kafka是什么
Kafka最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调
的,发布/订阅模式的消息队列(Message Queue),Linkedin于2010年贡献给了Apache基金会并成
为顶级开源项目。
经过多年发展,Kafka已经由最初的日志分发系统的一个模块,发展为一个通用的分布式消息队列,大
有发展成为一个流处理平台的趋势。
目前主要应用于大数据实时处理领域,作为分布式消息队列来使用,因此本课程主要聚焦于Kafka作为
分布式消息队列的方方面面。
Kafka主要设计目标如下:
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问
性能。
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
支持Kafka Server(Kafka Broker)间的消息分区,及分布式消费,同时保证每个partition内的消息
顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展
官网:
http://kafka.apache.org/
Kafka安装
#安装Linux下的多线程下载工具
wget http://download-ib01.fedoraproject.org/pub/epel/7/x86_64/Packages/a/axel-2.4-9.el7.x86_64.rpm
sudo rpm -ivh axel-2.4-9.el7.x86_64.rpm
#下载Kafka安装包
axel -n 15 https://archive.apache.org/dist/kafka/2.0.0/kafka_2.12-2.0.0.tgz

集群部署
安装
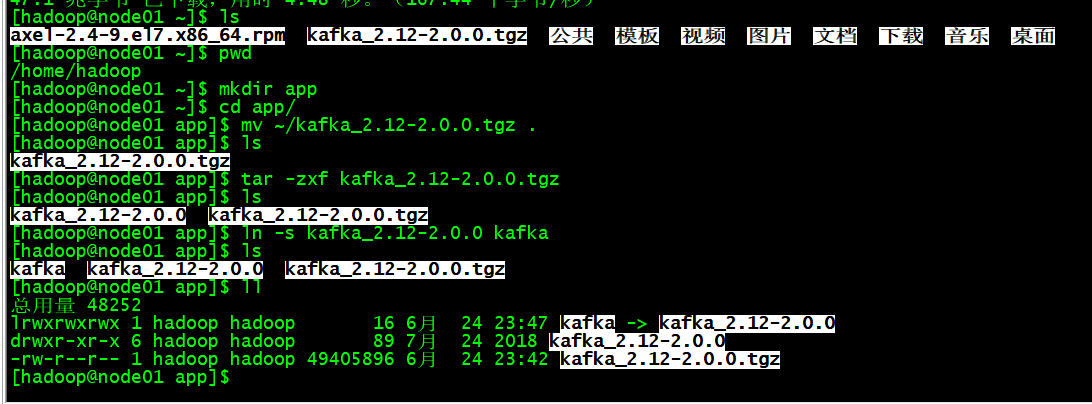
在node01上
mkdir app
cd app
mv ~/kafka_2.12-2.0.0.tgz .
tar -zxf kafka_2.12-2.0.0.tgz
ln -s kafka_2.12-2.0.0 kafka
修改配置
在node01上:
编辑配置文件
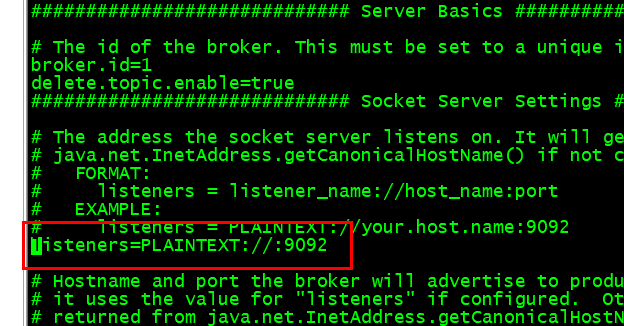
vi /home/hadoop/app/kafka/config/server.properties
主要配置项如下:
#broker 的全局唯一编号,不能重复(拷贝到其他节点是必须修改)
broker.id=0
#是否允许删除topic
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#存放kafka log,所谓的log是指的数据,不是我们通常理解的那个log
log.dirs=/home/hadoop/app/kafka/data
#topic默认分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接 Zookeeper 集群地址
zookeeper.connect=node01:2181/kafka_2_0_0
分发到各个节点
通过scp把kafka分发到node02和node03。
修改broker.id
在node02-node03上分别把配置文件中的 broker.id改为1和2。
创建数据目录
创建目录用于kafka存放log(所谓的log是指的数据,不是我们通常理解的那个log):
在node01-node03上:
mkdir /home/hadoop/app/kafka/data
配置环境变量
在node01-03上
sudo vi /etc/profile
