http://duartes.org/gustavo/blog/category/software-illustrated/page/2
Motherboard Chipsets and the Memory Map
I’m going to write a few posts about computer internals with the goal of explaining how modern kernels work. I hope to make them useful to enthusiasts and programmers who are interested in this stuff but don’t have experience with it. The focus is on Linux, Windows, and Intel processors. Internals are a hobby for me, I have written a fair bit of kernel-mode code but haven’t done so in a while. This first post describes the layout of modern Intel-based motherboards, how the CPU accesses memory and the system memory map.
To start off let’s take a look at how an Intel computer is wired up nowadays. The diagram below shows the main components in a motherboard and dubious color taste:
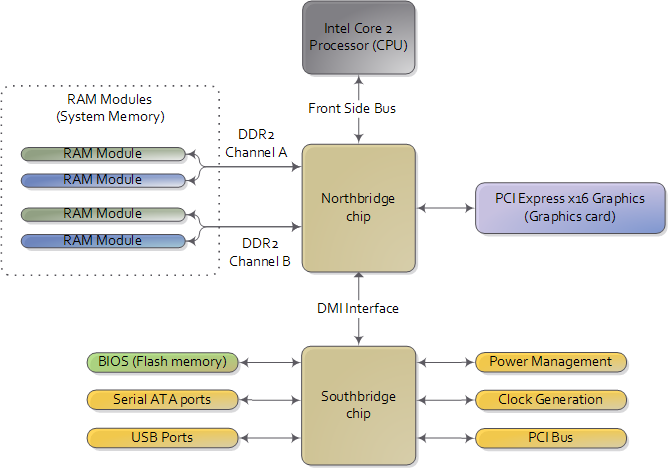
Diagram for modern motherboard. The northbridge and southbridge make up the chipset.
As you look at this, the crucial thing to keep in mind is that the CPU doesn’t really know anything about what it’s connected to. It talks to the outside world through its pins but it doesn’t care what that outside world is. It might be a motherboard in a computer but it could be a toaster, network router, brain implant, or CPU test bench. There are three main ways by which the CPU and the outside communicate: memory address space, I/O address space, and interrupts. We only worry about motherboards and memory for now.
{kind=link}
In a motherboard the CPU’s gateway to the world is the front-side bus connecting it to the northbridge. Whenever the CPU needs to read or write memory it does so via this bus. It uses some pins to transmit the physical memory address it wants to write or read, while other pins send the value to be written or receive the value being read. An Intel Core 2 QX6600 has 33 pins to transmit the physical memory address (so there are 233 choices of memory locations) and 64 pins to send or receive data (so data is transmitted in a 64-bit data path, or 8-byte chunks). This allows the CPU to physically address 64 gigabytes of memory (233 locations * 8 bytes) although most chipsets only handle up to 8 gigs of RAM.
Now comes the rub. We’re used to thinking of memory only in terms of RAM, the stuff programs read from and write to all the time. And indeed most of the memory requests from the processor are routed to RAM modules by the northbridge. But not all of them. Physical memory addresses are also used for communication with assorted devices on the motherboard (this communication is calledmemory-mapped I/O). These devices include video cards, most PCI cards (say, a scanner or SCSI card), and also the flash memory that stores the BIOS.
When the northbridge receives a physical memory request it decides where to route it: should it go to RAM? Video card maybe? This routing is decided via the memory address map. For each region of physical memory addresses, the memory map knows the device that owns that region. The bulk of the addresses are mapped to RAM, but when they aren’t the memory map tells the chipset which device should service requests for those addresses. This mapping of memory addresses away from RAM modules causes the classic hole in PC memory between 640KB and 1MB. A bigger hole arises when memory addresses are reserved for video cards and PCI devices. This is why 32-bit OSes haveproblems using 4 gigs of RAM. In Linux the file /proc/iomem neatly lists these address range mappings. The diagram below shows a typical memory map for the first 4 gigs of physical memory addresses in an Intel PC:
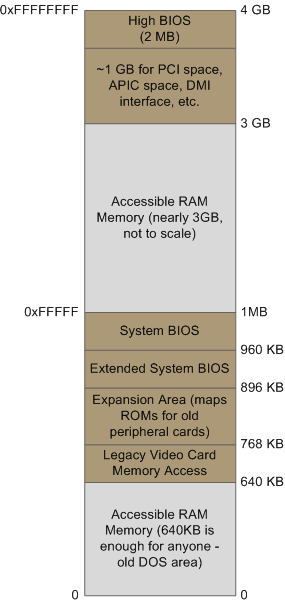
Memory layout for the first 4 gigabytes in an Intel system.
Actual addresses and ranges depend on the specific motherboard and devices present in the computer, but most Core 2 systems are pretty close to the above. All of the brown regions are mapped away from RAM. Remember that these are physical addresses that are used on the motherboard buses. Inside the CPU (for example, in the programs we run and write), the memory addresses are logical and they must be translated by the CPU into a physical address before memory is accessed on the bus.
The rules for translation of logical addresses into physical addresses are complex and they depend on the mode in which the CPU is running (real mode, 32-bit protected mode, and 64-bit protected mode). Regardless of the translation mechanism, the CPU mode determines how much physical memory can be accessed. For example, if the CPU is running in 32-bit mode, then it is only capable of physically addressing 4 GB (well, there is an exception called physical address extension, but ignore it for now). Since the top 1 GB or so of physical addresses are mapped to motherboard devices the CPU can effectively use only ~3 GB of RAM (sometimes less – I have a Vista machine where only 2.4 GB are usable). If the CPU is in real mode, then it can only address 1 megabyte of physical RAM (this is the only mode early Intel processors were capable of). On the other hand, a CPU running in 64-bit mode can physically access 64GB (few chipsets support that much RAM though). In 64-bit mode it is possible to use physical addresses above the total RAM in the system to access the RAM regions that correspond to physical addresses stolen by motherboard devices. This is called reclaiming memory and it’s done with help from the chipset.
That’s all the memory we need for the next post, which describes the boot process from power up until the boot loader is about to jump into the kernel. If you’d like to learn more about this stuff, I highly recommend the Intel manuals. I’m big into primary sources overall, but the Intel manuals in particular are well written and accurate. Here are some:
- Datasheet for Intel G35 Chipset documents a representative chipset for Core 2 processors. This is the main source for this post.
- Datasheet for Intel Core 2 Quad-Core Q6000 Sequence is a processor datasheet. It documents each pin in the processor (there aren’t that many actually, and after you group them there’s really not a lot to it). Fascinating stuff, though some bits are arcane.
- The Intel Software Developer’s Manuals are outstanding. Far from arcane, they explain beautifully all sorts of things about the architecture. Volumes 1 and 3A have the good stuff (don’t be put off by the name, the “volumes” are small and you can read selectively).
- Pádraig Brady suggested that I link to Ulrich Drepper’s excellent paper on memory. It’s great stuff. I was waiting to link to it in a post about memory, but the more the merrier.
How Computers Boot Up
The previous post described motherboards and the memory map in Intel computers to set the scene for the initial phases of boot. Booting is an involved, hacky, multi-stage affair – fun stuff. Here’s an outline of the process:
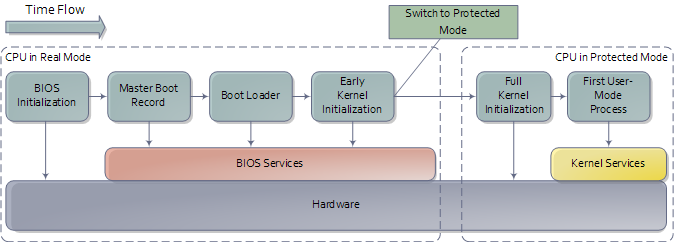
An outline of the boot sequence
Things start rolling when you press the power button on the computer (no! do tell!). Once the motherboard is powered up it initializes its own firmware – the chipset and other tidbits – and tries to get the CPU running. If things fail at this point (e.g., the CPU is busted or missing) then you will likely have a system that looks completely dead except for rotating fans. A few motherboards manage to emit beeps for an absent or faulty CPU, but the zombie-with-fans state is the most common scenario based on my experience. Sometimes USB or other devices can cause this to happen: unplugging allnon-essential devices is a possible cure for a system that was working and suddenly appears dead like this. You can then single out the culprit device by elimination.
If all is well the CPU starts running. In a multi-processor or multi-core system one CPU is dynamically chosen to be the bootstrap processor (BSP) that runs all of the BIOS and kernel initialization code. The remaining processors, called application processors (AP) at this point, remain halted until later on when they are explicitly activated by the kernel. Intel CPUs have been evolving over the years but they’re fully backwards compatible, so modern CPUs can behave like the original 1978 Intel 8086, which is exactly what they do after power up. In this primitive power up state the processor is in real mode with memory paging disabled. This is like ancient MS-DOS where only 1 MB of memory can be addressed and any code can write to any place in memory – there’s no notion of protection or privilege.
Most registers in the CPU have well-defined values after power up, including the instruction pointer (EIP) which holds the memory address for the instruction being executed by the CPU. Intel CPUs use a hack whereby even though only 1MB of memory can be addressed at power up, a hidden base address (an offset, essentially) is applied to EIP so that the first instruction executed is at address 0xFFFFFFF0 (16 bytes short of the end of 4 gigs of memory and well above one megabyte). This magical address is called the reset vector and is standard for modern Intel CPUs.
The motherboard ensures that the instruction at the reset vector is a jump to the memory location mapped to the BIOS entry point. This jump implicitly clears the hidden base address present at power up. All of these memory locations have the right contents needed by the CPU thanks to the memory map kept by the chipset. They are all mapped to flash memory containing the BIOS since at this point the RAM modules have random crap in them. An example of the relevant memory regions is shown below:

Important memory regions during boot
The CPU then starts executing BIOS code, which initializes some of the hardware in the machine. Afterwards the BIOS kicks off the Power-on Self Test (POST) which tests various components in the computer. Lack of a working video card fails the POST and causes the BIOS to halt and emit beeps to let you know what’s wrong, since messages on the screen aren’t an option. A working video card takes us to a stage where the computer looks alive: manufacturer logos are printed, memory starts to be tested, angels blare their horns. Other POST failures, like a missing keyboard, lead to halts with an error message on the screen. The POST involves a mixture of testing and initialization, including sorting out all the resources – interrupts, memory ranges, I/O ports – for PCI devices. Modern BIOSes that follow the Advanced Configuration and Power Interface build a number of data tables that describe the devices in the computer; these tables are later used by the kernel.
After the POST the BIOS wants to boot up an operating system, which must be found somewhere: hard drives, CD-ROM drives, floppy disks, etc. The actual order in which the BIOS seeks a boot device is user configurable. If there is no suitable boot device the BIOS halts with a complaint like “Non-System Disk or Disk Error.” A dead hard drive might present with this symptom. Hopefully this doesn’t happen and the BIOS finds a working disk allowing the boot to proceed.
