本文讨论的前提是在捕获了异常的情况下进行的说明。
1、 直接使用原生异常。直接抛出 Exception 或者 RuntimeException。
在业务代码层,直接抛出异常信息。这里不限定RuntimeException还是其他。
好处是,简单方便直接。
坏处是,部分调用方需要显式的抛出异常,且提示语不方便管理。
2、 项目包装RuntimeException。
直接继承RuntimeException,做一些简单的封装,类似如下代码
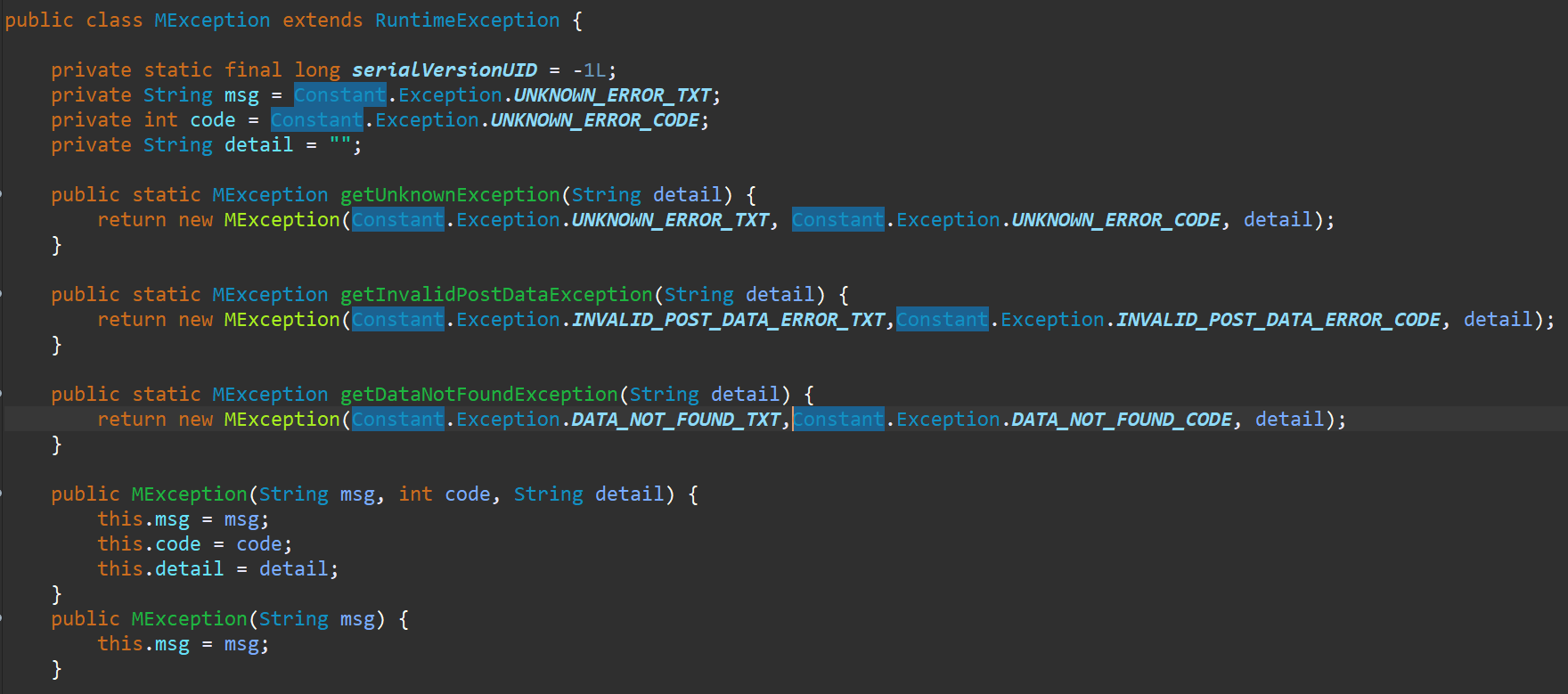
开发同学在使用时,直接new一个即可。总共两个构造方法可选,或者直接使用静态方法,生成包含对应detail的异常信息。其中常用的错误码、错误信息,都用一个静态类或者是枚举保存。我猜测大部分信息都采用的这种方式,而且这样的方式也满足一般的管理系统。
好处是方便,有一定的标准。
