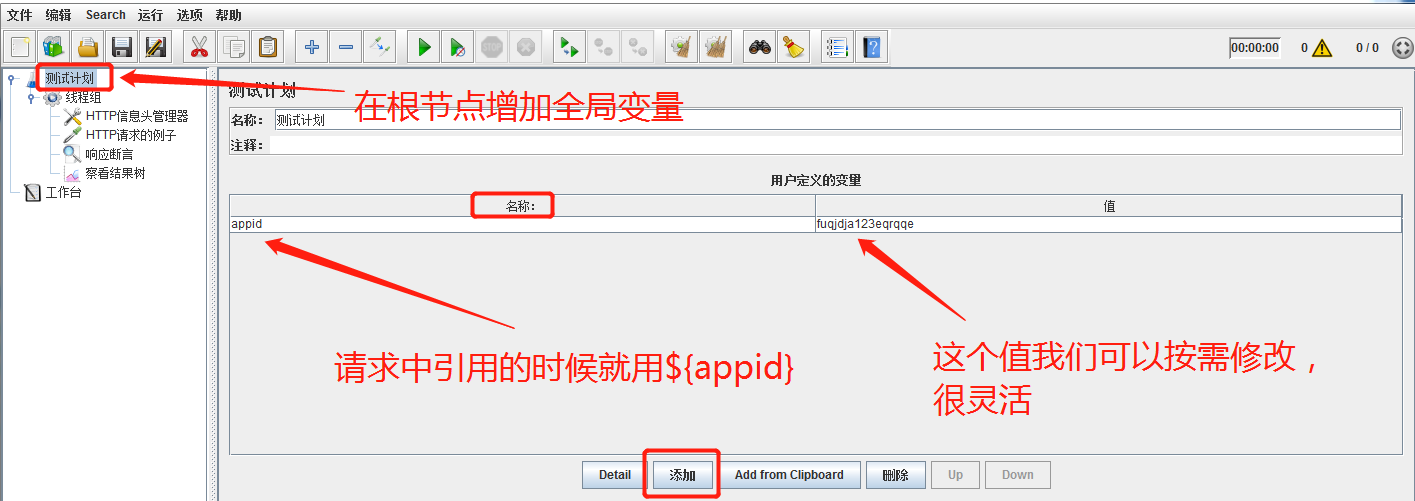
此时,我们把这个字段的值参数化,在统一的地方定义,如果修改,直接修改定义的地方就可以了,只需修改一次。在请求中引用这个参数时,就可以通过${appid}来引用。
没定义参数前(写死的请求):

1)定义全局参数:
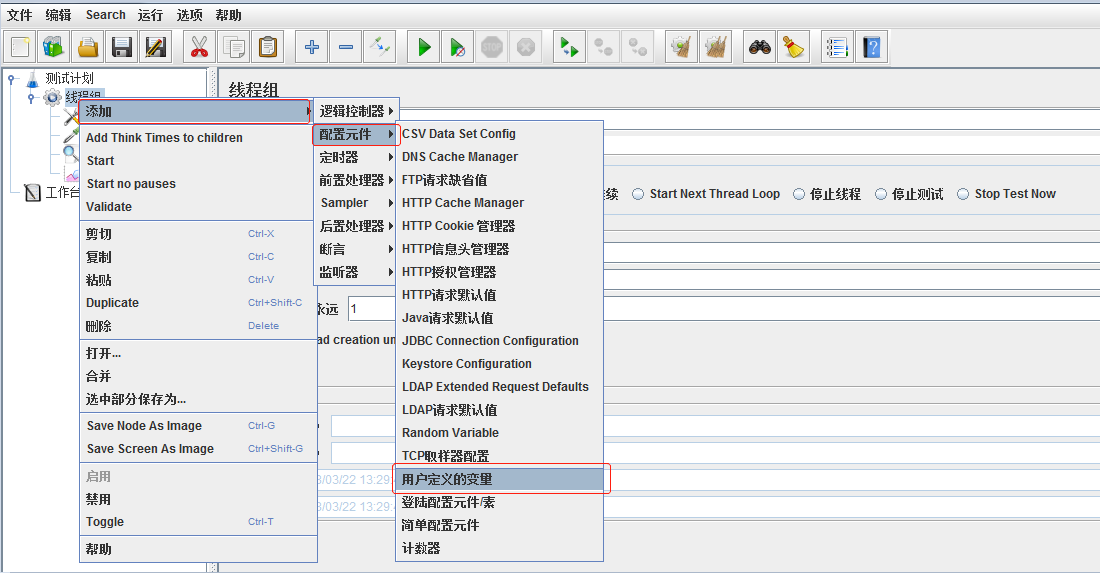
2)也可以定义局部参数,作用域为当前线程组:
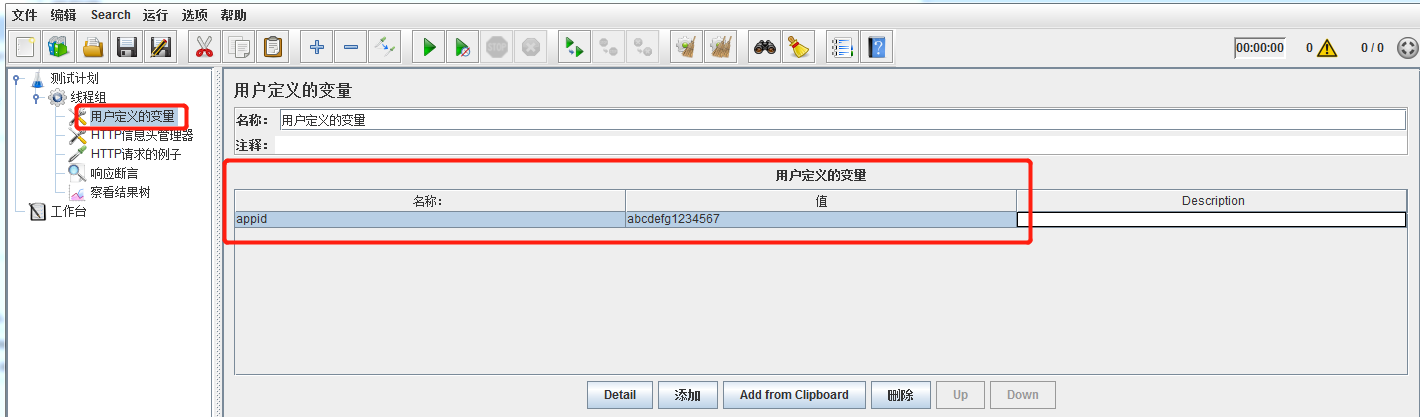
