当今人工智能主流方向 —— 连接主义,即仿脑神经元连接,实现感性思维,如神经网络。
神经网络的一般设计过程:
- 准备数据:采集大量“特征/标签”数据
- 搭建网络:搭建神经网络结构
- 优化参数:训练网络获取最佳参数(反向传播)
- 应用网络:将网络保存为模型,输入新数据,输出分类或预测结果(前向传播)
前向传播
y = x * w + b,输入x,计算出y的过程叫做前向传播
损失函数:可预测值(y)与标准答案(y_)的差距,定量判断w、b的优劣。
当损失函数输出最小时,参数w、b会出现最优值。
均方误差是一种常用的损失函数。
梯度下降
目的:找到一组w、b,使得损失函数最小。
梯度:损失函数对各参数求偏导后的向量。损失函数梯度下降的方向,就是损失函数减小的方向。
梯度下降法:沿损失函数梯度下降的方向,寻找损失函数的最小值,得到最优参数的方法。
学习率 lr:梯度下降的速度。
学习率过小,参数更新会很慢;
学习率过大,参数更新会跳过最小值。
反向传播
首先设置反向传播迭代次数,在每次迭代中,根据下图公式,迭代更新所有参数。


反向传播(使用梯度下降法,使损失函数最小)
代码示例:
import tensorflow as tf
# w的初始值为5,设置为可训练
w = tf.Variable(tf.constant(5, dtype=tf.float32))
# 学习率为0.2
lr = 0.2
# 数据集喂入神经网络30次
epoch = 30
# 数据集级别的循环,每个epoch循环一次数据集
for epoch in range(epoch):
# 使用with结构定义loss函数,gradient函数告知谁对谁求导
with tf.GradientTape() as tape:
# 损失函数定义为(w+1)^2
loss = tf.square(w + 1)
grads = tape.gradient(loss, w)
# assign_sub函数:变量自减,即:w -= lr*grads
w.assign_sub(lr * grads)
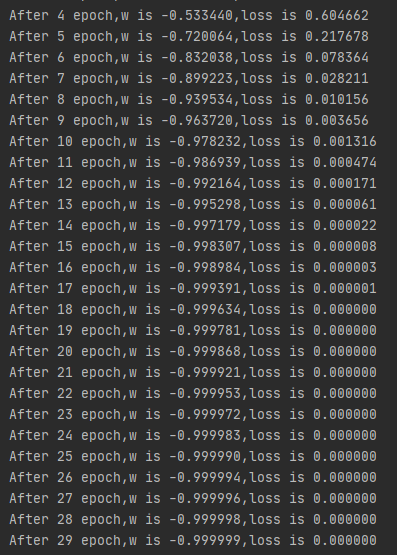
print("After %s epoch,w is %f,loss is %f" % (epoch, w.numpy(), loss))
# 最终结果:损失函数最小值为 loss = 0.0,最优参数为 w = -1
输出结果: