1、git仓库的初始化:
输入git init指令,会看到在当前空目录下创建了一个.git隐藏文件夹,这个就是git实现一切版本管理的关键。
进入到.git目录下,里面包含三个文件(config/description/HEAD)和四个文件夹(hooks/info/objects/resf)
官方对各个文件和文件夹有详细的介绍:
- config:记录与本项目相关的配置信息
- descripton:是GitWeb项目对于本仓库的基本描述
- HEAD:内部记录了当前分支的最后一次提交(默认指向refs/heads/master文件)
- hooks:记录客户端和服务端的脚本,完成相关的自动化工作(钩子脚本的目的)
- info:记录全局的文件忽略方式,用于标记不被git仓库跟踪的文件,与.gitignore类似
- objects:这是git仓库的关键,归档所有git数据库里的内容
- refs:这个也是git仓库主要内容,记录所有分支的提交对象(commit object)
2、git存储第一阶段:缓冲区(index or staged)
初始化完成后,我们开始正常工作,创建一个测试文件test.txt,输入一行字符串。此时使用git status查看一下状态:
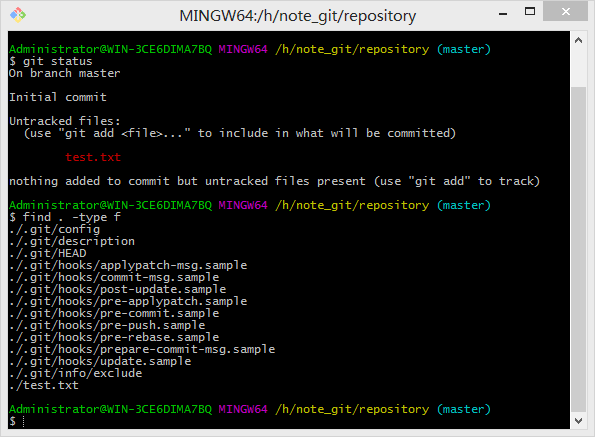
从上图可以看出test.txt文件还没进入到git仓库内部,处于untracked状态,.git文件夹与初始化时刻相同(使用find . -type f指令的运行结果可以看出),并未发生任何变化,所以git status之所以能够将untracked文件标记出来,是通过排除的方式,即.git仓库中没有记录的同级目录下的所有文件。
下面我们将新增的测试文件test.txt添加到缓冲区中,输入指令:
$git add test.txt
此刻再次运行git status和find . -type两条指令,得到的结果如下截图:
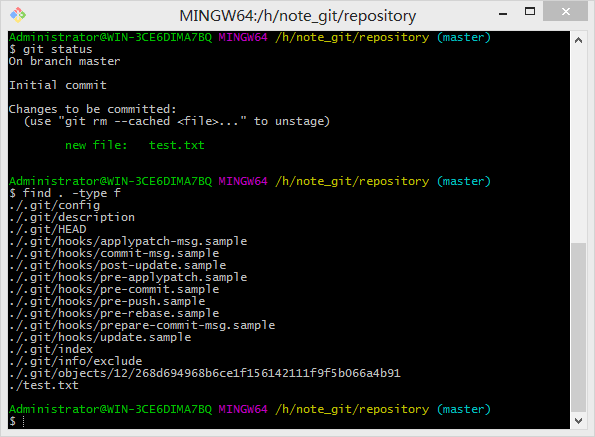
由此我们可以看出,git add指令执行成功后,test.txt文件已经被标记为staged状态(截图中的绿色标记)。此时可以看到在.git/objects目录下多出了一个文件12/268d69。这与上文介绍的objects目录的作用一致,用于存储所有git仓库数据库的内容,以文件的形式存储(因为git是一款基于内容检索的文件系统)。
