HashMap
一. 存储特性
- 无序且不可重复
1. 为什么无序且不可重复??
- HashMap是以key的值,所计算的hash值与数组长度,再计算出元素所对应的索引下标,进行存储,并不是像ArrayList一样依次存入,所以HashMap是无序的
- 当元素key的hash值相同,则会再判断他们的key值是否相同,如果两者都相同,后key对应的value值,会直接替换前key的value值,所以HashMap是不可重复的
2. HashMap的key和value可以为null吗??
- 首先是它的key和value值都是可以为null
- 但是其key的值为null,有且只能有一个,遵循其特性不可重复
- 再者,还有个特点: 因为底层因null是没有hash值的,所以直接给他了一个固定的hash值为0,因为key为null的元素,只会存储在数组第一个,也就是索引为0的位置上

3. 延伸题: 这些集合的key和value值可以为null吗??
- HashTable:
- 其key不能为null
- key没有hash值,也没有像HashMap一样直接给其key赋hash值为0,所以不能为null
- 其value值也不能为null
- 底层在添加操作时,直接对value进行了非空判断,为null,则直接抛出空指针异常
- 其key不能为null

- ConcurrentHashMap
- 其key和value都不能为null,否则抛出空指针异常

4. 先了解JDK1.7的HashMap
- 源码核心属性:
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 默认的初始化容量 = 16
- static final float DEFAULT_LOAD_FACTOR = 0.75f; 默认加载因子 (与扩容阈值有关)
- static final Entry<?,?>[] EMPTY_TABLE = {}; entry 对象数组 空数组
- transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; table 存储元素的数据 默认就是一个空数组
- transient int size; 记录存储元素的个数
- int threshold; 扩容阈值 (threshold = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR = 12)
- 相关信息:
- 初始长度为0, 只有在第一次添加元素的时候才会扩容,初始化初始容量
- 扩容大小是原来的2倍
- 数据结构: 数组+单向链表
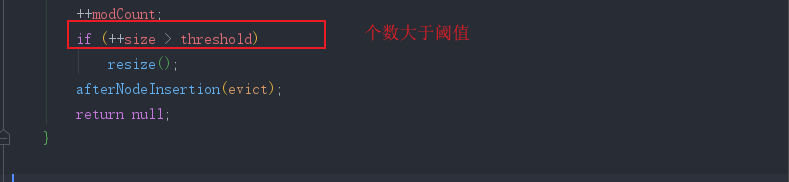
- 扩容时机: 基于初始容量为16来说明. 必须达到两个条件,才会扩容
- 添加第十三个元素 size >= 12 && 出现hash冲突

-
- 必定扩容时机: 基于初始容量为16来说明.
- 最多存储27个元素,直到第28个元素的时候必扩容
- 必定扩容时机: 基于初始容量为16来说明.

-
- 单向链表添加元素的方式??
- JDK1.7单向链表 属于 头插法 后来的节点会成为头节点
- 存在的最大问题??
- 因为HashMap属于线程不安全,所以会出现并发同时存储同一个地方所导致的链表中的环链
- 为什么hashMap 的 DEFAULT_INITIAL_CAPACITY = 16的值是 2的幂次方??
- 因为底层用的是位运算 其运算最快 效率高
- 单向链表添加元素的方式??
5. 再了解JDK1.8的HashMap
- 源码核心属性:
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 默认的初始化容量 = 16
- static final int MAXIMUM_CAPACITY = 1 << 30; 最大容量
- static final float DEFAULT_LOAD_FACTOR = 0.75f; 默认加载因子 (与扩容阈值有关)
- static final int TREEIFY_THRESHOLD = 8; 默认树化值
- static final int UNTREEIFY_THRESHOLD = 6; 取消树化值
- static final int MIN_TREEIFY_CAPACITY = 64; 最小树容量 (与扩容有关)
- transient Node<K,V>[] table;
- 核心构造:
-
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}- 无参构造, 只进行了初始化加载因子,
- 并没有初始化容量,因此,这里可以得出初始化容量为0
-
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}- 有参构造, 指定初始化容量
- 里面只对初始化了加载因子和阈值,但是初始化容量也为0
- 注意:此阈值,使用一个方法,这个方法根据形参,找到大于等于 initialCapacity 的最小的 2 的幂。
- 创建集合,初始化容量都为0,只有在第一次添加元素时,在扩容方法中才会进行修改初始化容量
-
- 核心方法 : (按顺序)
- 扩容(第一次&&非第一次)