The BIOS now reads the first 512-byte sector (sector zero) of the hard disk. This is called the Master Boot Record and it normally contains two vital components: a tiny OS-specific bootstrapping program at the start of the MBR followed by a partition table for the disk. The BIOS however does not care about any of this: it simply loads the contents of the MBR into memory location 0x7c00 and jumps to that location to start executing whatever code is in the MBR.
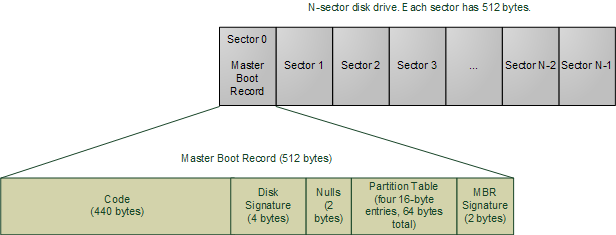
Master Boot Record
The specific code in the MBR could be a Windows MBR loader, code from Linux loaders such as LILO or GRUB, or even a virus. In contrast the partition table is standardized: it is a 64-byte area with four 16-byte entries describing how the disk has been divided up (so you can run multiple operating systems or have separate volumes in the same disk). Traditionally Microsoft MBR code takes a look at the partition table, finds the (only) partition marked as active, loads the boot sector for thatpartition, and runs that code. The boot sector is the first sector of a partition, as opposed to the first sector for the whole disk. If something is wrong with the partition table you would get messages like “Invalid Partition Table” or “Missing Operating System.” This message does not come from the BIOS but rather from the MBR code loaded from disk. Thus the specific message depends on the MBR flavor.
Boot loading has gotten more sophisticated and flexible over time. The Linux boot loaders Lilo and GRUB can handle a wide variety of operating systems, file systems, and boot configurations. Their MBR code does not necessarily follow the “boot the active partition” approach described above. But functionally the process goes like this:
- The MBR itself contains the first stage of the boot loader. GRUB calls this stage 1.
- Due to its tiny size, the code in the MBR does just enough to load another sector from disk that contains additional boostrap code. This sector might be the boot sector for a partition, but could also be a sector that was hard-coded into the MBR code when the MBR was installed.
- The MBR code plus code loaded in step 2 then read a file containing the second stage of the boot loader. In GRUB this is GRUB Stage 2, and in Windows Server this is c:\NTLDR. If step 2 fails in Windows you’d get a message like “NTLDR is missing”. The stage 2 code then reads a boot configuration file (e.g., grub.conf in GRUB, boot.ini in Windows). It then presents boot choices to the user or simply goes ahead in a single-boot system.
- At this point the boot loader code needs to fire up a kernel. It must know enough about file systems to read the kernel from the boot partition. In Linux this means reading a file like “vmlinuz-2.6.22-14-server” containing the kernel, loading the file into memory and jumping to the kernel bootstrap code. In Windows Server 2003 some of the kernel start-up code is separate from the kernel image itself and is actually embedded into NTLDR. After performing several initializations, NTDLR loads the kernel image from file c:\Windows\System32\ntoskrnl.exe and, just as GRUB does, jumps to the kernel entry point.
There’s a complication worth mentioning (aka, I told you this thing is hacky). The image for a current Linux kernel, even compressed, does not fit into the 640K of RAM available in real mode. My vanilla Ubuntu kernel is 1.7 MB compressed. Yet the boot loader must run in real mode in order to call the BIOS routines for reading from the disk, since the kernel is clearly not available at that point. The solution is the venerable unreal mode. This is not a true processor mode (I wish the engineers at Intel were allowed to have fun like that), but rather a technique where a program switches back and forth between real mode and protected mode in order to access memory above 1MB while still using the BIOS. If you read GRUB source code, you’ll see these transitions all over the place (look under stage2/ for calls to real_to_prot and prot_to_real). At the end of this sticky process the loader has stuffed the kernel in memory, by hook or by crook, but it leaves the processor in real mode when it’s done.
We’re now at the jump from “Boot Loader” to “Early Kernel Initialization” as shown in the first diagram. That’s when things heat up as the kernel starts to unfold and set things in motion. The next post will be a guided tour through the Linux Kernel initialization with links to sources at the Linux Cross Reference. I can’t do the same for Windows ![]() but I’ll point out the highlights.
but I’ll point out the highlights.
The Kernel Boot Process
The previous post explained how computers boot up right up to the point where the boot loader, after stuffing the kernel image into memory, is about to jump into the kernel entry point. This last post about booting takes a look at the guts of the kernel to see how an operating system starts life. Since I have an empirical bent I’ll link heavily to the sources for Linux kernel 2.6.25.6 at the Linux Cross Reference. The sources are very readable if you are familiar with C-like syntax; even if you miss some details you can get the gist of what’s happening. The main obstacle is the lack of context around some of the code, such as when or why it runs or the underlying features of the machine. I hope to provide a bit of that context. Due to brevity (hah!) a lot of fun stuff – like interrupts and memory – gets only a nod for now. The post ends with the highlights for the Windows boot.
At this point in the Intel x86 boot story the processor is running in real-mode, is able to address 1 MB of memory, and RAM looks like this for a modern Linux system:
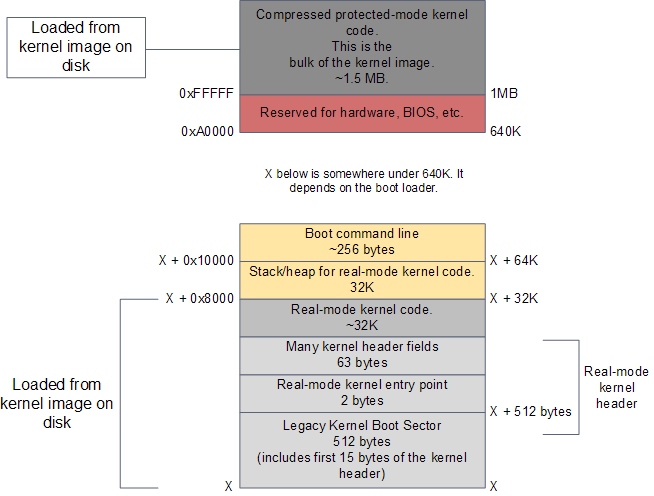
RAM contents after boot loader is done
The kernel image has been loaded to memory by the boot loader using the BIOS disk I/O services. This image is an exact copy of the file in your hard drive that contains the kernel, e.g./boot/vmlinuz-2.6.22-14-server. The image is split into two pieces: a small part containing the real-mode kernel code is loaded below the 640K barrier; the bulk of the kernel, which runs in protected mode, is loaded after the first megabyte of memory.
The action starts in the real-mode kernel header pictured above. This region of memory is used to implement the Linux boot protocol between the boot loader and the kernel. Some of the values there are read by the boot loader while doing its work. These include amenities such as a human-readable string containing the kernel version, but also crucial information like the size of the real-mode kernel piece. The boot loader also writes values to this region, such as the memory address for the command-line parameters given by the user in the boot menu. Once the boot loader is finished it has filled in all of the parameters required by the kernel header. It’s then time to jump into the kernel entry point. The diagram below shows the code sequence for the kernel initialization, along with source directories, files, and line numbers:
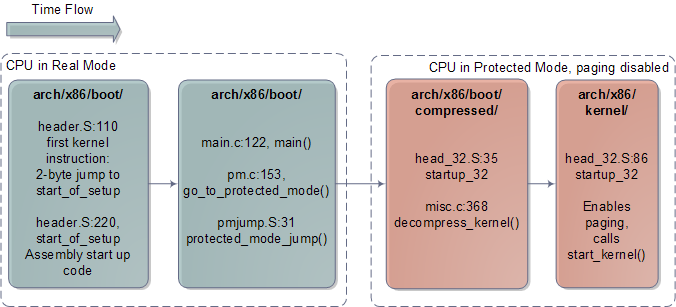
Architecture-specific Linux Kernel Initialization
The early kernel start-up for the Intel architecture is in file arch/x86/boot/header.S. It’s in assembly language, which is rare for the kernel at large but common for boot code. The start of this file actually contains boot sector code, a left over from the days when Linux could work without a boot loader. Nowadays this boot sector, if executed, only prints a “bugger_off_msg” to the user and reboots. Modern boot loaders ignore this legacy code. After the boot sector code we have the first 15 bytes of the real-mode kernel header; these two pieces together add up to 512 bytes, the size of a typical disk sector on Intel hardware.
After these 512 bytes, at offset 0×200, we find the very first instruction that runs as part of the Linux kernel: the real-mode entry point. It’s in header.S:110 and it is a 2-byte jump written directly in machine code as 0x3aeb. You can verify this by running hexdump on your kernel image and seeing the bytes at that offset – just a sanity check to make sure it’s not all a dream. The boot loader jumps into this location when it is finished, which in turn jumps to header.S:229 where we have a regular assembly routine called start_of_setup. This short routine sets up a stack, zeroes the bss segment (the area that contains static variables, so they start with zero values) for the real-mode kernel and then jumps to good old C code at arch/x86/boot/main.c:122.
main() does some house keeping like detecting memory layout, setting a video mode, etc. It then calls go_to_protected_mode(). Before the CPU can be set to protected mode, however, a few tasks must be done. There are two main issues: interrupts and memory. In real-mode the interrupt vector table for the processor is always at memory address 0, whereas in protected mode the location of the interrupt vector table is stored in a CPU register called IDTR. Meanwhile, the translation of logical memory addresses (the ones programs manipulate) to linear memory addresses (a raw number from 0 to the top of the memory) is different between real-mode and protected mode. Protected mode requires a register called GDTR to be loaded with the address of a Global Descriptor Table for memory. So go_to_protected_mode() calls setup_idt() and setup_gdt() to install a temporary interrupt descriptor table and global descriptor table.
We’re now ready for the plunge into protected mode, which is done by protected_mode_jump, another assembly routine. This routine enables protected mode by setting the PE bit in the CR0 CPU register. At this point we’re running with paging disabled; paging is an optional feature of the processor, even in protected mode, and there’s no need for it yet. What’s important is that we’re no longer confined to the 640K barrier and can now address up to 4GB of RAM. The routine then calls the 32-bit kernel entry point, which is startup_32 for compressed kernels. This routine does some basic register initializations and calls decompress_kernel(), a C function to do the actual decompression.
decompress_kernel() prints the familiar “Decompressing Linux…” message. Decompression happens in-place and once it’s finished the uncompressed kernel image has overwritten the compressed one pictured in the first diagram. Hence the uncompressed contents also start at 1MB. decompress_kernel() then prints “done.” and the comforting “Booting the kernel.” By “Booting” it means a jump to the final entry point in this whole story, given to Linus by God himself atop Mountain Halti, which is the protected-mode kernel entry point at the start of the second megabyte of RAM (0×100000). That sacred location contains a routine called, uh, startup_32. But this one is in a different directory, you see.