添加变量,和添加全局变量的方式相同:
3)在请求中引用的时候,直接写${appid}就可以了:

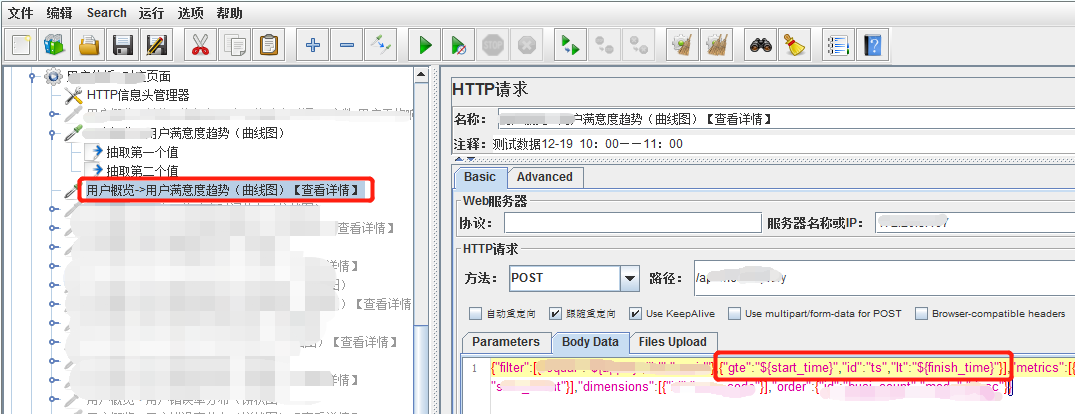
2、有时我们需要使用上个请求响应中的内容,作为参数,传给下面的请求。
比如:我们的第一个请求返回一个时间序列,第二个请求要查看序列中两个时间点之间的值,这时,我们需要获取第一个请求中的第一个时间点和第二个时间点,来作为第二个请求的参数,查看某个时间段的详情。

那么我们在第一个请求里添加后置处理器,按照json路径抽取出需要的值。
