elastic search 6.1.x
常用框架:
1、Lucene
Apache下面的一个开源项目,高性能的、可扩展的工具库,提供搜索的基本架构;
如果开发人员需用使用的话,需用自己进行开发,成本比较大,但是性能高
2、solr
Solr基于Lucene的全文搜索框架,提供了比Lucene更为丰富的功能,
同时实现了可配置、可扩展并对查询性能进行了优化
建立索引时,搜索效率下降,实时索引搜索效率不高
数据量的增加,Solr的搜索效率会变得更低,适合小的搜索应用,对应java客户端的是solrj
3、elasticSearch
基于Lucene的搜索框架, 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
上手容易,拓展节点方便,可用于存储和检索海量数据,接近实时搜索,海量数据量增加,搜索响应性能几乎不受影响;
分布式搜索框架,自动发现节点,副本机制,保障可用性
新特性讲解
1、6.1.x版本基于Lucene 7.1.0,更快,性能进一步提升,对应的序列化组件,升级到Jackson 2.8
2、自适应副本选择
今天在Elasticsearch中,对同一分片的一系列搜索请求将以循环方式转发到主要和每个副本。如果一个节点启动了长时间的垃圾收集,这可能会出现问题 - 搜索请求仍将被转发到缓慢的节点,并且会影响搜索延迟。在6.1中,我们添加了一个称为自适应副本选择的实验性功能。每个节点跟踪并比较搜索请求到其他节点的时间,并使用这些信息来调整向特定节点发送请求的频率。在我们的基准测试中,这样可以大大提高搜索吞吐量,降低99%的延迟。这个选项在默认情况下是禁用的