#KAFKA_HOME export KAFKA_HOME=/home/hadoop/app/kafka export PATH=$PATH:$KAFKA_HOME/bin
保存退出,使环境变量
source /etc/profile
启动集群
在node01-node03上
cd $KAFKA_HOME
bin/kafka-server-start.sh -daemon config/server.properties
关闭集群
在node01-node03上
cd $KAFKA_HOME
bin/kafka-server-stop.sh stop
执行命令行
#查看topic列表 kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --list #创建topic kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --create --replication-factor 3 --partitions 1 --topic first #删除topic kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --delete --topic first #控制台发送消息 kafka-console-producer.sh --broker-list node01:9092 --topic first #控制台消费消息 kafka-console-consumer.sh --bootstrap-server node01:9092 --topic first #查topic详情 kafka-topics.sh --zookeeper node01:2181/kafka_2_0_0 --describe --topic first

控制台发送消息
修改kafka的配置文件
在node01-03上配置
vi /home/hadoop/app/kafka/config/server.properties
重启一下kafka
启动生产者

启动消费者

数据来源这生产者的

查topic详情

Kafka基本编程
创建maven项目
具体创建步骤就不多说了

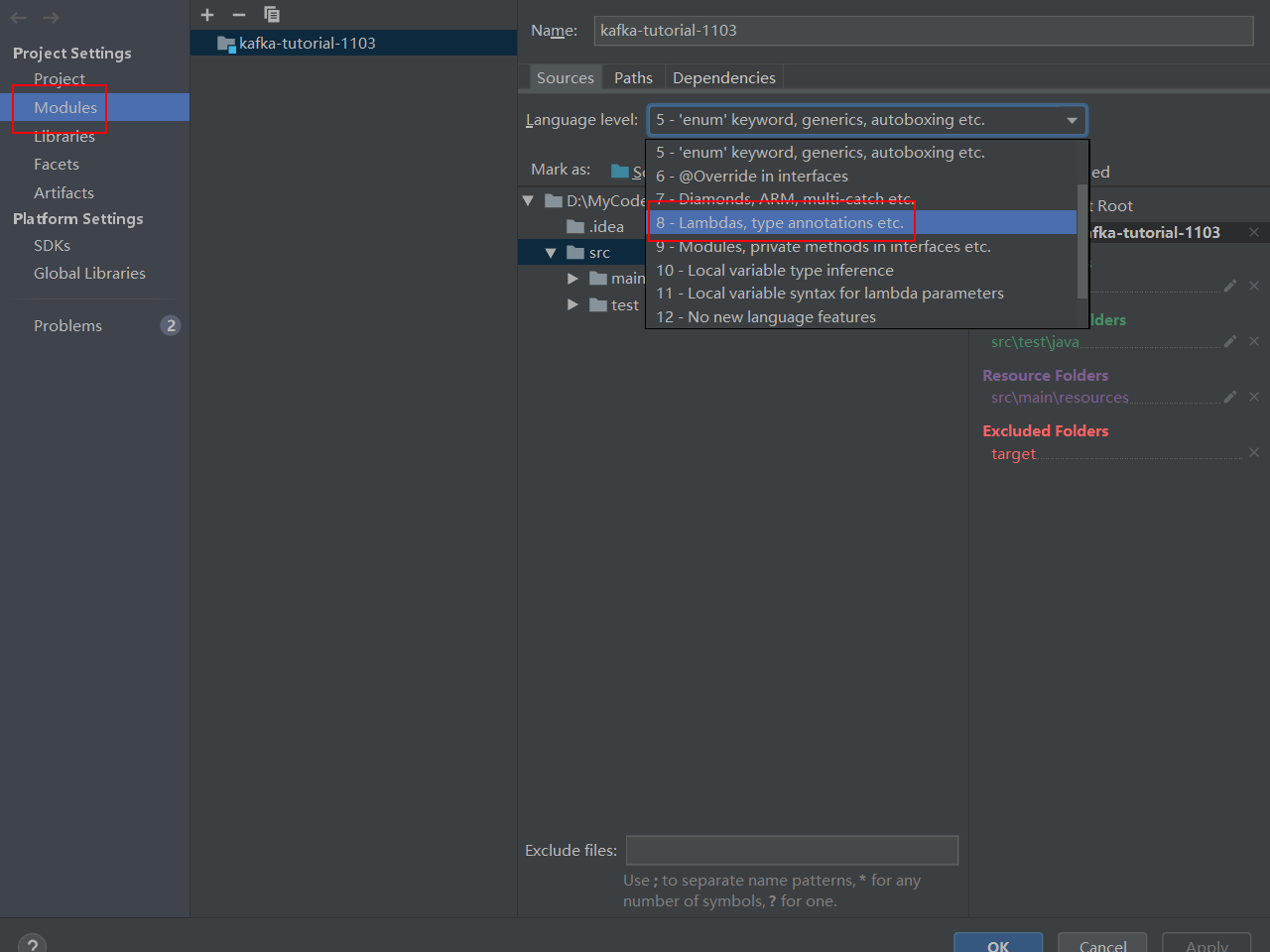
引入依赖包pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-streams -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.0.0</version>
</dependency>
创建一个生产者类
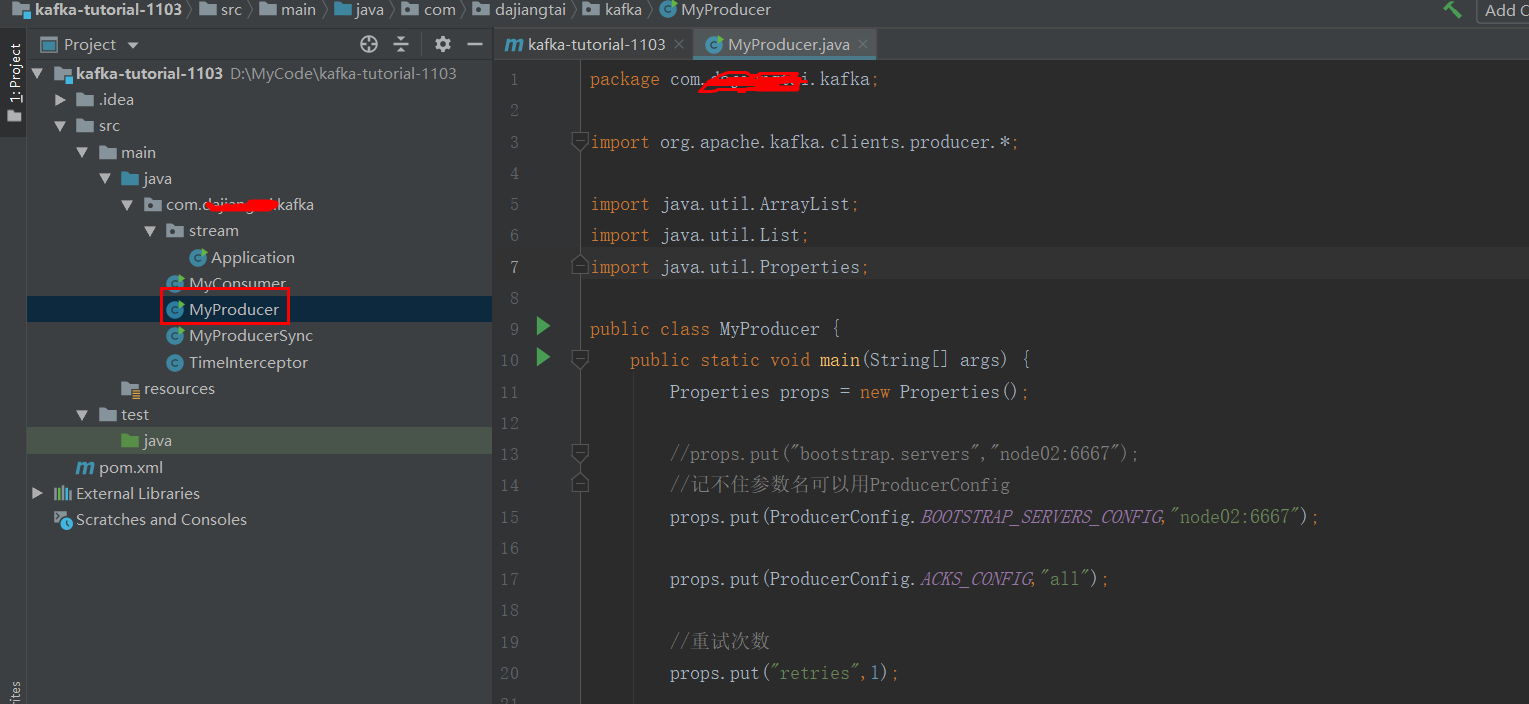
不带回调函数的发送
package com.dajiangtai.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {
Properties props = new Properties();
//props.put("bootstrap.servers","node02:6667");
//记不住参数名可以用ProducerConfig
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092");
props.put(ProducerConfig.ACKS_CONFIG,"all");
//重试次数
props.put("retries",1);
//批次大小
props.put("batch.size",16384);
//等待时间
props.put("linger.ms",2);
//RecordAccumulator缓冲区大小
props.put("buffer.memory",33554432);