坏处是多个模块的开发者维护同一个枚举容易出现冲突,容易出现一个错误码被多次使用。
3、 多语言。
如果公司业务发展较快,明天要进军泰国市场,后天要进军沙特阿拉伯市场,那就得在枚举全部新增一套提示语。虽然这样的改动不难,但没啥技术含量。
所以我们将保存错误信息的枚举类进行改造,如下图
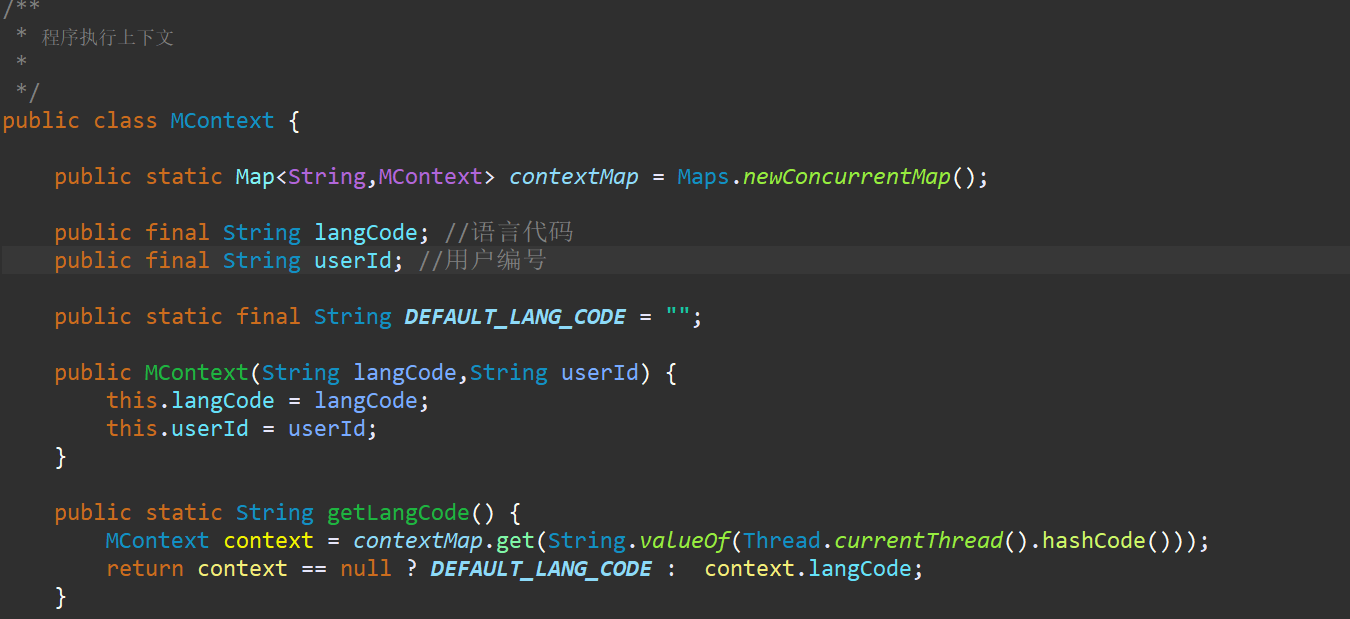
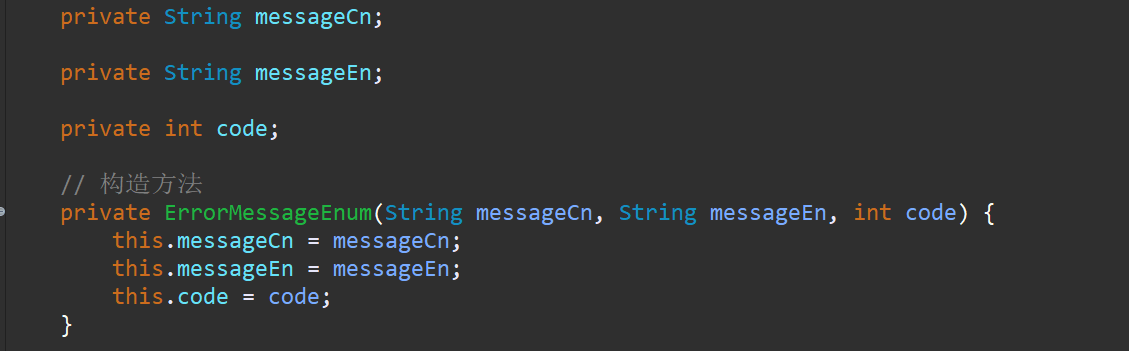
重写toString方法
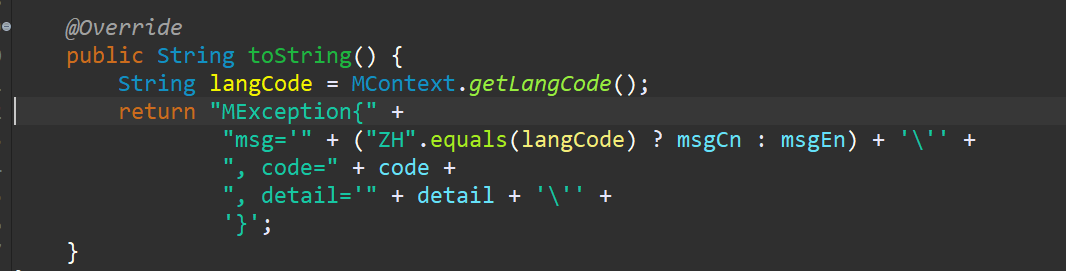
这样就会带来问题,因为每次都需要新增加或者维护异常信息,都需要维护枚举类现有的几套语言。
好处是方便,比较容易管理,支持多语言。
坏处当然是浪费开发的时间,且一旦出现提示语不对,还需要重新发版,费时费力。
4、 可配置的异常提示信息。