The second incarnation of startup_32 is also an assembly routine, but it contains 32-bit mode initializations. It clears the bss segment for the protected-mode kernel (which is the true kernel that will now run until the machine reboots or shuts down), sets up the final global descriptor table for memory, builds page tables so that paging can be turned on, enables paging, initializes a stack, creates the final interrupt descriptor table, and finally jumps to to the architecture-independent kernel start-up, start_kernel(). The diagram below shows the code flow for the last leg of the boot:
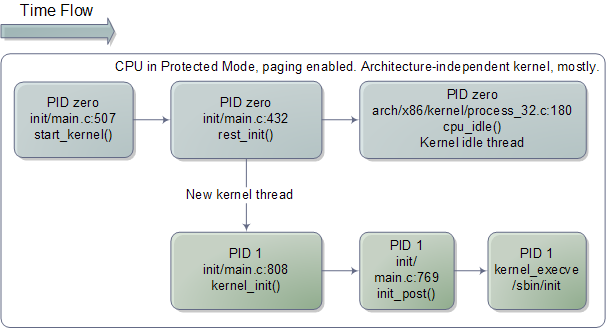
Architecture-independent Linux Kernel Initialization
start_kernel() looks more like typical kernel code, which is nearly all C and machine independent. The function is a long list of calls to initializations of the various kernel subsystems and data structures. These include the scheduler, memory zones, time keeping, and so on. start_kernel() then callsrest_init(), at which point things are almost all working. rest_init() creates a kernel thread passing another function, kernel_init(), as the entry point. rest_init() then calls schedule() to kickstart task scheduling and goes to sleep by calling cpu_idle(), which is the idle thread for the Linux kernel. cpu_idle() runs forever and so does process zero, which hosts it. Whenever there is work to do – a runnable process – process zero gets booted out of the CPU, only to return when no runnable processes are available.
But here’s the kicker for us. This idle loop is the end of the long thread we followed since boot, it’s the final descendent of the very first jump executed by the processor after power up. All of this mess, from reset vector to BIOS to MBR to boot loader to real-mode kernel to protected-mode kernel, all of it leads right here, jump by jump by jump it ends in the idle loop for the boot processor, cpu_idle(). Which is really kind of cool. However, this can’t be the whole story otherwise the computer would do no work.
At this point, the kernel thread started previously is ready to kick in, displacing process 0 and its idle thread. And so it does, at which point kernel_init() starts running since it was given as the thread entry point. kernel_init() is responsible for initializing the remaining CPUs in the system, which have been halted since boot. All of the code we’ve seen so far has been executed in a single CPU, called the boot processor. As the other CPUs, called application processors, are started they come up in real-mode and must run through several initializations as well. Many of the code paths are common, as you can see in the code for startup_32, but there are slight forks taken by the late-coming application processors. Finally, kernel_init() calls init_post(), which tries to execute a user-mode process in the following order: /sbin/init, /etc/init, /bin/init, and /bin/sh. If all fail, the kernel will panic. Luckily init is usually there, and starts running as PID 1. It checks its configuration file to figure out which processes to launch, which might include X11 Windows, programs for logging in on the console, network daemons, and so on. Thus ends the boot process as yet another Linux box starts running somewhere. May your uptime be long and untroubled.
The process for Windows is similar in many ways, given the common architecture. Many of the same problems are faced and similar initializations must be done. When it comes to boot one of the biggest differences is that Windows packs all of the real-mode kernel code, and some of the initial protected mode code, into the boot loader itself (C:\NTLDR). So instead of having two regions in the same kernel image, Windows uses different binary images. Plus Linux completely separates boot loader and kernel; in a way this automatically falls out of the open source process. The diagram below shows the main bits for the Windows kernel:
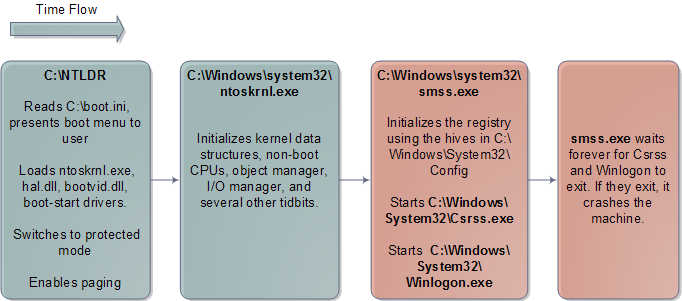
Windows Kernel Initialization
The Windows user-mode start-up is naturally very different. There’s no /sbin/init, but rather Csrss.exe and Winlogon.exe. Winlogon spawns Services.exe, which starts all of the Windows Services, and Lsass.exe, the local security authentication subsystem. The classic Windows login dialog runs in the context of Winlogon.
This is the end of this boot series. Thanks everyone for reading and for feedback. I’m sorry some things got superficial treatment; I’ve gotta start somewhere and only so much fits into blog-sized bites. But nothing like a day after the next; my plan is to do regular “Software Illustrated” posts like this series along with other topics. Meanwhile, here are some resources:
- The best, most important resource, is source code for real kernels, either Linux or one of the BSDs.
- Intel publishes excellent Software Developer’s Manuals, which you can download for free.
- Understanding the Linux Kernel is a good book and walks through a lot of the Linux Kernel sources. It’s getting outdated and it’s dry, but I’d still recommend it to anyone who wants to grok the kernel. Linux Device Drivers is more fun, teaches well, but is limited in scope. Finally, Patrick Moroney suggested Linux Kernel Development by Robert Love in the comments for this post. I’ve heard other positive reviews for that book, so it sounds worth checking out.
- For Windows, the best reference by far is Windows Internals by David Solomon and Mark Russinovich, the latter of Sysinternals fame. This is a great book, well-written and thorough. The main downside is the lack of source code.
[Update: In a comment below, Nix covered a lot of ground on the initial root file system that I glossed over. Thanks to Marius Barbu for catching a mistake where I wrote "CR3" instead of GDTR]
Memory Translation and Segmentation
This post is the first in a series about memory and protection in Intel-compatible (x86) computers, going further down the path of how kernels work. As in the boot series, I’ll link to Linux kernel sources but give Windows examples as well (sorry, I’m ignorant about the BSDs and the Mac, but most of the discussion applies). Let me know what I screw up.
In the chipsets that power Intel motherboards, memory is accessed by the CPU via the front side bus, which connects it to the northbridge chip. The memory addresses exchanged in the front side bus are physical memory addresses, raw numbers from zero to the top of the available physical memory. These numbers are mapped to physical RAM sticks by the northbridge. Physical addresses are concrete and final – no translation, no paging, no privilege checks – you put them on the bus and that’s that. Within the CPU, however, programs use logical memory addresses, which must be translated into physical addresses before memory access can take place. Conceptually address translation looks like this:
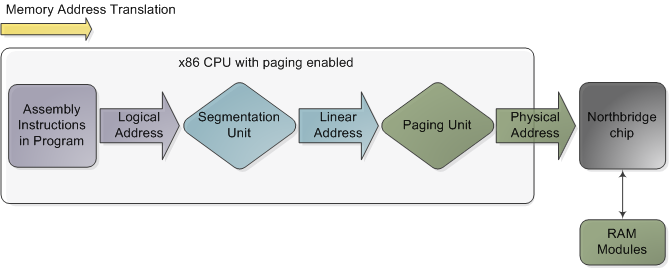
Memory address translation in x86 CPUs with paging enabled
This is not a physical diagram, only a depiction of the address translation process, specifically for when the CPU has paging enabled. If you turn off paging, the output from the segmentation unit is already a physical address; in 16-bit real mode that is always the case. Translation starts when the CPU executes an instruction that refers to a memory address. The first step is translating that logic address into a linear address. But why go through this step instead of having software use linear (or physical) addresses directly? For roughly the same reason humans have an appendix whose primary function is getting infected. It’s a wrinkle of evolution. To really make sense of x86 segmentation we need to go back to 1978.
The original 8086 had 16-bit registers and its instructions used mostly 8-bit or 16-bit operands. This allowed code to work with 216 bytes, or 64K of memory, yet Intel engineers were keen on letting the CPU use more memory without expanding the size of registers and instructions. So they introducedsegment registers as a means to tell the CPU which 64K chunk of memory a program’s instructions were going to work on. It was a reasonable solution: first you load a segment register, effectively saying “here, I want to work on the memory chunk starting at X”; afterwards, 16-bit memory addresses used by your code are interpreted as offsets into your chunk, or segment. There were four segment registers: one for the stack (ss), one for program code (cs), and two for data (ds, es). Most programs were small enough back then to fit their whole stack, code, and data each in a 64K segment, so segmentation was often transparent.
Nowadays segmentation is still present and is always enabled in x86 processors. Each instruction that touches memory implicitly uses a segment register. For example, a jump instruction uses the code segment register (cs) whereas a stack push instruction uses the stack segment register (ss). In most cases you can explicitly override the segment register used by an instruction. Segment registers store 16-bit segment selectors; they can be loaded directly with instructions like MOV. The sole exception is cs, which can only be changed by instructions that affect the flow of execution, like CALL or JMP. Though segmentation is always on, it works differently in real mode versus protected mode.
In real mode, such as during early boot, the segment selector is a 16-bit number specifying the physical memory address for the start of a segment. This number must somehow be scaled, otherwise it would also be limited to 64K, defeating the purpose of segmentation. For example, the CPU could use the segment selector as the 16 most significant bits of the physical memory address (by shifting it 16 bits to the left, which is equivalent to multiplying by 216). This simple rule would enable segments to address 4 gigs of memory in 64K chunks, but it would increase chip packaging costs by requiring more physical address pins in the processor. So Intel made the decision to multiply the segment selector by only 24 (or 16), which in a single stroke confined memory to about 1MB and unduly complicated translation. Here’s an example showing a jump instruction where cs contains 0×1000:
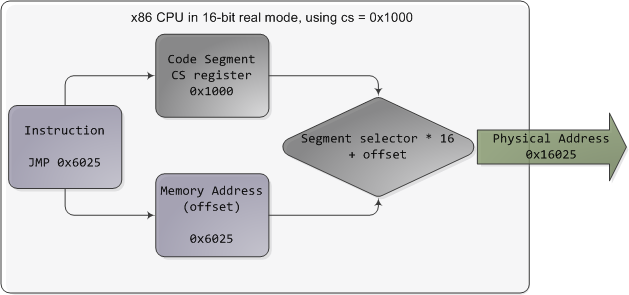
Real mode segmentation
Real mode segment starts range from 0 all the way to 0xFFFF0 (16 bytes short of 1 MB) in 16-byte increments. To these values you add a 16-bit offset (the logical address) between 0 and 0xFFFF. Itfollows that there are multiple segment/offset combinations pointing to the same memory location, and physical addresses fall above 1MB if your segment is high enough (see the infamous A20 line). Also, when writing C code in real mode a far pointer is a pointer that contains both the segment selector and the logical address, which allows it to address 1MB of memory. Far indeed. As programs started getting bigger and outgrowing 64K segments, segmentation and its strange ways complicated development for the x86 platform. This may all sound quaintly odd now but it has driven programmers into the wretched depths of madness.