//指定key和value序列化器
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 拦截器
// List<String> interceptorList = new ArrayList();
// interceptorList.add("com.dajiangtai.kafka.TimeInterceptor");
// props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptorList);
KafkaProducer<String , String> producer= new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<>("test","key"+i,"value"+i)) ;
// producer.send(new ProducerRecord<>("test1", "key" + i, "value" + i), new Callback() {
//
// //// 回调函数,该方法会在Producer收到 ack时调用 ,异步时调用
// @Override
// public void onCompletion(RecordMetadata metadata, Exception exception) {
// if(null==exception){
// System.out.println("send success: offset is :"+metadata.offset());
// }else {
// exception.printStackTrace();
// }
// }
// }) ;
}
producer.close();
}
}
启动kafka
在node01-node03上
cd $KAFKA_HOME
bin/kafka-server-start.sh -daemon config/server.properties
运行生产程序
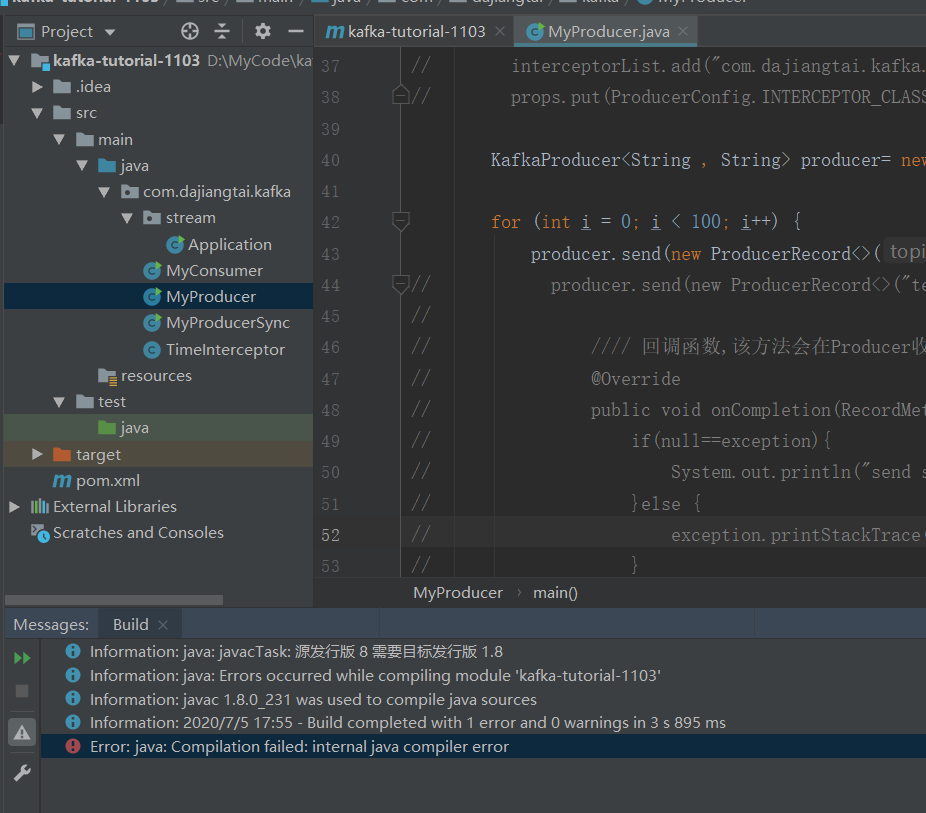
报错了
修改这里

运行成功
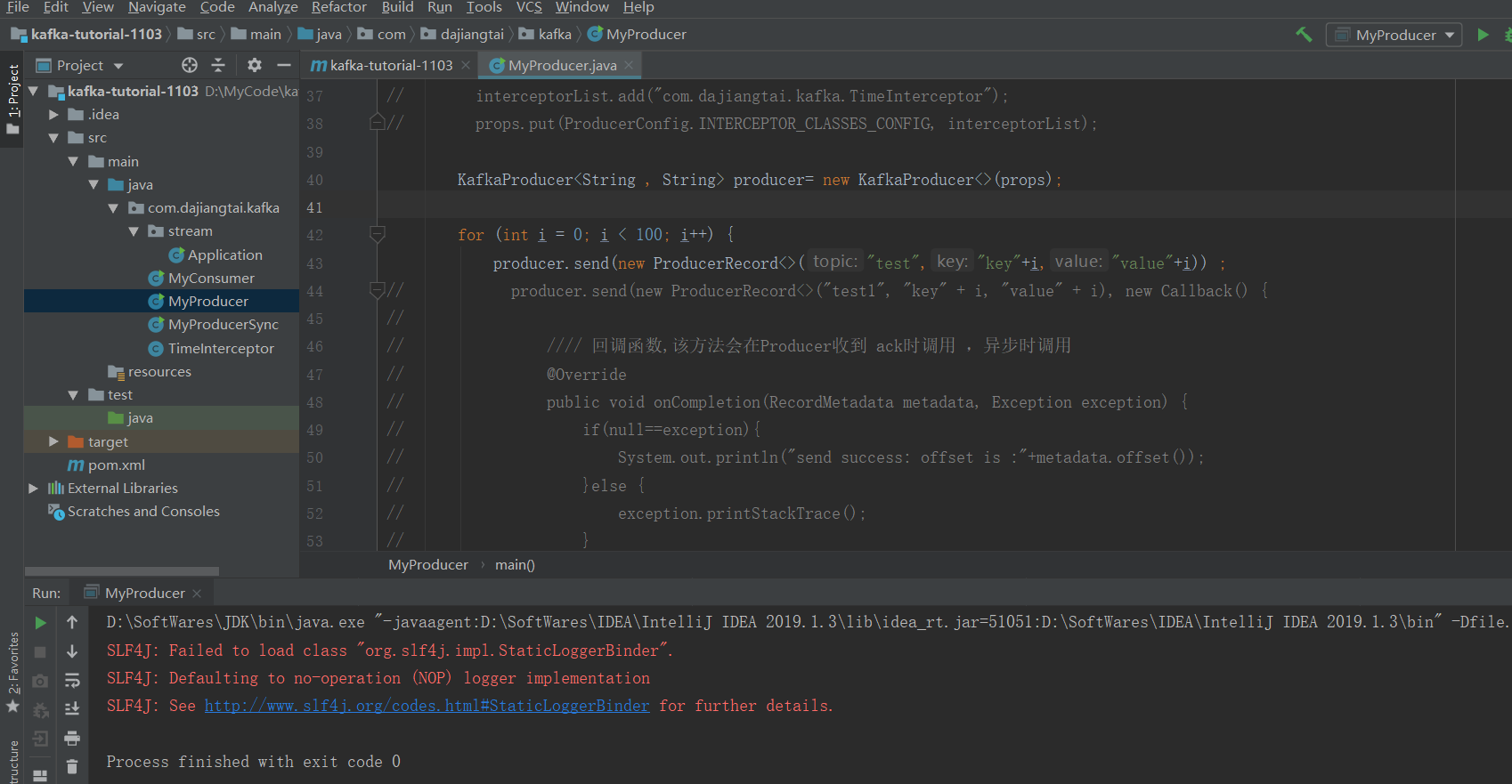

带回调函数的生产者类
package com.dajiangtai.kafka; import org.apache.kafka.clients.producer.*; import java.util.ArrayList; import java.util.List; import java.util.Properties; public class MyProducer { public static void main(String[] args) { Properties props = new Properties(); //props.put("bootstrap.servers","node02:6667"); //记不住参数名可以用ProducerConfig props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092"); props.put(ProducerConfig.ACKS_CONFIG,"all"); //重试次数 props.put("retries",1); //批次大小 props.put("batch.size",16384); //等待时间 props.put("linger.ms",2); //RecordAccumulator缓冲区大小 props.put("buffer.memory",33554432); //指定key和value序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 