那既然现在的痛点是在维护上,我们何不考虑做成可配置?
以将异常信息放在数据为例,先看两张表。
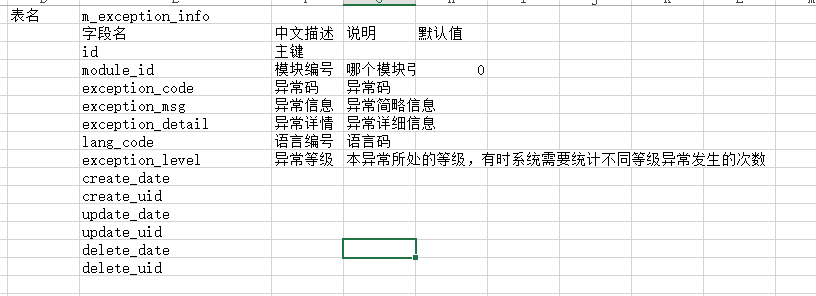

此时,发生异常,若代码抛出异常,必须带上exception_code,异常处理service去包装异常信息,一方面返回异常信息给用户,一方面将异常信息入库。
以springboot 为例
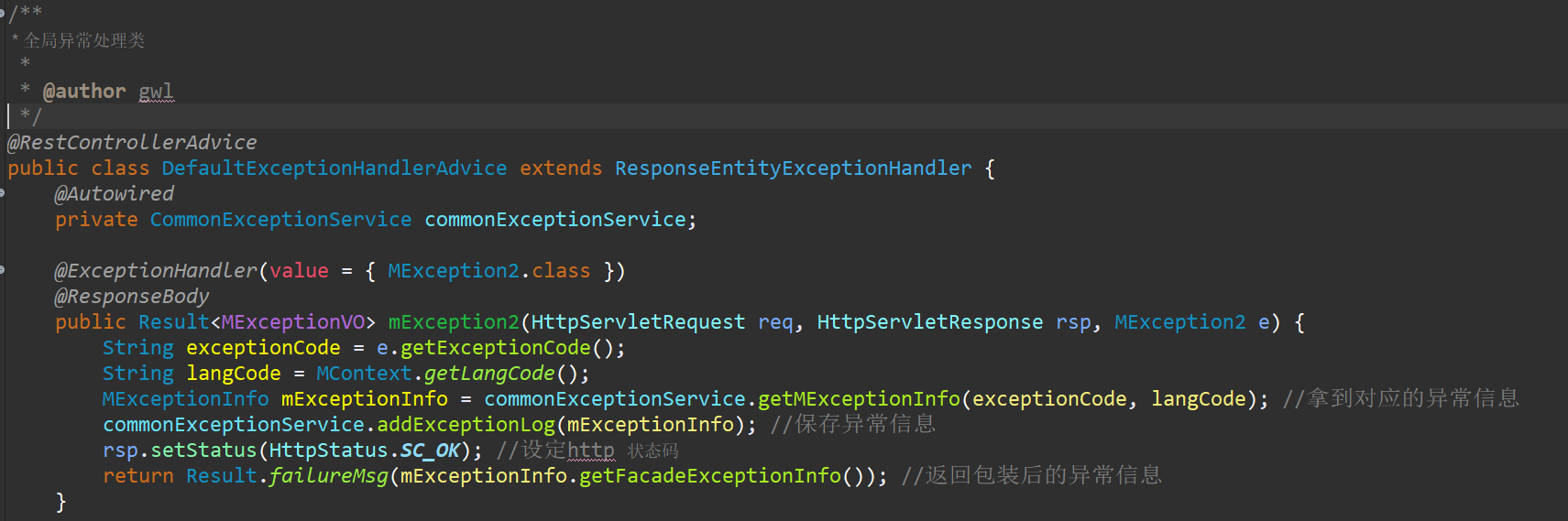
异常信息的包装策略此处不展开,各位可以自己想想如何包装。
这里好处就是异常信息可以随时调整,十分灵活,开发进行排查时也能有的放矢,不用去整个日志系统一遍一遍的去搜。
坏处可能就是写的代码有点多,搞这么复杂一时半会也没啥用。
5、 分布式系统的异常信息传递。
这里会与全链路日志追踪有交叉的地方。
举个栗子,我在手机qq查看联系人性别:
a) 打开手机qq(开始读取消息)
b) 打开联系人列表(读取在线状态)
c) 读取各种群消息(未收到的群消息)
d) 搜索联系人(本地搜索+服务器搜索)
e) 点开联系人详情页(获取用户通用基本信息、用户允许查看的隐私信息、用户背景图、qq会员系统、qq等级系统、各种钻、各种特权、头像挂件、个性签名、空间是否更新、最近常听)
f) 查看用户性别
而各个请求,可能又会去请求其他系统。
任何一个系统调用失败,都可能会导致功能出现各种各样的问题。
所以我们需要在异常信息中,传递一些必要信息,如 唯一请求编号、异常编码、异常机器ip等必要信息。假如调用链路是 S –> M -> Z -> E -> A -> H ,一旦E出现了异常并返回给Z,根据异常里面包含的信息,便能马上定位的机器,开始处理,而不是从链路的最开始一台一台机器去排查。
最后补一个问题,自定义异常处理了,那非自定义异常该怎么办呢?