In 32-bit protected mode, a segment selector is no longer a raw number, but instead it contains an index into a table of segment descriptors. The table is simply an array containing 8-byte records, where each record describes one segment and looks thus:

Segment descriptor
There are three types of segments: code, data, and system. For brevity, only the common features in the descriptor are shown here. The base address is a 32-bit linear address pointing to the beginning of the segment, while the limit specifies how big the segment is. Adding the base address to a logical memory address yields a linear address. DPL is the descriptor privilege level; it is a number from 0 (most privileged, kernel mode) to 3 (least privileged, user mode) that controls access to the segment.
These segment descriptors are stored in two tables: the Global Descriptor Table (GDT) and theLocal Descriptor Table (LDT). Each CPU (or core) in a computer contains a register called gdtrwhich stores the linear memory address of the first byte in the GDT. To choose a segment, you must load a segment register with a segment selector in the following format:

Segment Selector
The TI bit is 0 for the GDT and 1 for the LDT, while the index specifies the desired segment selector within the table. We’ll deal with RPL, Requested Privilege Level, later on. Now, come to think of it, when the CPU is in 32-bit mode registers and instructions can address the entire linear address spaceanyway, so there’s really no need to give them a push with a base address or other shenanigan. So why not set the base address to zero and let logical addresses coincide with linear addresses? Intel docs call this “flat model” and it’s exactly what modern x86 kernels do (they use the basic flat model, specifically). Basic flat model is equivalent to disabling segmentation when it comes to translating memory addresses. So in all its glory, here’s the jump example running in 32-bit protected mode, with real-world values for a Linux user-mode app:
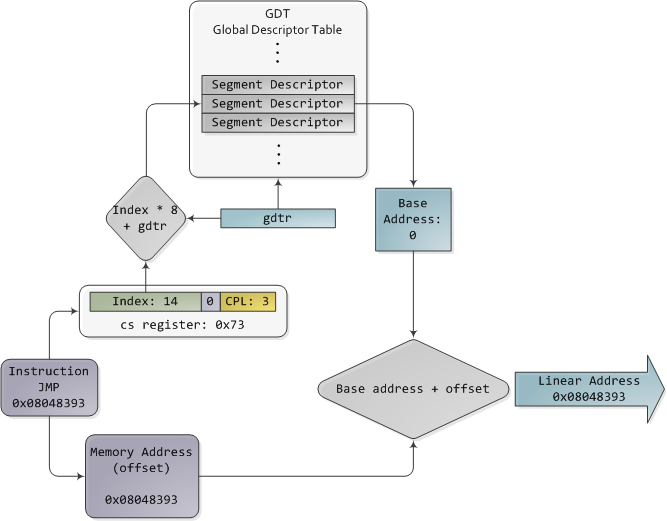
Protected Mode Segmentation
The contents of a segment descriptor are cached once they are accessed, so there’s no need to actually read the GDT in subsequent accesses, which would kill performance. Each segment register has a hidden part to store the cached descriptor that corresponds to its segment selector. For more details, including more info on the LDT, see chapter 3 of the Intel System Programming Guide Volume 3a. Volumes 2a and 2b, which cover every x86 instruction, also shed light on the various types of x86 addressing operands – 16-bit, 16-bit with segment selector (which can be used by far pointers), 32-bit, etc.
In Linux, only 3 segment descriptors are used during boot. They are defined with the GDT_ENTRYmacro and stored in the boot_gdt array. Two of the segments are flat, addressing the entire 32-bit space: a code segment loaded into cs and a data segment loaded into the other segment registers. The third segment is a system segment called the Task State Segment. After boot, each CPU has its own copy of the GDT. They are all nearly identical, but a few entries change depending on the running process. You can see the layout of the Linux GDT in segment.h and its instantiation is here. There are four primary GDT entries: two flat ones for code and data in kernel mode, and another two for user mode. When looking at the Linux GDT, notice the holes inserted on purpose to align data with CPU cache lines – an artifact of the von Neumann bottleneck that has become a plague. Finally, the classic “Segmentation fault” Unix error message is not due to x86-style segments, but rather invalid memory addresses normally detected by the paging unit – alas, topic for an upcoming post.
Intel deftly worked around their original segmentation kludge, offering a flexible way for us to choose whether to segment or go flat. Since coinciding logical and linear addresses are simpler to handle, they became standard, such that 64-bit mode now enforces a flat linear address space. But even in flat mode segments are still crucial for x86 protection, the mechanism that defends the kernel from user-mode processes and every process from each other. It’s a dog eat dog world out there! In the next post, we’ll take a peek at protection levels and how segments implement them.
Cache: a place for concealment and safekeeping
This post shows briefly how CPU caches are organized in modern Intel processors. Cache discussions often lack concrete examples, obfuscating the simple concepts involved. Or maybe my pretty little head is slow. At any rate, here’s half the story on how a Core 2 L1 cache is accessed:
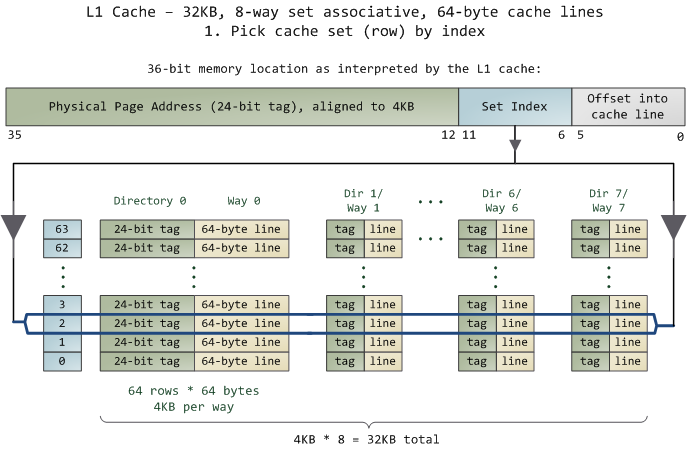
The unit of data in the cache is the line, which is just a contiguous chunk of bytes in memory. This cache uses 64-byte lines. The lines are stored in cache banks or ways, and each way has a dedicated directory to store its housekeeping information. You can imagine each way and its directory as columns in a spreadsheet, in which case the rows are the sets. Then each cell in the way column contains a cache line, tracked by the corresponding cell in the directory. This particular cache has 64 sets and 8 ways, hence 512 cells to store cache lines, which adds up to 32KB of space.
In this cache’s view of the world, physical memory is divided into 4KB physical pages. Each page has4KB / 64 bytes == 64 cache lines in it. When you look at a 4KB page, bytes 0 through 63 within that page are in the first cache line, bytes 64-127 in the second cache line, and so on. The pattern repeats for each page, so the 3rd line in page 0 is different than the 3rd line in page 1.
In a fully associative cache any line in memory can be stored in any of the cache cells. This makes storage flexible, but it becomes expensive to search for cells when accessing them. Since the L1 and L2 caches operate under tight constraints of power consumption, physical space, and speed, a fully associative cache is not a good trade off in most scenarios.
Instead, this cache is set associative, which means that a given line in memory can only be stored in one specific set (or row) shown above. So the first line of any physical page (bytes 0-63 within a page) must be stored in row 0, the second line in row 1, etc. Each row has 8 cells available to store the cache lines it is associated with, making this an 8-way associative set. When looking at a memory address, bits 11-6 determine the line number within the 4KB page and therefore the set to be used. For example, physical address 0x800010a0 has 000010 in those bits so it must be stored in set 2.
But we still have the problem of finding which cell in the row holds the data, if any. That’s where the directory comes in. Each cached line is tagged by its corresponding directory cell; the tag is simply the number for the page where the line came from. The processor can address 64GB of physical RAM, so there are 64GB / 4KB == 224 of these pages and thus we need 24 bits for our tag. Our example physical address 0x800010a0 corresponds to page number 524,289. Here’s the second half of the story:
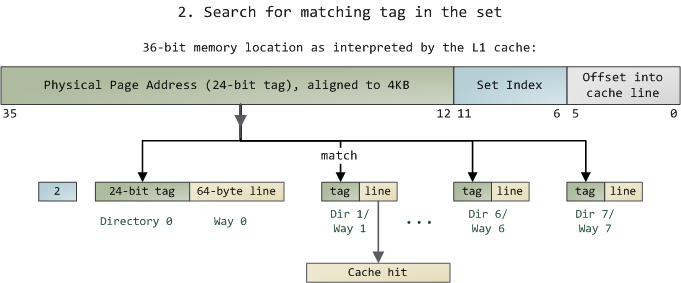
Since we only need to look in one set of 8 ways, the tag matching is very fast; in fact, electrically all tags are compared simultaneously, which I tried to show with the arrows. If there’s a valid cache line with a matching tag, we have a cache hit. Otherwise, the request is forwarded to the L2 cache, and failing that to main system memory. Intel builds large L2 caches by playing with the size and quantity of the ways, but the design is the same. For example, you could turn this into a 64KB cache by adding 8 more ways. Then increase the number of sets to 4096 and each way can store 256KB. These two modifications would deliver a 4MB L2 cache. In this scenario, you’d need 18 bits for the tags and 12 for the set index; the physical page size used by the cache is equal to its way size.
If a set fills up, then a cache line must be evicted before another one can be stored. To avoid this, performance-sensitive programs try to organize their data so that memory accesses are evenly spread among cache lines. For example, suppose a program has an array of 512-byte objects such that some objects are 4KB apart in memory. Fields in these objects fall into the same lines and compete for the same cache set. If the program frequently accesses a given field (e.g., the vtableby calling a virtual method), the set will likely fill up and the cache will start trashing as lines are repeatedly evicted and later reloaded. Our example L1 cache can only hold the vtables for 8 of these objects due to set size. This is the cost of the set associativity trade-off: we can get cache misses due to set conflicts even when overall cache usage is not heavy. However, due to the relative speeds in a computer, most apps don’t need to worry about this anyway.
A memory access usually starts with a linear (virtual) address, so the L1 cache relies on the paging unit to obtain the physical page address used for the cache tags. By contrast, the set index comes from the least significant bits of the linear address and is used without translation (bits 11-6 in our example). Hence the L1 cache is physically tagged but virtually indexed, helping the CPU to parallelize lookup operations. Because the L1 way is never bigger than an MMU page, a given physical memory location is guaranteed to be associated with the same set even with virtual indexing. L2 caches, on the other hand, must be physically tagged and physically indexed because their way size can be bigger than MMU pages. But then again, by the time a request gets to the L2 cache the physical address was already resolved by the L1 cache, so it works out nicely.