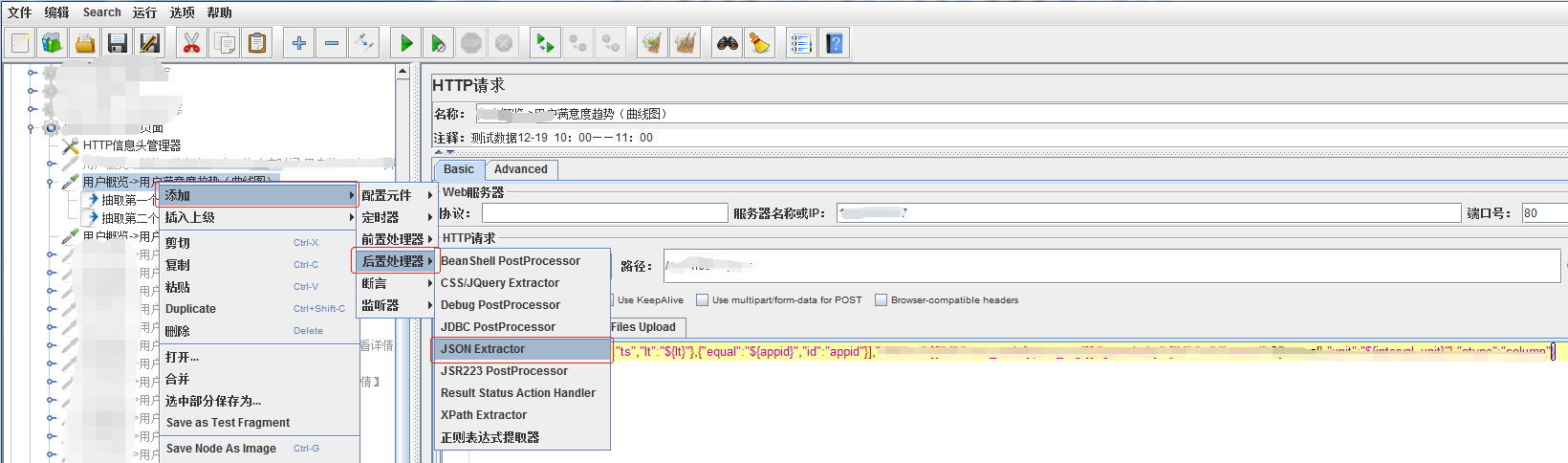

在下一个请求中使用,${start_time},${finish_time},如下:
3、从外部文件导入参数
这里利用CSV Data Set Config元件,导入外部CSV文件中的数据。
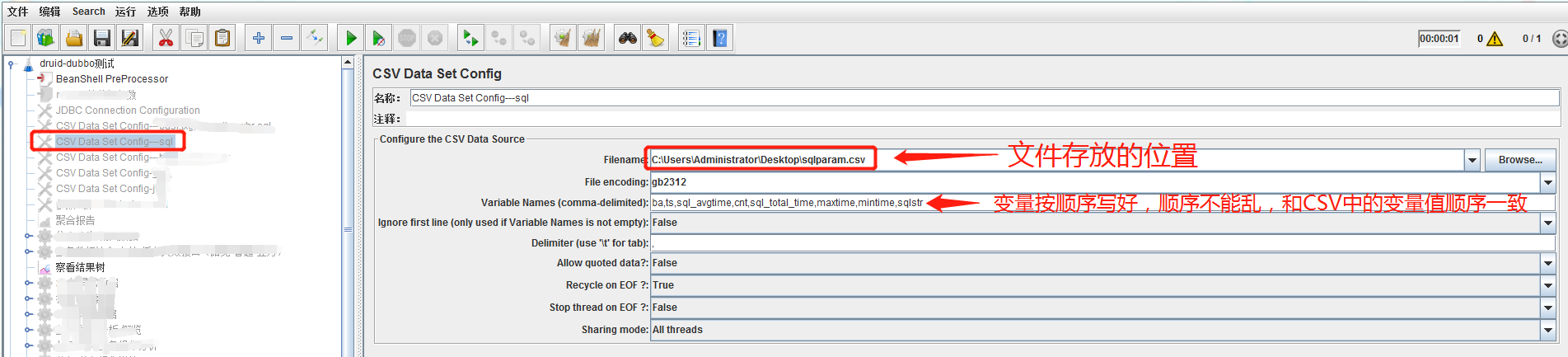
CSV配置界面:
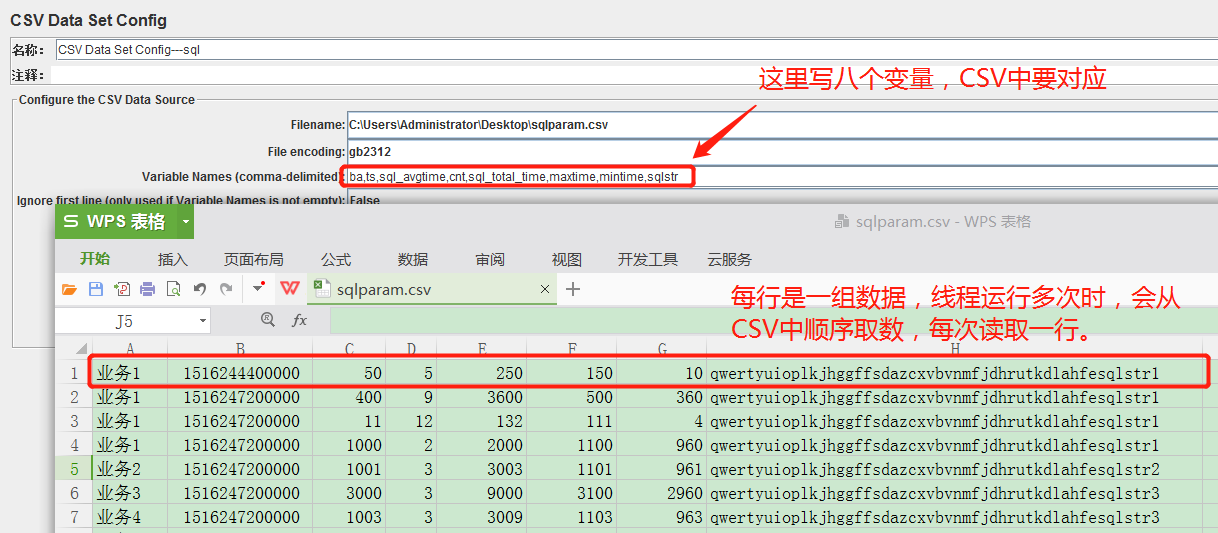
CSV文件内容举例,比如对于ba变量,线程执行第一次,会获取到“业务1”,ts会获取到1516244400000,以此类推。
4、就是利用脚本处理,生成参数,Jmeter的前置处理器和后置处理器中,都有可以编辑脚本的元件,通过BeanShell脚本规则编写,这种脚本语言类似于java。
我们通过vars.put(“参数名”,“参数值”),把生成的参数传到参数池,后续的用例可使用,通过vars.get("参数名")。往参数池增加参数时,如果名称已存在,会覆盖原有值;原来不存在时,会新建。
编写脚本的窗口:
以上,常用的几种生成参数的方式都提到了,没有好坏之分,只是按照实际需要,选择适当的方式。