拦截器 // List<String> interceptorList = new ArrayList(); // interceptorList.add("com.dajiangtai.kafka.TimeInterceptor"); // props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptorList); KafkaProducer<String , String> producer= new KafkaProducer<>(props); for (int i = 0; i < 1000000; i++) { // producer.send(new ProducerRecord<>("test","key"+i,"value"+i)) ; producer.send(new ProducerRecord<>("test1", "key" + i, "value" + i), new Callback() { //// 回调函数,该方法会在Producer收到 ack时调用 ,异步时调用 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if(null==exception){ System.out.println("send success: offset is :"+metadata.offset()); }else { exception.printStackTrace(); } } }) ; } producer.close(); } }
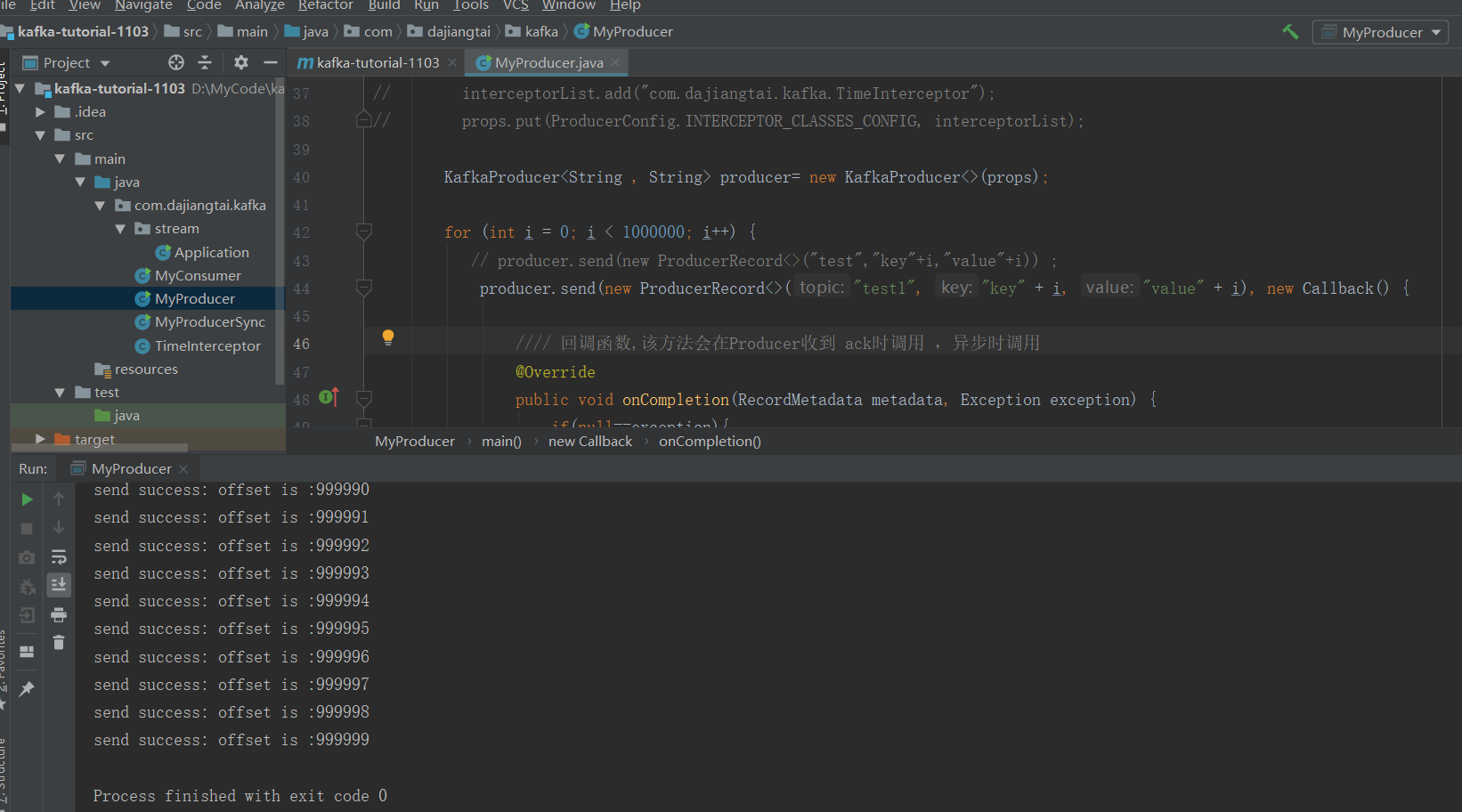
同步发送
package com.dajiangtai.kafka; import org.apache.kafka.clients.producer.*; import java.util.Properties; import java.util.concurrent.ExecutionException; public class MyProducerSync { public static void main(String[] args) throws ExecutionException, InterruptedException { Properties props = new Properties(); //props.put("bootstrap.servers","node02:6667"); //记不住参数名可以用ProducerConfig props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092"); props.put("acks","all"); //重试次数 props.put("retries",1); //批次大小 props.put("batch.size",16384); //等待时间 props.put("linger.ms",2); //RecordAccumulator缓冲区大小 props.put("buffer.memory",33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String , String> producer= new KafkaProducer<>(props); for (int i = 0; i < 100; i++) { producer.send(new ProducerRecord<>("test2","key"+i,"value"+i)).get(); } producer.close(); } }