Finally, a directory cell also stores the state of its corresponding cached line. A line in the L1 code cache is either Invalid or Shared (which means valid, really). In the L1 data cache and the L2 cache, a line can be in any of the 4 MESI states: Modified, Exclusive, Shared, or Invalid. Intel caches areinclusive: the contents of the L1 cache are duplicated in the L2 cache. These states will play a part in later posts about threading, locking, and that kind of stuff. Next time we’ll look at the front side bus and how memory access really works. This is going to be memory week.
Update: Dave brought up direct-mapped caches in a comment below. They’re basically a special case of set-associative caches that have only one way. In the trade-off spectrum, they’re the opposite of fully associative caches: blazing fast access, lots of conflict misses.
Getting Physical With Memory
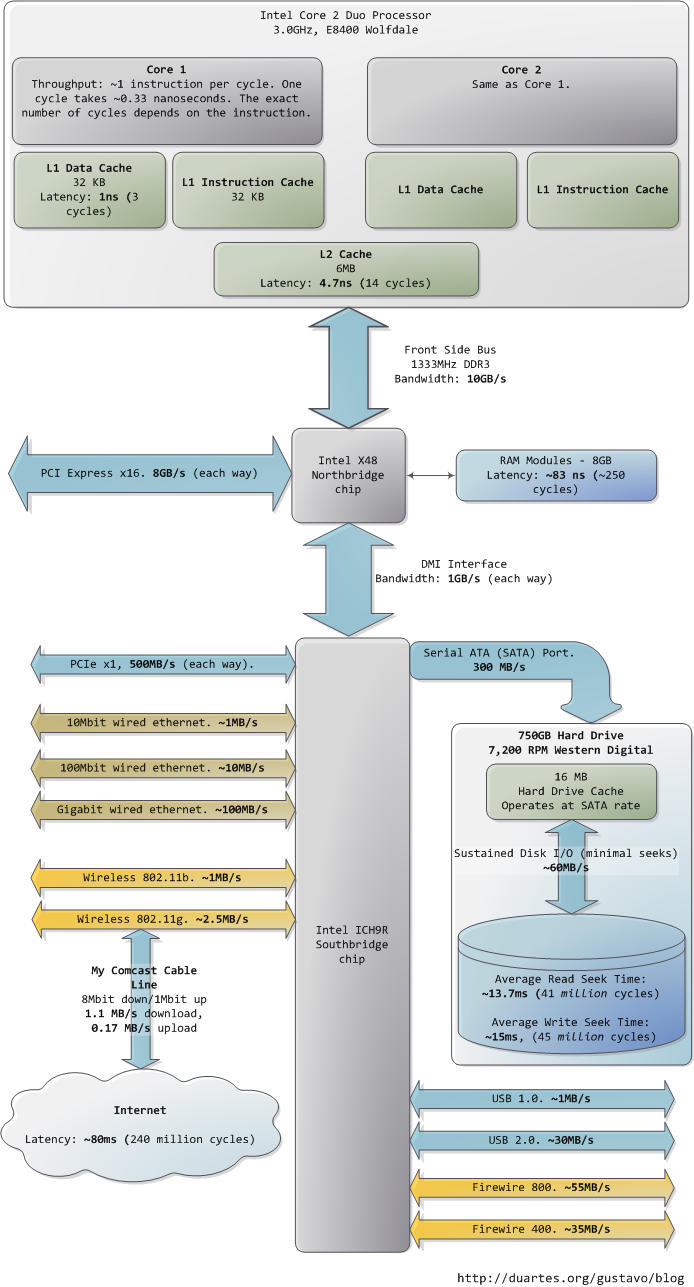
When trying to understand complex systems, you can often learn a lot by stripping away abstractions and looking at their lowest levels. In that spirit we take a look at memory and I/O ports in their simplest and most fundamental level: the interface between the processor and bus. These details underlie higher level topics like thread synchronization and the need for the Core i7. Also, since I’m a programmer I ignore things EE people care about. Here’s our friend the Core 2 again:
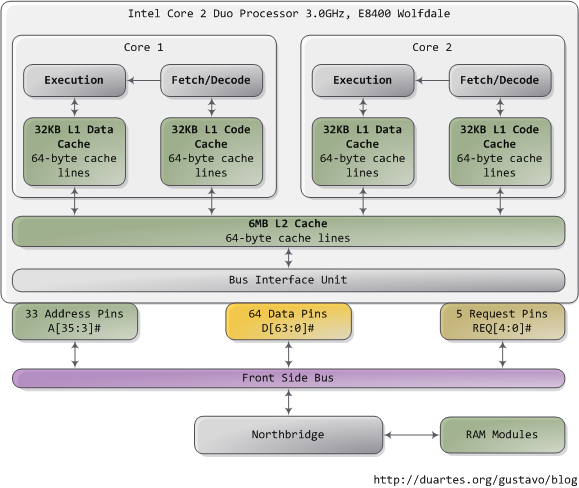
A Core 2 processor has 775 pins, about half of which only provide power and carry no data. Once you group the pins by functionality, the physical interface to the processor is surprisingly simple. The diagram shows the key pins involved in a memory or I/O port operation: address lines, data pins, and request pins. These operations take place in the context of a transaction on the front side bus. FSB transactions go through 5 phases: arbitration, request, snoop, response, and data. Throughout these phases, different roles are played by the components on the FSB, which are called agents. Normally the agents are all the processors plus the northbridge.
We only look at the request phase in this post, in which 2 packets are output by the request agent, who is usually a processor. Here are the juiciest bits of the first packet, output by the address and request pins:
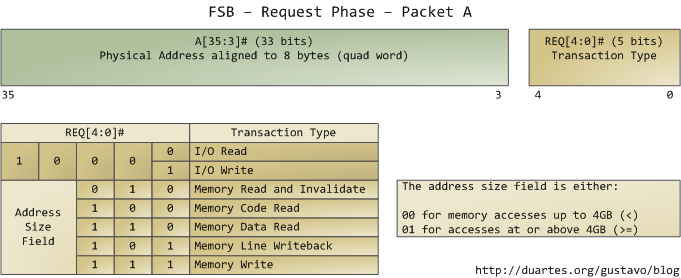
The address lines output the starting physical memory address for the transaction. We have 33 bits but they are interpreted as bits 35-3 of an address in which bits 2-0 are zero. Hence we have a 36-bit address, aligned to 8 bytes, for a total of 64GB addressable physical memory. This has been the case since the Pentium Pro. The request pins specify what type of transaction is being initiated; in I/O requests the address pins specify an I/O port rather than a memory address. After the first packet is output, the same pins transmit a second packet in the subsequent bus clock cycle:
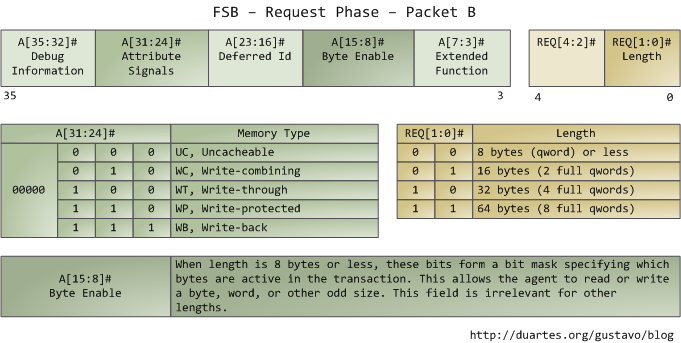
The attribute signals are interesting: they reflect the 5 types of memory caching behavior available in Intel processors. By putting this information on the FSB, the request agent lets other processors know how this transaction affects their caches, and how the memory controller (northbridge) should behave. The processor determines the type of a given memory region mainly by looking at page tables, which are maintained by the kernel.
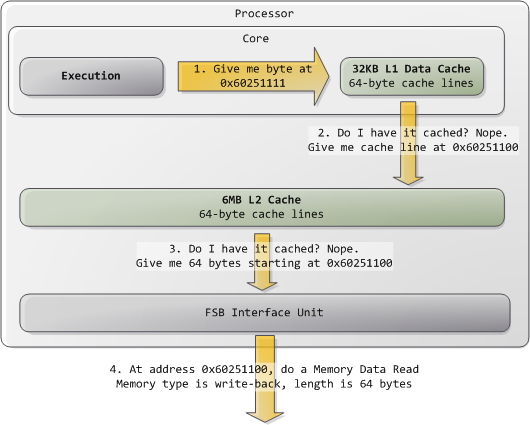
Typically kernels treat all RAM memory as write-back, which yields the best performance. In write-back mode the unit of memory access is the cache line, 64 bytes in the Core 2. If a program reads a single byte in memory, the processor loads the whole cache line that contains that byte into the L2 and L1 caches. When a program writes to memory, the processor only modifies the line in the cache, but does not update main memory. Later, when it becomes necessary to post the modified line to the bus, the whole cache line is written at once. So most requests have 11 in their length field, for 64 bytes. Here’s a read example in which the data is not in the caches:
Some of the physical memory range in an Intel computer is mapped to devices like hard drives and network cards instead of actual RAM memory. This allows drivers to communicate with their devices by writing to and reading from memory. The kernel marks these memory regions as uncacheable in the page tables. Accesses to uncacheable memory regions are reproduced in the bus exactly as requested by a program or driver. Hence it’s possible to read or write single bytes, words, and so on. This is done via the byte enable mask in packet B above.
The primitives discussed here have many implications. For example:
- Performance-sensitive applications should try to pack data that is accessed together into the same cache line. Once the cache line is loaded, further reads are much faster and extra RAM accesses are avoided.
- Any memory access that falls within a single cache line is guaranteed to be atomic (assuming write-back memory). Such an access is serviced by the processor’s L1 cache and the data is read or written all at once; it cannot be affected halfway by other processors or threads. In particular, 32-bit and 64-bit operations that don’t cross cache line boundaries are atomic.
- The front bus is shared by all agents, who must arbitrate for bus ownership before they can start a transaction. Moreover, all agents must listen to all transactions in order to maintain cache coherence. Thus bus contention becomes a severe problem as more cores and processors are added to Intel computers. The Core i7 solves this by having processors attached directly to memory and communicating in a point-to-point rather than broadcast fashion.
These are the highlights of physical memory requests; the bus will surface again later in connection with locking, multi-threading, and cache coherence. The first time I saw FSB packet descriptions I had a huge “ahhh!” moment so I hope someone out there gets the same benefit. In the next post we’ll go back up the abstraction ladder to take a thorough look at virtual memory.