3、推荐使用5.0版本推出的Java REST/HTTP客户端,依赖少,比Transport使用更方便,在基准测试中,性能并不输于Transport客户端,在5.0到6.0版本中,每次有对应的API更新, 文档中也说明,推荐使用这种方式进行开发使用,所有可用节点间的负载均衡,在节点故障和特定响应代码的情况下进行故障转移,失败的连接处罚(失败的节点是否重试取决于失败的连续次数;失败的失败次数越多,客户端在再次尝试同一节点之前等待的时间越长
在centos7下安装elastic search
安装java环境:
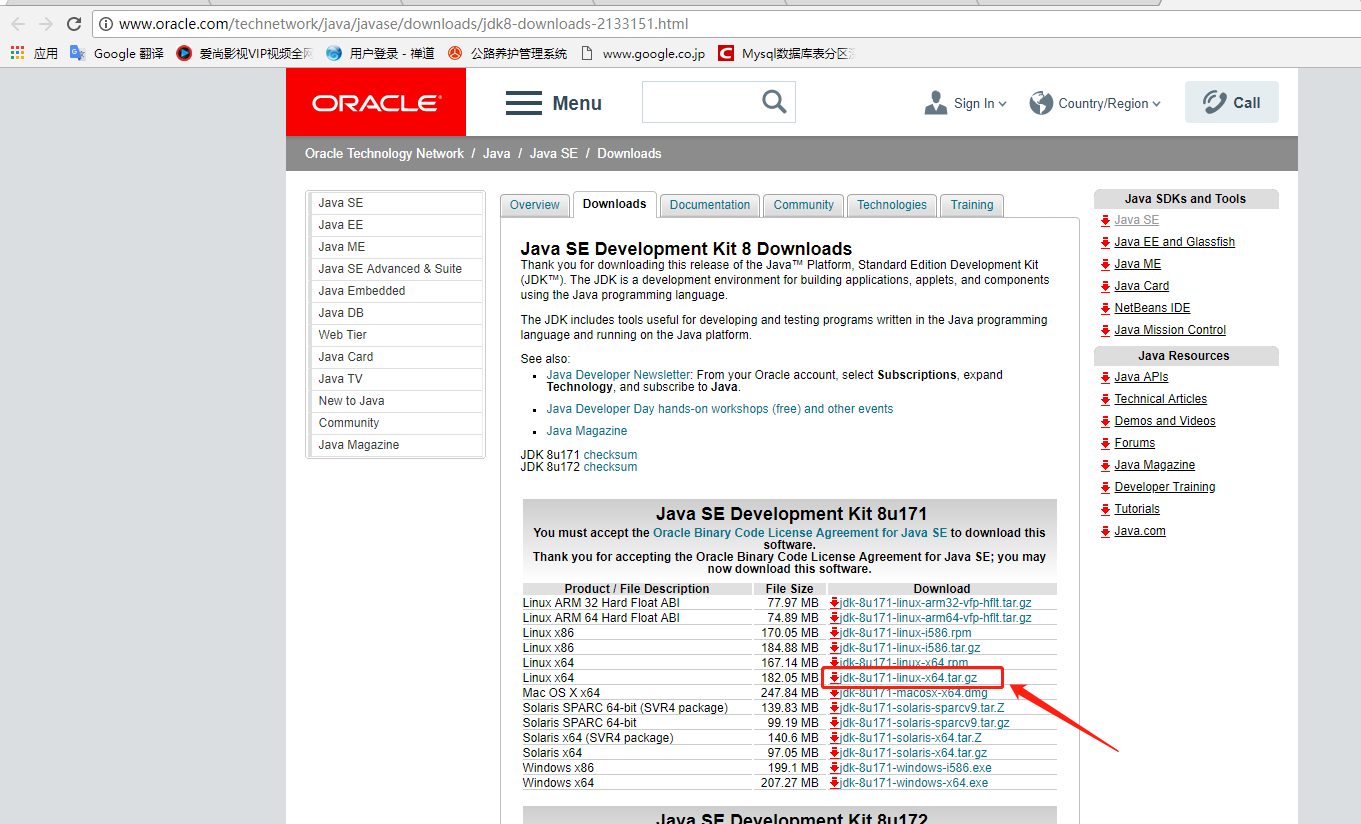
我的java安装目录是/usr/local/java 所以修改/etc/profile文件 vim /etc/profile JAVA_HOME=/usr/local/java PATH=$JAVA_HOME/bin:$PATH export JAVA_HOME PATH
修改完文在当前终端生效命令 source /etc/profile
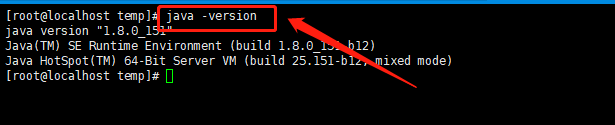
测试java环境是否正常命令 java -version 显示如下(正常)
安装elasticsearch:
官网是:www.elastic.co 下载
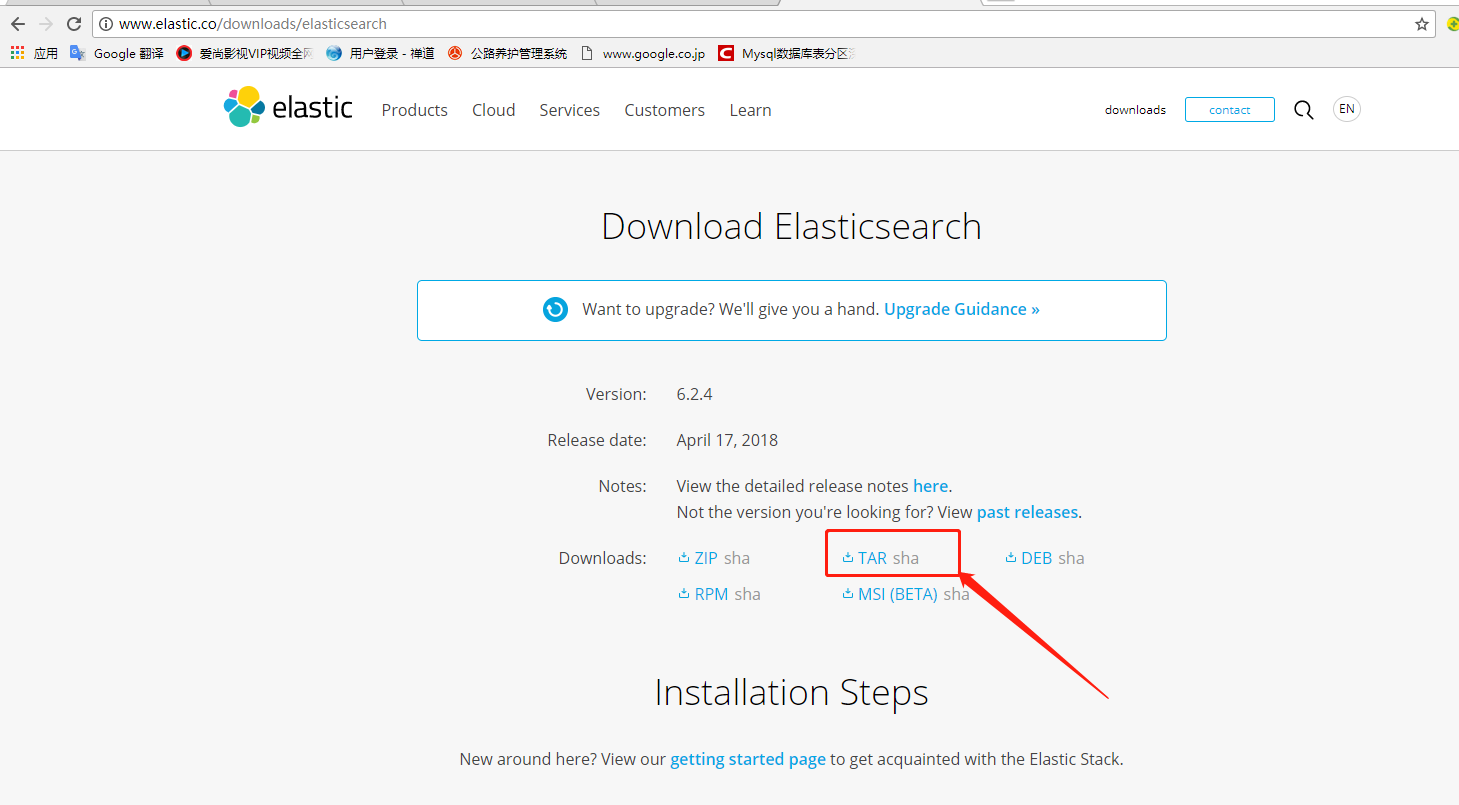
mkdir /temp #新建安装elastic目录 cd /temp tar -xvf elasticsearch-6.2.4.tar.gz #解压elastic文件 cd .. chmod -R 777 /temp #给目录权限 useradd -m elastic -G wheel #因为elastic不能用root用户去启动,创建新用户 su - elastic #切换用户