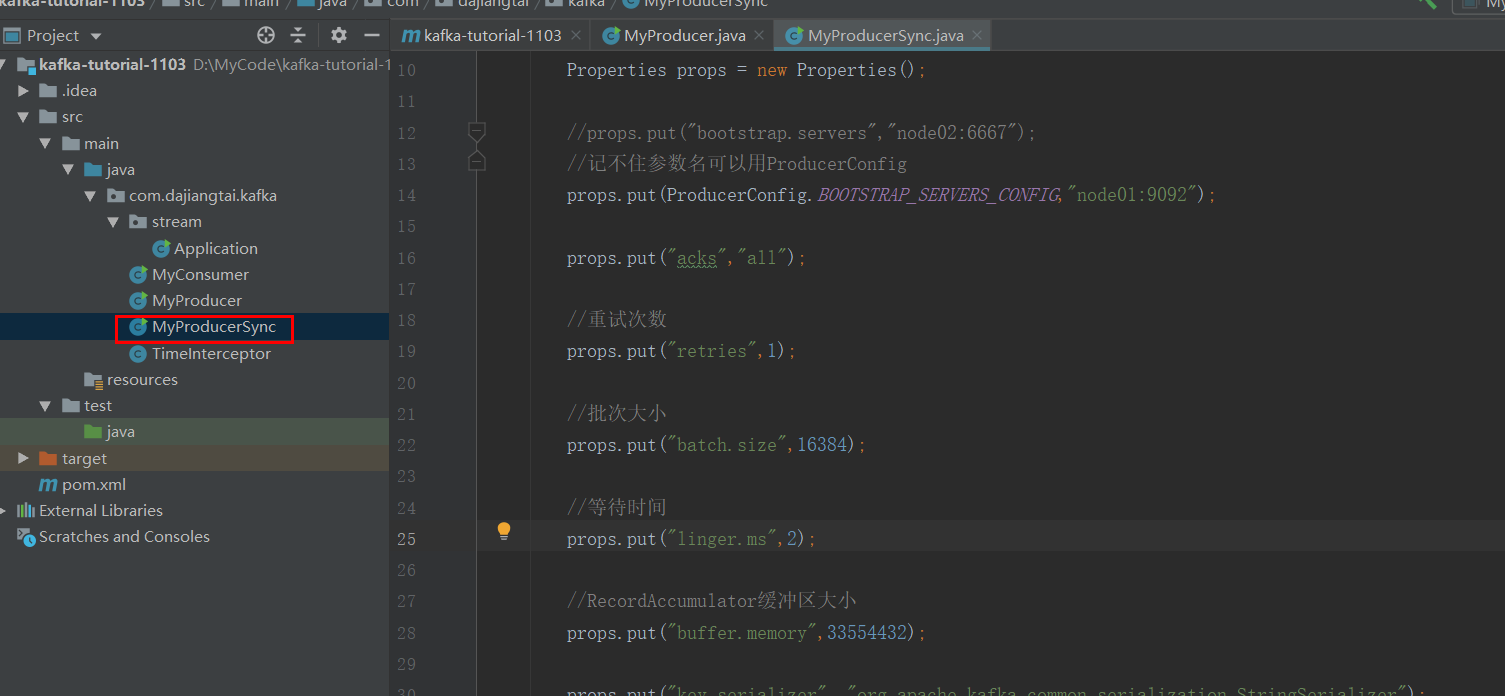
send方法返回的是一个Future对象,根据 Futrue对象的特点,只需在调用 Future对象的 get方法即可
实现同步。
查看topic

Consumer编程
数据可靠性由Kafka来保证,Consumer不用担心数据丢失的问题。但是Consumer在消费过程中可能会
异常宕机,所以必须考虑如何维护offset,以便于后续故障恢复接着消费
自动提交offset
1. enable.auto.commit:是否开启自动提交功能
2. auto.commit.interval.ms:自动提交offset的时间隔
package com.dajiangtai.kafka;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.time.Duration;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
public class MyConsumer {
public static void main(String[] args) {
Properties props = new Properties();
//props.put("bootstrap.servers","node02:6667");
//记不住参数名可以用ProducerConfig
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092");
//指定group_id,相同group_id的消费者就属于一个组
props.put(ConsumerConfig.GROUP_ID_CONFIG,"test_group");
//初次消费时从哪里开始消费
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
//自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
// props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");
//指定key和value的反序列化器
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
//创建消费者
KafkaConsumer<String,String> consumer=new KafkaConsumer<>(props);
//订阅主题
consumer.subscribe(Arrays.asList("test10"));
//循环获取消息
while (true){
ConsumerRecords<String,String> records=consumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n",record.offset(),record.key(),record.value());
}
//同步提交
//consumer.commitSync();
//异步提交
// consumer.commitAsync(new OffsetCommitCallback() {
// @Override
// public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
// if(null!=exception){
// System.out.println("commit fail: "+ offsets);
// }
// }
// });
}
}
}
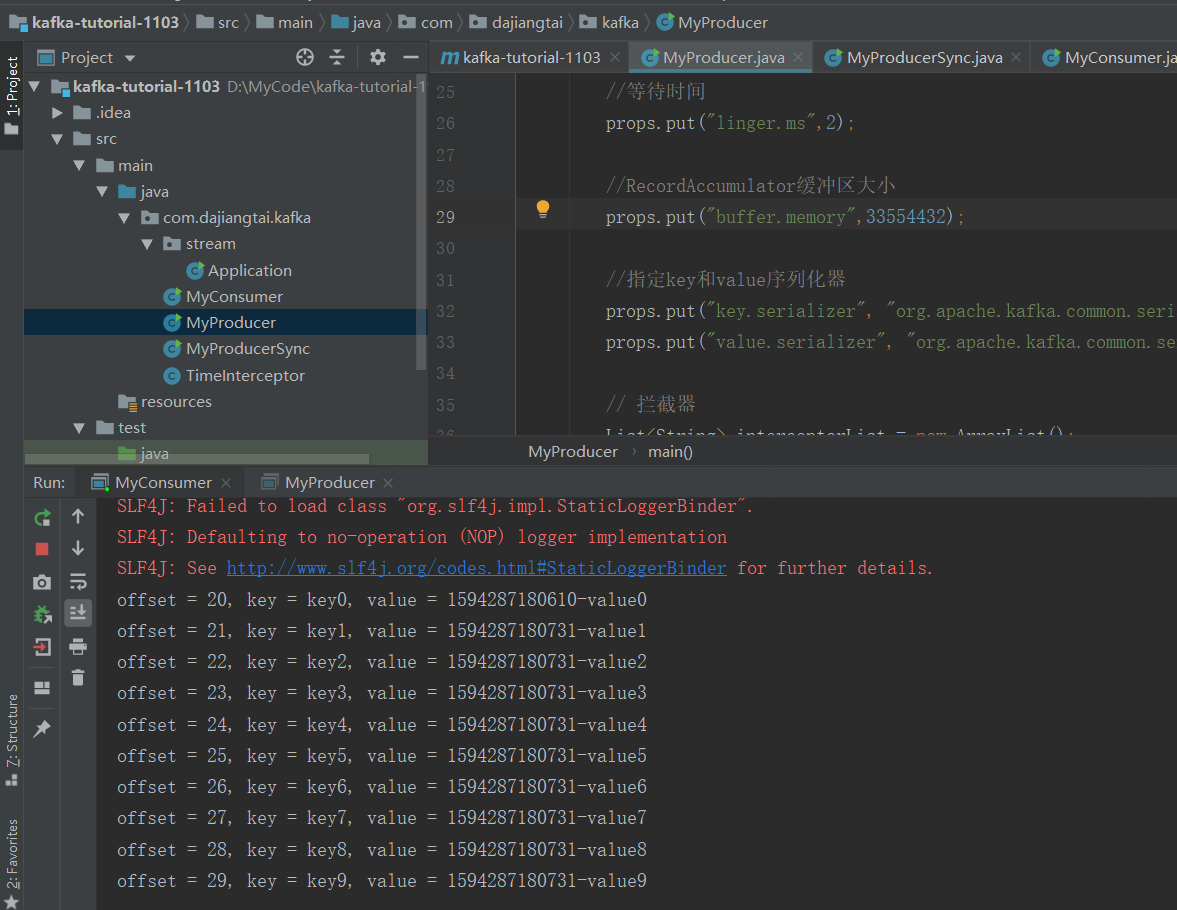