Anatomy of a Program in Memory
Memory management is the heart of operating systems; it is crucial for both programming and system administration. In the next few posts I’ll cover memory with an eye towards practical aspects, but without shying away from internals. While the concepts are generic, examples are mostly from Linux and Windows on 32-bit x86. This first post describes how programs are laid out in memory.
Each process in a multi-tasking OS runs in its own memory sandbox. This sandbox is the virtual address space, which in 32-bit mode is always a 4GB block of memory addresses. These virtual addresses are mapped to physical memory by page tables, which are maintained by the operating system kernel and consulted by the processor. Each process has its own set of page tables, but there is a catch. Once virtual addresses are enabled, they apply to all software running in the machine, including the kernel itself. Thus a portion of the virtual address space must be reserved to the kernel:
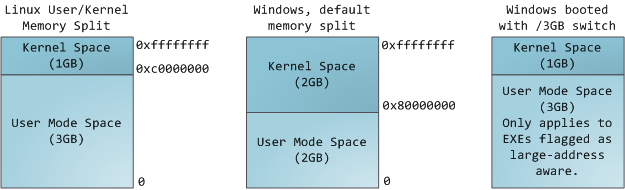
This does not mean the kernel uses that much physical memory, only that it has that portion of address space available to map whatever physical memory it wishes. Kernel space is flagged in the page tables as exclusive to privileged code (ring 2 or lower), hence a page fault is triggered if user-mode programs try to touch it. In Linux, kernel space is constantly present and maps the same physical memory in all processes. Kernel code and data are always addressable, ready to handle interrupts or system calls at any time. By contrast, the mapping for the user-mode portion of the address space changes whenever a process switch happens:
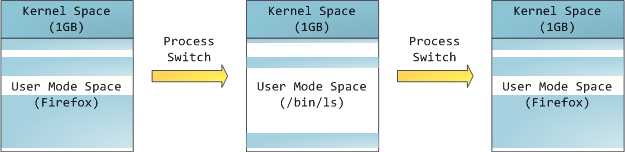
Blue regions represent virtual addresses that are mapped to physical memory, whereas white regions are unmapped. In the example above, Firefox has used far more of its virtual address space due to its legendary memory hunger. The distinct bands in the address space correspond to memory segments like the heap, stack, and so on. Keep in mind these segments are simply a range of memory addresses and have nothing to do with Intel-style segments. Anyway, here is the standard segment layout in a Linux process:
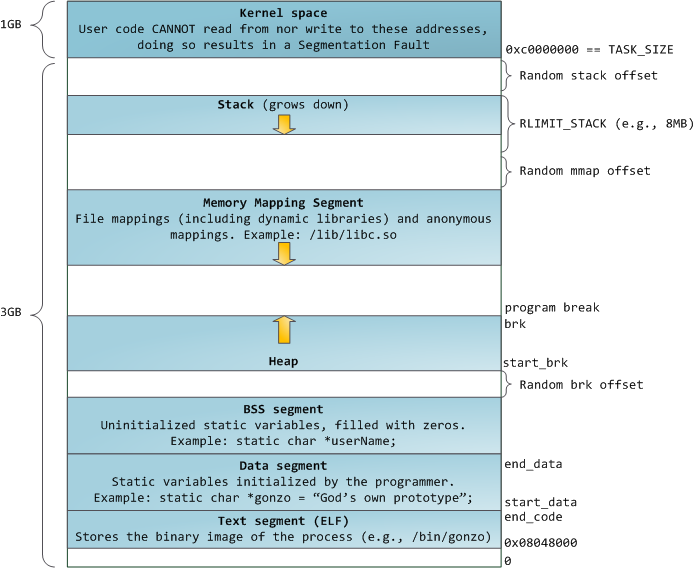
When computing was happy and safe and cuddly, the starting virtual addresses for the segments shown above were exactly the same for nearly every process in a machine. This made it easy to exploit security vulnerabilities remotely. An exploit often needs to reference absolute memory locations: an address on the stack, the address for a library function, etc. Remote attackers must choose this location blindly, counting on the fact that address spaces are all the same. When they are, people get pwned. Thus address space randomization has become popular. Linux randomizes thestack, memory mapping segment, and heap by adding offsets to their starting addresses. Unfortunately the 32-bit address space is pretty tight, leaving little room for randomization andhampering its effectiveness.
The topmost segment in the process address space is the stack, which stores local variables and function parameters in most programming languages. Calling a method or function pushes a newstack frame onto the stack. The stack frame is destroyed when the function returns. This simple design, possible because the data obeys strict LIFO order, means that no complex data structure is needed to track stack contents – a simple pointer to the top of the stack will do. Pushing and popping are thus very fast and deterministic. Also, the constant reuse of stack regions tends to keep active stack memory in the cpu caches, speeding up access. Each thread in a process gets its own stack.
It is possible to exhaust the area mapping the stack by pushing more data than it can fit. This triggers a page fault that is handled in Linux by expand_stack(), which in turn callsacct_stack_growth() to check whether it’s appropriate to grow the stack. If the stack size is belowRLIMIT_STACK (usually 8MB), then normally the stack grows and the program continues merrily, unaware of what just happened. This is the normal mechanism whereby stack size adjusts to demand. However, if the maximum stack size has been reached, we have a stack overflow and the program receives a Segmentation Fault. While the mapped stack area expands to meet demand, it does not shrink back when the stack gets smaller. Like the federal budget, it only expands.
Dynamic stack growth is the only situation in which access to an unmapped memory region, shown in white above, might be valid. Any other access to unmapped memory triggers a page fault that results in a Segmentation Fault. Some mapped areas are read-only, hence write attempts to these areas also lead to segfaults.
Below the stack, we have the memory mapping segment. Here the kernel maps contents of files directly to memory. Any application can ask for such a mapping via the Linux mmap() system call (implementation) or CreateFileMapping() / MapViewOfFile() in Windows. Memory mapping is a convenient and high-performance way to do file I/O, so it is used for loading dynamic libraries. It is also possible to create an anonymous memory mapping that does not correspond to any files, being used instead for program data. In Linux, if you request a large block of memory via malloc(), the C library will create such an anonymous mapping instead of using heap memory. ‘Large’ means larger than MMAP_THRESHOLD bytes, 128 kB by default and adjustable via mallopt().
Speaking of the heap, it comes next in our plunge into address space. The heap provides runtime memory allocation, like the stack, meant for data that must outlive the function doing the allocation, unlike the stack. Most languages provide heap management to programs. Satisfying memory requests is thus a joint affair between the language runtime and the kernel. In C, the interface to heap allocation is malloc() and friends, whereas in a garbage-collected language like C# the interface is thenew keyword.
If there is enough space in the heap to satisfy a memory request, it can be handled by the language runtime without kernel involvement. Otherwise the heap is enlarged via the brk() system call (implementation) to make room for the requested block. Heap management is complex, requiring sophisticated algorithms that strive for speed and efficient memory usage in the face of our programs’ chaotic allocation patterns. The time needed to service a heap request can vary substantially. Real-time systems have special-purpose allocators to deal with this problem. Heaps also becomefragmented, shown below:

Finally, we get to the lowest segments of memory: BSS, data, and program text. Both BSS and data store contents for static (global) variables in C. The difference is that BSS stores the contents ofuninitialized static variables, whose values are not set by the programmer in source code. The BSS memory area is anonymous: it does not map any file. If you say static int cntActiveUsers, the contents of cntActiveUsers live in the BSS.
The data segment, on the other hand, holds the contents for static variables initialized in source code. This memory area is not anonymous. It maps the part of the program’s binary image that contains the initial static values given in source code. So if you say static int cntWorkerBees = 10, the contents of cntWorkerBees live in the data segment and start out as 10. Even though the data segment maps a file, it is a private memory mapping, which means that updates to memory are not reflected in the underlying file. This must be the case, otherwise assignments to global variables would change your on-disk binary image. Inconceivable!
The data example in the diagram is trickier because it uses a pointer. In that case, the contents of pointer gonzo – a 4-byte memory address – live in the data segment. The actual string it points to does not, however. The string lives in the text segment, which is read-only and stores all of your code in addition to tidbits like string literals. The text segment also maps your binary file in memory, but writes to this area earn your program a Segmentation Fault. This helps prevent pointer bugs, though not as effectively as avoiding C in the first place. Here’s a diagram showing these segments and our example variables:
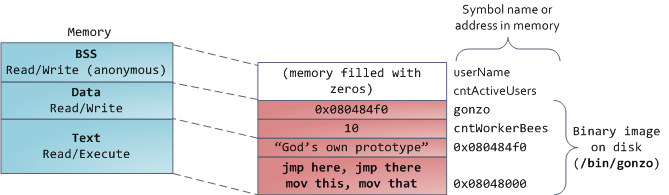
You can examine the memory areas in a Linux process by reading the file /proc/pid_of_process/maps. Keep in mind that a segment may contain many areas. For example, each memory mapped file normally has its own area in the mmap segment, and dynamic libraries have extra areas similar to BSS and data. The next post will clarify what ‘area’ really means. Also, sometimes people say “data segment” meaning all of data + bss + heap.
You can examine binary images using the nm and objdump commands to display symbols, their addresses, segments, and so on. Finally, the virtual address layout described above is the “flexible” layout in Linux, which has been the default for a few years. It assumes that we have a value forRLIMIT_STACK. When that’s not the case, Linux reverts back to the “classic” layout shown below:
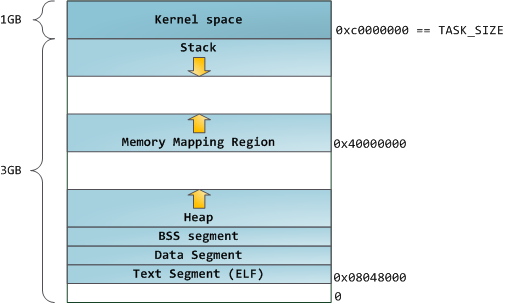
That’s it for virtual address space layout. The next post discusses how the kernel keeps track of these memory areas. Coming up we’ll look at memory mapping, how file reading and writing ties into all this and what memory usage figures mean.
Quick Note on Diagrams and the Blog
People often ask me what tool I use to make the diagrams in my Software Illustrated posts. I use MS Visio 2007. It has a ‘themes’ feature that allows you to set fill and line options that apply to all the shapes in a diagram, making it faster to produce decent looking things. It still takes a surprising amount of work to get good pictures, but overall I’m pretty happy.
Also, I have tried to use colors to convey meaning. They’re not just for pretty. For example, memory colors follow these conventions across all diagrams:

These colors hold from the earliest post about memory to the latest. This convention is why the post about Intel CPU caches shows a blue index for the virtually indexed L1 cache. So far I’ve written a lot about kernel and x86 internals, but that’s sort of a coincidence. I’m a generalist, not an OS guy; there’s a wide range of CS topics I hope to write about. (All this internals talk though made me want to write Linux kernel code again. I might look for some subsystem or driver to work on. What’s that sleep supression pill again?)