修改系统参数,确保系统有足够资源启动ES 设置内核参数 vim /etc/sysctl.conf #增加以下参数 vm.max_map_count = 655360 执行以下命令,确保生效配置生效: sysctl –p 设置资源参数 vim /etc/security/limits.conf #修改 * soft nofile 65536 #警告设定所有用户最大打开文件数 * hard nofile 131072 #严格设定所有用户最大打开文件数 * soft nproc 65536 #警告设定所有用户最大打开进程数为65535
* hard nproc 131072 #严格设定所有用户最大打开进程数为131072
vim /etc/security/limits.d/20-nproc.conf #设置elk用户参数 elk soft nproc 65536
es集群配置参数
vim /etc/elasticsearch cluster.name: aubin-cluster # 集群名称 node.name: els1 # 节点名称,仅仅是描述名称,用于在日志中区分 path.data: /var/lib/elasticsearch # 数据的默认存放路径 path.logs: /var/log/elasticsearch # 日志的默认存放路径 network.host: 192.168.0.1 # 当前节点的IP地址 http.port: 9200 # 对外提供服务的端口,9300为集群服务的端口 discovery.zen.ping.unicast.hosts: ["172.18.68.11", "172.18.68.12","172.18.68.13"] # 集群个节点IP地址,也可以使用els、els.shuaiguoxia.com等名称,需要各节点能够解析 discovery.zen.minimum_master_nodes: 2 # 为了避免脑裂,集群节点数最少为 半数+1
注意:集群所用的端口是9300防火墙要打开