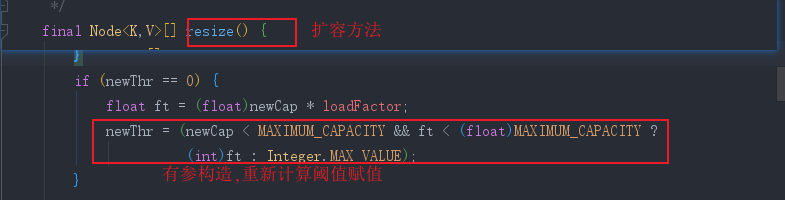
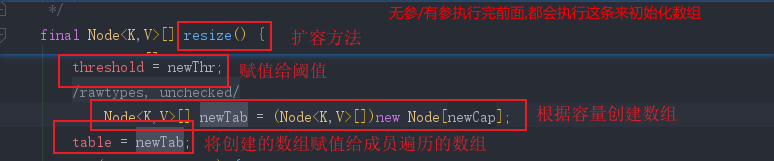
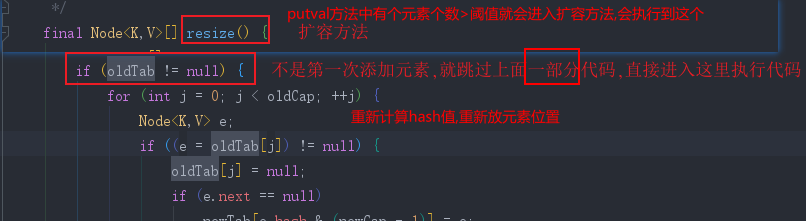

-
- 添加元素(hash是否碰撞)

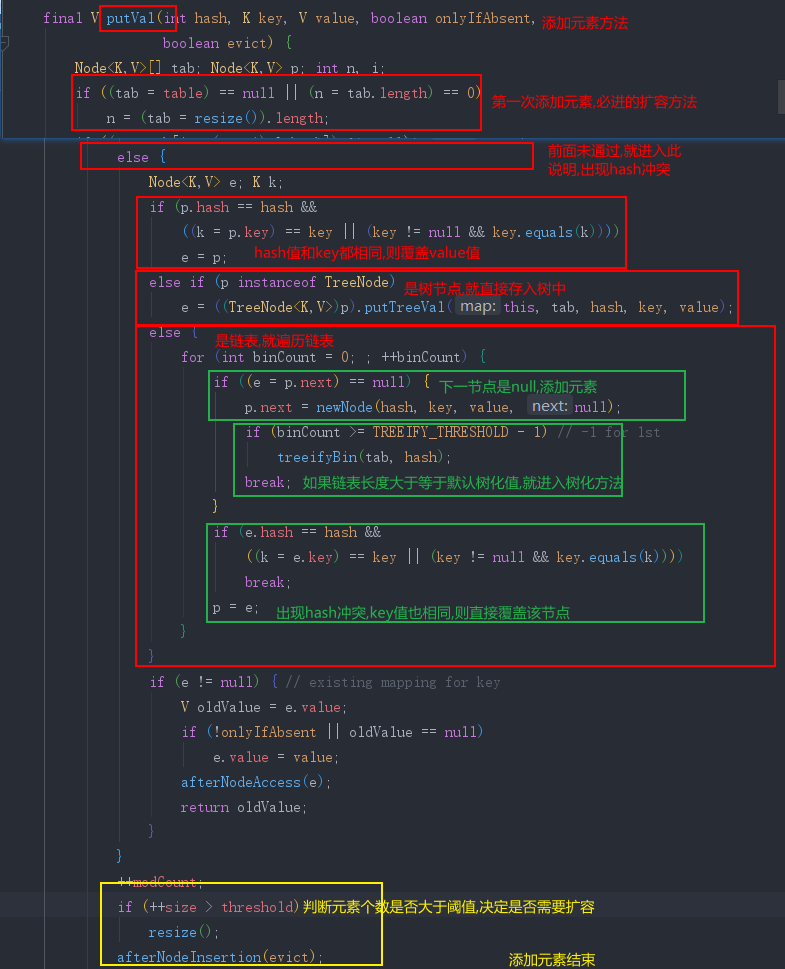
-
- 树化
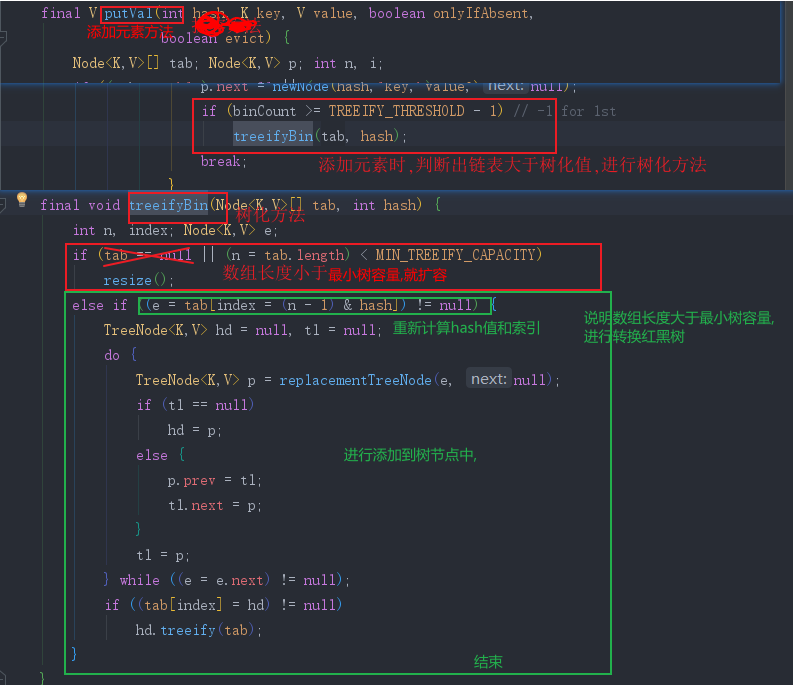
- 相关信息:
- 初始长度为0, 只有在第一次添加元素的时候才会扩容,初始化初始容量
- 扩容大小是原来的2倍
- 数据结构: 数组+单向链表+红黑树
- 扩容时机: 基于初始容量为16来说明.
- 在存储第13个元素的时候必定扩容
- 链表大于8,进入树化方法中,会先进行树化扩容条件判断,数组小于64,则不会树化,但是会对数组进行扩容