初次消费一个新的topic会没有数据,因此需要在生产者那边运行一下就有想对应的数据了,生产者对应的程序的topic必须跟消费者的一样
这个是生产者的数据
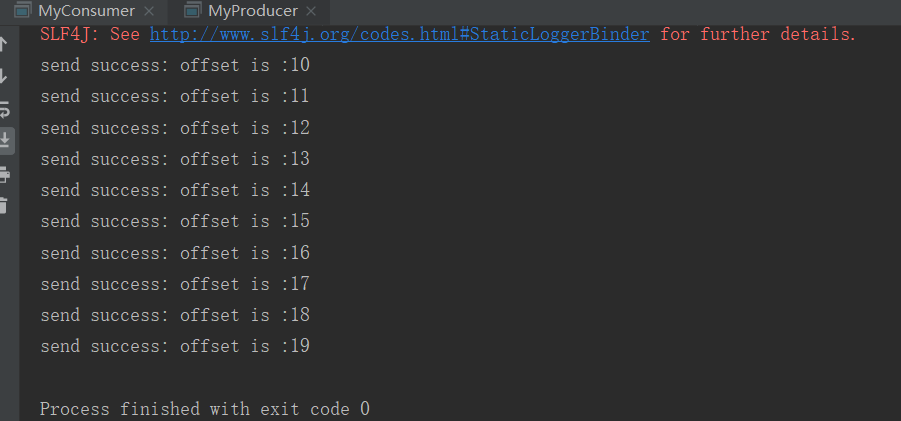
这边是消费者消费的数据
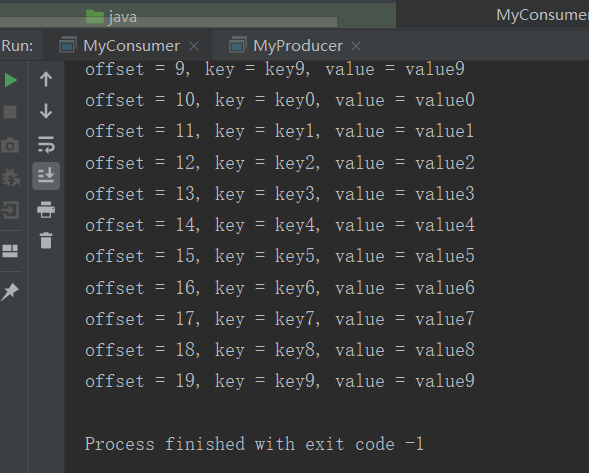
手动提交offset
自动提交很便利,但是在大多数场景下很难保证已经提交offset的数据一定被处理完了(业务逻辑上),因
此手动提交就很重要了,分两种方式:
1. commitSync(同步提交)
2. commitAsync(异步提交)
两种方式都会将本次poll的一批数据的最大偏移量提交,不同的是commitSync会阻塞当前线程一直到
提交成功,并且会自动重试(不能保证一定提交成功),而commitAsync不阻塞当前线程且没有重试机
制,提交失败的可能性更大 。
同步提交代码
package com.dajiangtai.kafka; import org.apache.kafka.clients.consumer.*; import org.apache.kafka.common.TopicPartition; import java.time.Duration; import java.util.Arrays; import java.util.Map; import java.util.Properties; public class MyConsumer { public static void main(String[] args) { Properties props = new Properties(); //props.put("bootstrap.servers","node02:6667"); //记不住参数名可以用ProducerConfig props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092"); //指定group_id,相同group_id的消费者就属于一个组 props.put(ConsumerConfig.GROUP_ID_CONFIG,"test_group"); //初次消费时从哪里开始消费 props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //自动提交 // props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); //指定key和value的反序列化器 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); //创建消费者 KafkaConsumer<String,String> consumer=new KafkaConsumer<>(props); //订阅主题 consumer.subscribe(Arrays.asList("test10")); //循环获取消息 while (true){ ConsumerRecords<String,String> records=consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n",record.offset(),record.key(),record.value()); } //同步提交 consumer.commitSync(); //异步提交 // consumer.commitAsync(new OffsetCommitCallback() { // @Override // public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { // if(null!=exception){ // System.out.println("commit fail: "+ offsets); // } // } // }); } } }