Finally, in the next couple of months I plan to change my blog template. The new one will have a hand-maintained ‘Archive by Topic’ page to serve as a coherent index to all posts, plus other usability improvements. I hate the current site as far as that goes. I can handle the logic and markup, but if anyone out there is interested in doing a small design/CSS job on this blog, please drop me a line. I also have a quick question. Many people access the site via iPhones and other mobile devices. How does image width impact you? Would it be painful if diagrams were wider than their current 700-pixel limit? I’d appreciate input on this and suggestions in general. Thanks! I’m off to check out the Denver LAMP meetup. Here’s a good song if you’re bored.
Page Cache, the Affair Between Memory and Files
Previously we looked at how the kernel manages virtual memory for a user process, but files and I/O were left out. This post covers the important and often misunderstood relationship between files and memory and its consequences for performance.
Two serious problems must be solved by the OS when it comes to files. The first one is the mind-blowing slowness of hard drives, and disk seeks in particular, relative to memory. The second is the need to load file contents in physical memory once and share the contents among programs. If you use Process Explorer to poke at Windows processes, you’ll see there are ~15MB worth of common DLLs loaded in every process. My Windows box right now is running 100 processes, so without sharing I’d be using up to ~1.5 GB of physical RAM just for common DLLs. No good. Likewise, nearly all Linux programs need ld.so and libc, plus other common libraries.
Happily, both problems can be dealt with in one shot: the page cache, where the kernel stores page-sized chunks of files. To illustrate the page cache, I’ll conjure a Linux program named render, which opens file scene.dat and reads it 512 bytes at a time, storing the file contents into a heap-allocated block. The first read goes like this:
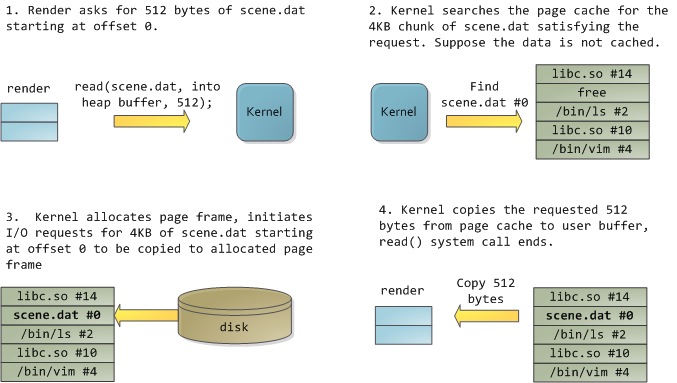
After 12KB have been read, render‘s heap and the relevant page frames look thus:
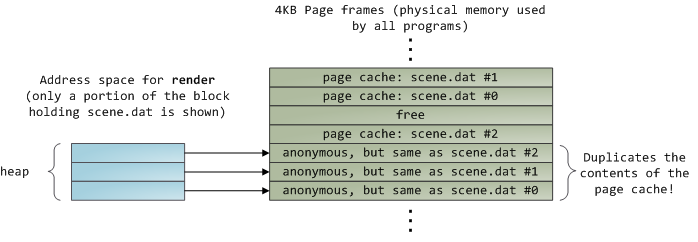
This looks innocent enough, but there’s a lot going on. First, even though this program uses regularread calls, three 4KB page frames are now in the page cache storing part of scene.dat. People are sometimes surprised by this, but all regular file I/O happens through the page cache. In x86 Linux, the kernel thinks of a file as a sequence of 4KB chunks. If you read a single byte from a file, the whole 4KB chunk containing the byte you asked for is read from disk and placed into the page cache. This makes sense because sustained disk throughput is pretty good and programs normally read more than just a few bytes from a file region. The page cache knows the position of each 4KB chunk within the file, depicted above as #0, #1, etc. Windows uses 256KB views analogous to pages in the Linux page cache.
Sadly, in a regular file read the kernel must copy the contents of the page cache into a user buffer, which not only takes cpu time and hurts the cpu caches, but also wastes physical memory with duplicate data. As per the diagram above, the scene.dat contents are stored twice, and each instance of the program would store the contents an additional time. We’ve mitigated the disk latency problem but failed miserably at everything else. Memory-mapped files are the way out of this madness:
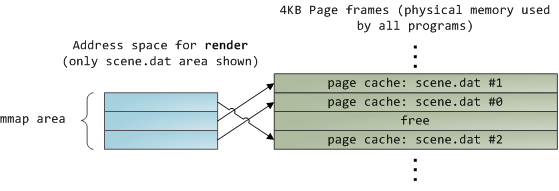
When you use file mapping, the kernel maps your program’s virtual pages directly onto the page cache. This can deliver a significant performance boost: Windows System Programming reports run time improvements of 30% and up relative to regular file reads, while similar figures are reported for Linux and Solaris in Advanced Programming in the Unix Environment. You might also save large amounts of physical memory, depending on the nature of your application.
As always with performance, measurement is everything, but memory mapping earns its keep in a programmer’s toolbox. The API is pretty nice too, it allows you to access a file as bytes in memory and does not require your soul and code readability in exchange for its benefits. Mind your address space and experiment with mmap in Unix-like systems, CreateFileMapping in Windows, or the many wrappers available in high level languages. When you map a file its contents are not brought into memory all at once, but rather on demand via page faults. The fault handler maps your virtual pagesonto the page cache after obtaining a page frame with the needed file contents. This involves disk I/O if the contents weren’t cached to begin with.
Now for a pop quiz. Imagine that the last instance of our render program exits. Would the pages storing scene.dat in the page cache be freed immediately? People often think so, but that would be a bad idea. When you think about it, it is very common for us to create a file in one program, exit, then use the file in a second program. The page cache must handle that case. When you think more about it, why should the kernel ever get rid of page cache contents? Remember that disk is 5 orders of magnitude slower than RAM, hence a page cache hit is a huge win. So long as there’s enough free physical memory, the cache should be kept full. It is therefore not dependent on a particular process, but rather it’s a system-wide resource. If you run render a week from now and scene.dat is still cached, bonus! This is why the kernel cache size climbs steadily until it hits a ceiling. It’s not because the OS is garbage and hogs your RAM, it’s actually good behavior because in a way free physical memory is a waste. Better use as much of the stuff for caching as possible.
Due to the page cache architecture, when a program calls write() bytes are simply copied to the page cache and the page is marked dirty. Disk I/O normally does not happen immediately, thus your program doesn’t block waiting for the disk. On the downside, if the computer crashes your writes will never make it, hence critical files like database transaction logs must be fsync()ed (though one must still worry about drive controller caches, oy!). Reads, on the other hand, normally block your program until the data is available. Kernels employ eager loading to mitigate this problem, an example of which is read ahead where the kernel preloads a few pages into the page cache in anticipation of your reads. You can help the kernel tune its eager loading behavior by providing hints on whether you plan to read a file sequentially or randomly (see madvise(), readahead(), Windows cache hints). Linux does read-ahead for memory-mapped files, but I’m not sure about Windows. Finally, it’s possible to bypass the page cache using O_DIRECT in Linux or NO_BUFFERING in Windows, something database software often does.
A file mapping may be private or shared. This refers only to updates made to the contents in memory: in a private mapping the updates are not committed to disk or made visible to other processes, whereas in a shared mapping they are. Kernels use the copy on write mechanism, enabled by page table entries, to implement private mappings. In the example below, both render and another program called render3d (am I creative or what?) have mapped scene.dat privately. Renderthen writes to its virtual memory area that maps the file:
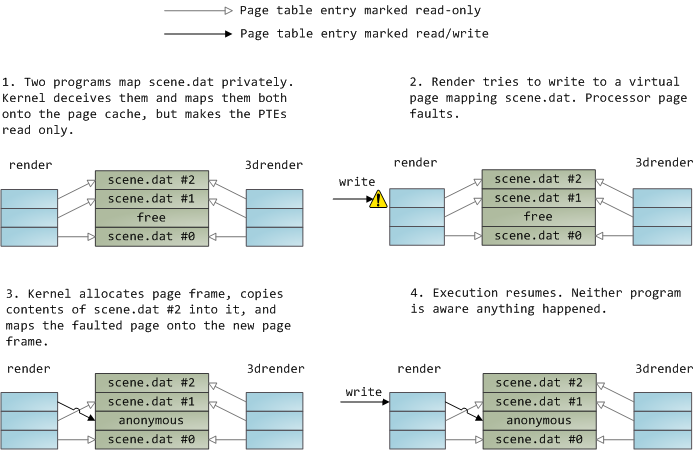
The read-only page table entries shown above do not mean the mapping is read only, they’re merely a kernel trick to share physical memory until the last possible moment. You can see how ‘private’ is a bit of a misnomer until you remember it only applies to updates. A consequence of this design is that a virtual page that maps a file privately sees changes done to the file by other programs as long as the page has only been read from. Once copy-on-write is done, changes by others are no longer seen. This behavior is not guaranteed by the kernel, but it’s what you get in x86 and makes sense from an API perspective. By contrast, a shared mapping is simply mapped onto the page cache and that’s it. Updates are visible to other processes and end up in the disk. Finally, if the mapping above were read-only, page faults would trigger a segmentation fault instead of copy on write.
Dynamically loaded libraries are brought into your program’s address space via file mapping. There’s nothing magical about it, it’s the same private file mapping available to you via regular APIs. Below is an example showing part of the address spaces from two running instances of the file-mapping renderprogram, along with physical memory, to tie together many of the concepts we’ve seen.