这里我们可以使用官方给出的工具git cat-file查看一下多出来的这个文件存储的内容是啥?输入如下指令:
#cat指令本身在linux下就是显示文件内容的工具,谁让git的作者与linux是同一个大神呢 #-p是print的意思,用于直接将内容打印到stdout $git cat-file -p 12268d69
结果如下:

这正是我们缓冲区test.txt文件的内容。
由此我们可以对git如何管理和归档文件有一个宏观的认识,说到底就是:
一个基于内容检索的文件系统,Content-Basd Filesystem。我们常见的文件系统(NTFS、FAT、FAT32)是基于地址的方式来检索,即先给定具体的地址(32位或64位)然后从地址编号所对应的存储单元内部取出文件内容,而Content-Based Filesystem恰恰相反,是通过对文件整个内容进行运算,得到的结果才是一个真实的存储位置,类似于哈希映射,为了叙述方便,这里就简单的理解为哈希映射吧。
3、git存储第二阶段:提交(commit)
运行命令:
$git commit -m "add test.txt"
使用git status和find . -type f两条指令来看一下git仓库和当前目录的状态:
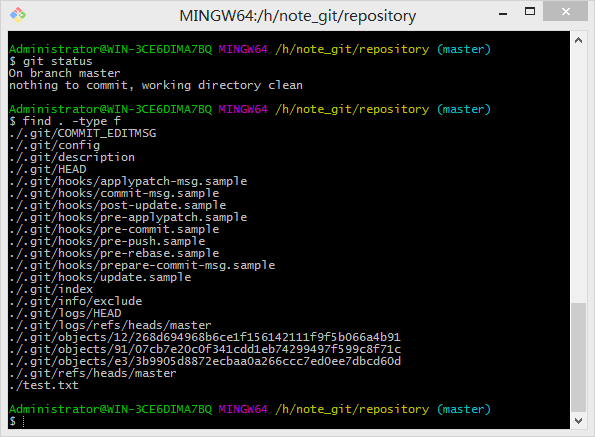
由上图可以看出,git commit成功后在git add基础上objects文件夹内又多出了两个文件,91/07cb7e和e3/3b9905(从文件的归档路径和命名方式可以看出git使用了SHA-1算法对文件内容进行了校验——即基于文件内容的哈希映射系统),使用git cat-file -t命令查看一下这两个文件的类型:
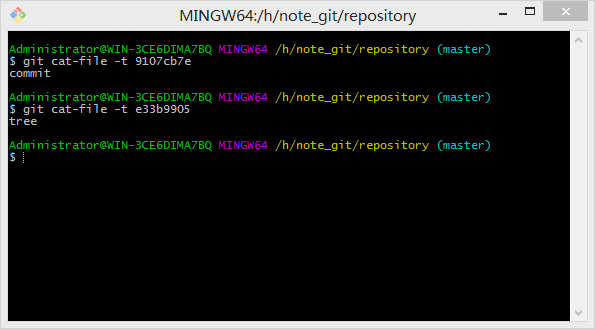
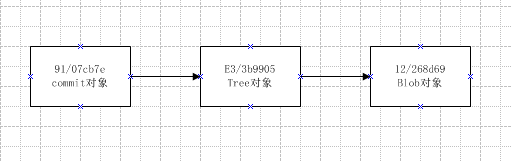
由此看出多出的两个文件,一个是commit对象,一个是tree对象。
再使用git cat-file -p命令查看这两个文件的内容:
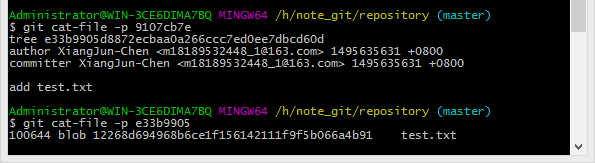
它们的关系是这样的:
91/07cb7e是一个commit对象,它的tree属性指向了tree对象e3/3b9905,它记录了文件操作,作者,提交者等信息
e3/3b9905是一个tree对象,它的blob属性指向了blob对象12/268d69,它记录了文件名
12/268d69是一个blob对象,它记录了文件内容