异步提交代码
package com.dajiangtai.kafka; import org.apache.kafka.clients.consumer.*; import org.apache.kafka.common.TopicPartition; import java.time.Duration; import java.util.Arrays; import java.util.Map; import java.util.Properties; public class MyConsumer { public static void main(String[] args) { Properties props = new Properties(); //props.put("bootstrap.servers","node02:6667"); //记不住参数名可以用ProducerConfig props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092"); //指定group_id,相同group_id的消费者就属于一个组 props.put(ConsumerConfig.GROUP_ID_CONFIG,"test_group"); //初次消费时从哪里开始消费 props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); //自动提交 // props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false"); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000"); //指定key和value的反序列化器 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); //创建消费者 KafkaConsumer<String,String> consumer=new KafkaConsumer<>(props); //订阅主题 consumer.subscribe(Arrays.asList("test10")); //循环获取消息 while (true){ ConsumerRecords<String,String> records=consumer.poll(Duration.ofSeconds(5)); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n",record.offset(),record.key(),record.value()); } //同步提交 // consumer.commitSync(); //异步提交 consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if(null!=exception){ System.out.println("commit fail: "+ offsets); } } }); } } }
生产者拦截器
生产者拦截器既可以用来在消息发送前做一些准备工作, 比如按照某个规则过滤不符合要求的消息、修
改消息的内容等, 也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作 。
生产者拦截器的使用也很方便,主要是自定义实现org. apache.kafka. clients.