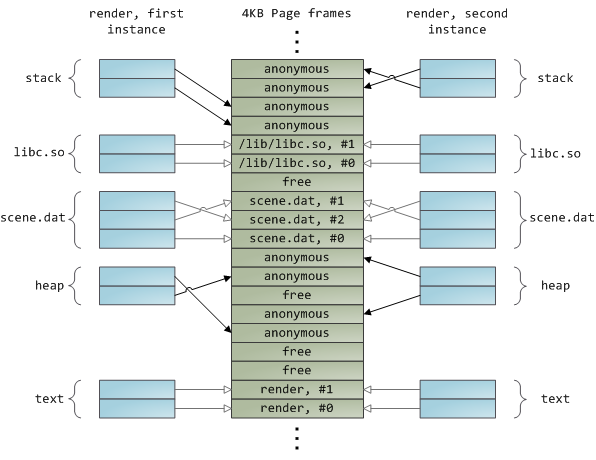
This concludes our 3-part series on memory fundamentals. I hope the series was useful and provided you with a good mental model of these OS topics. Next week there’s one more post on memory usage figures, and then it’s time for a change of air. Maybe some Web 2.0 gossip or something. ![]()
How The Kernel Manages Your Memory
After examining the virtual address layout of a process, we turn to the kernel and its mechanisms for managing user memory. Here is gonzo again:
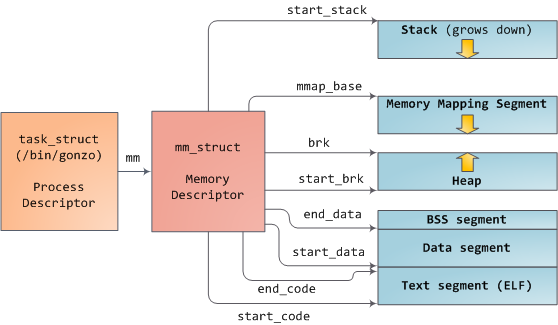
Linux processes are implemented in the kernel as instances of task_struct, the process descriptor. The mm field in task_struct points to the memory descriptor, mm_struct, which is an executive summary of a program’s memory. It stores the start and end of memory segments as shown above, the number of physical memory pages used by the process (rss stands for Resident Set Size), theamount of virtual address space used, and other tidbits. Within the memory descriptor we also find the two work horses for managing program memory: the set of virtual memory areas and the page tables. Gonzo’s memory areas are shown below:
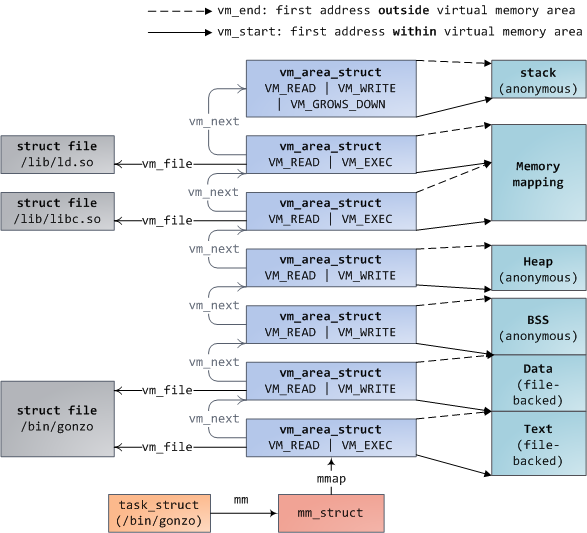
Each virtual memory area (VMA) is a contiguous range of virtual addresses; these areas never overlap. An instance of vm_area_struct fully describes a memory area, including its start and end addresses, flags to determine access rights and behaviors, and the vm_file field to specify which file is being mapped by the area, if any. A VMA that does not map a file is anonymous. Each memory segment above (e.g., heap, stack) corresponds to a single VMA, with the exception of the memory mapping segment. This is not a requirement, though it is usual in x86 machines. VMAs do not care which segment they are in.
A program’s VMAs are stored in its memory descriptor both as a linked list in the mmap field, ordered by starting virtual address, and as a red-black tree rooted at the mm_rb field. The red-black tree allows the kernel to search quickly for the memory area covering a given virtual address. When you read file /proc/pid_of_process/maps, the kernel is simply going through the linked list of VMAs for the process and printing each one.
In Windows, the EPROCESS block is roughly a mix of task_struct and mm_struct. The Windows analog to a VMA is the Virtual Address Descriptor, or VAD; they are stored in an AVL tree. You know what the funniest thing about Windows and Linux is? It’s the little differences.
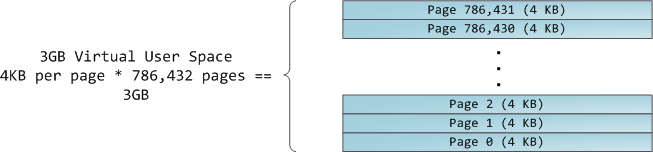
The 4GB virtual address space is divided into pages. x86 processors in 32-bit mode support page sizes of 4KB, 2MB, and 4MB. Both Linux and Windows map the user portion of the virtual address space using 4KB pages. Bytes 0-4095 fall in page 0, bytes 4096-8191 fall in page 1, and so on. The size of a VMA must be a multiple of page size. Here’s 3GB of user space in 4KB pages:
The processor consults page tables to translate a virtual address into a physical memory address. Each process has its own set of page tables; whenever a process switch occurs, page tables for user space are switched as well. Linux stores a pointer to a process’ page tables in the pgd field of the memory descriptor. To each virtual page there corresponds one page table entry (PTE) in the page tables, which in regular x86 paging is a simple 4-byte record shown below:

Linux has functions to read and set each flag in a PTE. Bit P tells the processor whether the virtual page is present in physical memory. If clear (equal to 0), accessing the page triggers a page fault. Keep in mind that when this bit is zero, the kernel can do whatever it pleases with the remaining fields. The R/W flag stands for read/write; if clear, the page is read-only. Flag U/S stands for user/supervisor; if clear, then the page can only be accessed by the kernel. These flags are used to implement the read-only memory and protected kernel space we saw before.
Bits D and A are for dirty and accessed. A dirty page has had a write, while an accessed page has had a write or read. Both flags are sticky: the processor only sets them, they must be cleared by the kernel. Finally, the PTE stores the starting physical address that corresponds to this page, aligned to 4KB. This naive-looking field is the source of some pain, for it limits addressable physical memory to 4 GB. The other PTE fields are for another day, as is Physical Address Extension.
A virtual page is the unit of memory protection because all of its bytes share the U/S and R/W flags. However, the same physical memory could be mapped by different pages, possibly with different protection flags. Notice that execute permissions are nowhere to be seen in the PTE. This is why classic x86 paging allows code on the stack to be executed, making it easier to exploit stack buffer overflows (it’s still possible to exploit non-executable stacks using return-to-libc and other techniques). This lack of a PTE no-execute flag illustrates a broader fact: permission flags in a VMA may or may not translate cleanly into hardware protection. The kernel does what it can, but ultimately the architecture limits what is possible.
Virtual memory doesn’t store anything, it simply maps a program’s address space onto the underlying physical memory, which is accessed by the processor as a large block called the physical address space. While memory operations on the bus are somewhat involved, we can ignore that here and assume that physical addresses range from zero to the top of available memory in one-byte increments. This physical address space is broken down by the kernel into page frames. The processor doesn’t know or care about frames, yet they are crucial to the kernel because the page frame is the unit of physical memory management. Both Linux and Windows use 4KB page frames in 32-bit mode; here is an example of a machine with 2GB of RAM:
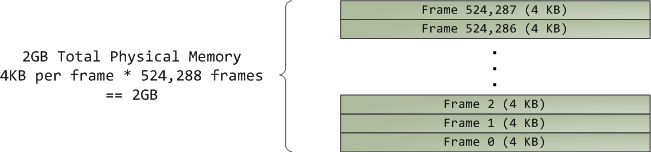
In Linux each page frame is tracked by a descriptor and several flags. Together these descriptors track the entire physical memory in the computer; the precise state of each page frame is always known. Physical memory is managed with the buddy memory allocation technique, hence a page frame is free if it’s available for allocation via the buddy system. An allocated page frame might beanonymous, holding program data, or it might be in the page cache, holding data stored in a file or block device. There are other exotic page frame uses, but leave them alone for now. Windows has an analogous Page Frame Number (PFN) database to track physical memory.
Let’s put together virtual memory areas, page table entries and page frames to understand how this all works. Below is an example of a user heap:
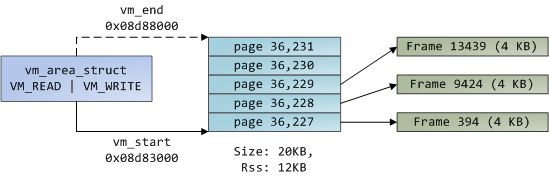
Blue rectangles represent pages in the VMA range, while arrows represent page table entries mapping pages onto page frames. Some virtual pages lack arrows; this means their corresponding PTEs have the Present flag clear. This could be because the pages have never been touched or because their contents have been swapped out. In either case access to these pages will lead to page faults, even though they are within the VMA. It may seem strange for the VMA and the page tables to disagree, yet this often happens.
A VMA is like a contract between your program and the kernel. You ask for something to be done (memory allocated, a file mapped, etc.), the kernel says “sure”, and it creates or updates the appropriate VMA. But it does not actually honor the request right away, it waits until a page fault happens to do real work. The kernel is a lazy, deceitful sack of scum; this is the fundamental principle of virtual memory. It applies in most situations, some familiar and some surprising, but the rule is that VMAs record what has been agreed upon, while PTEs reflect what has actually been done by the lazy kernel. These two data structures together manage a program’s memory; both play a role in resolving page faults, freeing memory, swapping memory out, and so on. Let’s take the simple case of memory allocation:
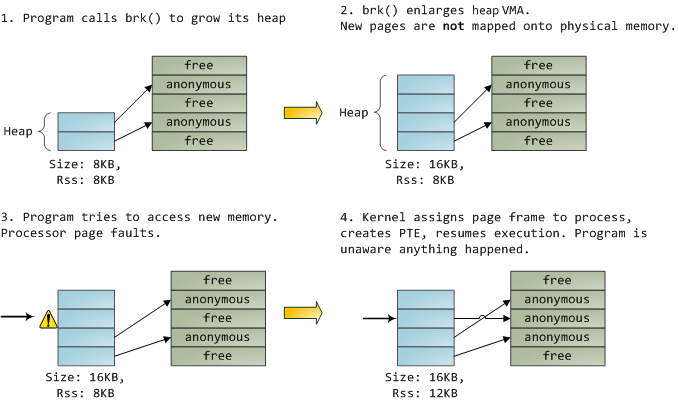
When the program asks for more memory via the brk() system call, the kernel simply updates the heap VMA and calls it good. No page frames are actually allocated at this point and the new pages are not present in physical memory. Once the program tries to access the pages, the processor page faults and do_page_fault() is called. It searches for the VMA covering the faulted virtual address using find_vma(). If found, the permissions on the VMA are also checked against the attempted access (read or write). If there’s no suitable VMA, no contract covers the attempted memory access and the process is punished by Segmentation Fault.
When a VMA is found the kernel must handle the fault by looking at the PTE contents and the type of VMA. In our case, the PTE shows the page is not present. In fact, our PTE is completely blank (all zeros), which in Linux means the virtual page has never been mapped. Since this is an anonymous VMA, we have a purely RAM affair that must be handled by do_anonymous_page(), which allocates a page frame and makes a PTE to map the faulted virtual page onto the freshly allocated frame.
Things could have been different. The PTE for a swapped out page, for example, has 0 in the Present flag but is not blank. Instead, it stores the swap location holding the page contents, which must be read from disk and loaded into a page frame by do_swap_page() in what is called a major fault.
This concludes the first half of our tour through the kernel’s user memory management. In the next post, we’ll throw files into the mix to build a complete picture of memory fundamentals, including consequences for performance.