producer.Producerlnterceptor 接口。ProducerInterceptor 接口中包含3 个方法:
public ProducerRecord<K, V> onSend (ProducerRecord<K, V> record); public void onAcknowledgement(RecordMetadata metadata, Excepti on exception ); public void close() ;
拦截器实现
package com.dajiangtai.kafka; import java.util.Map; import org.apache.kafka.clients.producer.ProducerInterceptor; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; public class TimeInterceptor implements ProducerInterceptor<String, String> { // 配置信息 public void configure(Map<String, ?> configs) { // TODO Auto-generated method stub } // 拦截逻辑 public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { return new ProducerRecord<String, String>(record.topic(), record.partition(), record.key(), System.currentTimeMillis() + "-" + record.value()); } // 发送失败时的应答 public void onAcknowledgement(RecordMetadata metadata, Exception exception) { } // 关闭 public void close() { } }

在生产者中使用拦截器 :
package com.dajiangtai.kafka; import org.apache.kafka.clients.producer.*; import java.util.ArrayList; import java.util.List; import java.util.Properties; public class MyProducer { public static void main(String[] args) { Properties props = new Properties(); //props.put("bootstrap.servers","node02:6667"); //记不住参数名可以用ProducerConfig props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node01:9092"); props.put(ProducerConfig.ACKS_CONFIG,"all"); //重试次数 props.put("retries",1); //批次大小 props.put("batch.size",16384); //等待时间 props.put("linger.ms",2); //RecordAccumulator缓冲区大小 props.put("buffer.memory",33554432); //指定key和value序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 拦截器 List<String> interceptorList = new ArrayList(); interceptorList.add("com.dajiangtai.kafka.TimeInterceptor"); props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptorList); KafkaProducer<String , String> producer= new KafkaProducer<>(props); for (int i = 0; i < 10; i++) { // producer.send(new ProducerRecord<>("test","key"+i,"value"+i)) ; producer.send(new ProducerRecord<>("test10", "key" + i, "value" + i), new Callback() { //// 回调函数,该方法会在Producer收到 ack时调用 ,异步时调用 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if(null==exception){ System.out.println("send success: offset is :"+metadata.offset()); }else { exception.printStackTrace(); } } }) ; } producer.close(); } }
先启动消费者
启动生产者产生数据
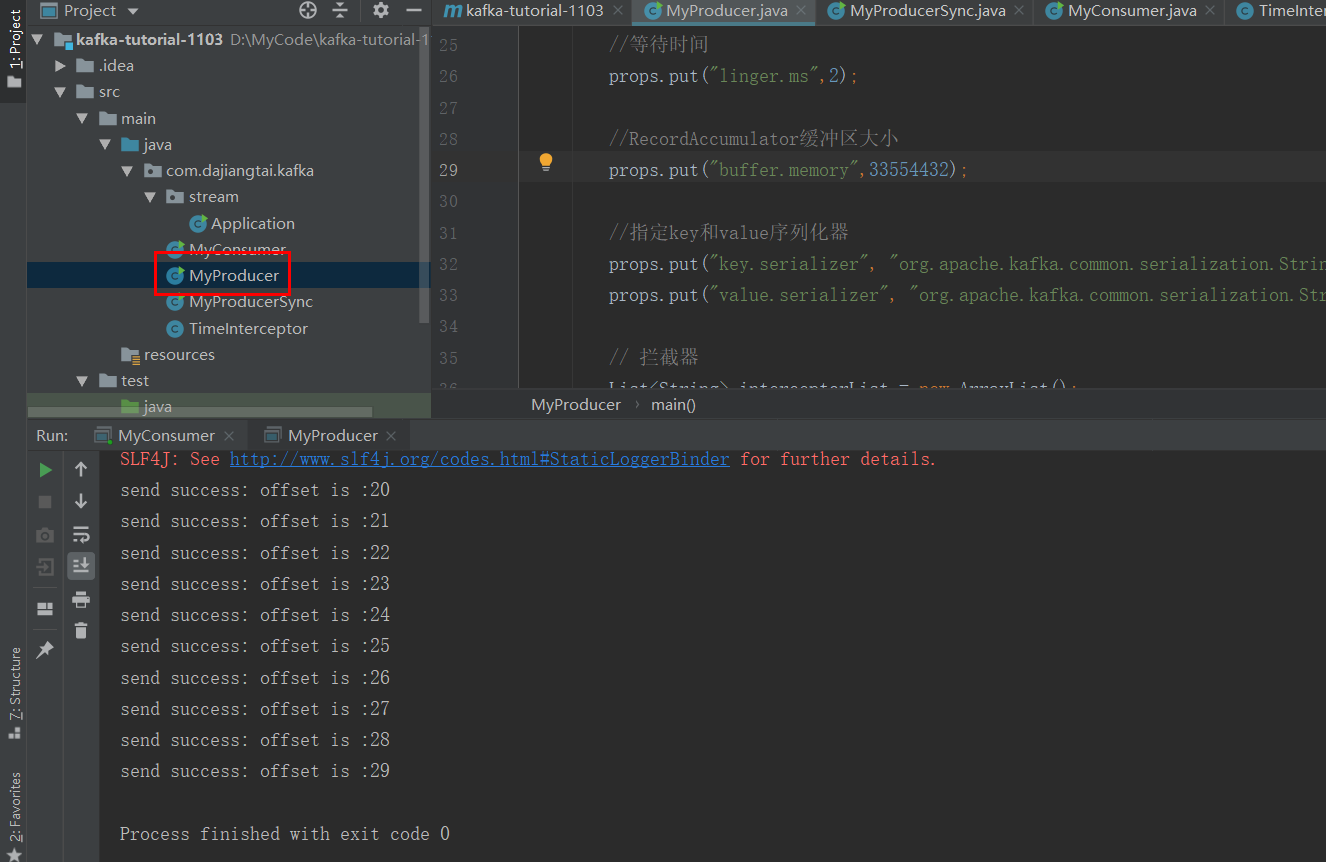
可以看到消费者这边消费数据