-
- 树化时机:
- 链表大于8,且数组长度大于64
- 树化时机:


-
- 取消树化时机:
- 树节点小于等于6时,转回链表
- 延申题:
- 树化值是8, 取消树是6, 那么7这个值是什么状态??
- 首先7的存在,可以将树化值和取消树的转换的频率减少,提高一定的效率
- 其次,新增7时,是链表; 删除7时,是红黑树
- 树化值是8, 取消树是6, 那么7这个值是什么状态??
- 存在的最大问题??
- 因为HashMap属于线程不安全,所以会出现并发导致的链表中的环链
- 不过相比较JDK1.7的HashMap,环链的几率降低
- 单向链表添加元素的方式??
- JDK1.8中的单向链表 属于 尾插法
- 取消树化时机:
6. JDK1.7 和 JDK1.8 的HashMap之间有什么不同点??
- 数据结构上:
- JDK1.7 数组 + 单向链表
- JDK1.8 数组 + 单向链表 + 红黑树
- 扩容条件上:
- JDK1.7 等于阈值+1 && 出现hash冲突 || 元素个数等于27,插入第28个元素
- JDK1.8 等于阈值+1 || 链表长度大于8,但数组长度不大于树化值
- 链表插入元素方式:
- JDK1.7 头插法
- JDK1.8 尾插法
7.HashMap 线程不安全 , 如何解决??
- ConcurrentHashMap 如何实现?? 分段锁机制
- HashTable JDK1.5时就弃用了,原因?? 对方法整体直接加同步锁synchronized
- Collections 工具类中的方法 Collections.synchronizedMap(hashMap);
8. ConcurrentHashMap & HashTable 中的锁的区别??(图画展示区别)

9. 已知hashMap需要存储1000个元素。那么构建hashMap的长度应该为多少??
- 2048
- 为何为2048??
- 首先初始容量必须建议为2的幂次方: 16 32 64 128 256 512 1024 2408 ....
- 刚好只有1024和2048为初始容量可以存储1000个元素,但是,还需要计算出对应的阈值768和1536
- 说明为1024,还将需要扩容一次
- 而2048不需要扩容,就可以直接存储1000个元素,容量又满足2的幂次方,此容量是效率最好的
10. 为什么初始容量是2的幂次方??
- 首先初始容量为2的幂次方,元素存储位置可以分布更均匀
- 因为底层用的是位运算 其运算最快 效率高
- 如果不是2的幂次方,就会特别容易出现索引相同以及hash碰撞,导致大部分空间没有存储数据,而小部分数据存储过多,链表或红黑树过长,出现效率降低的情况
11. 为什么负载因子默认为0.75,初始化临界值是12??
- 负载因子越近于1,数组中存放的数据也就越多,也就越密,也就是会让链表的长度增加,
- 越近于0,数组中存放的数据也就越少,也就越稀疏。
- 如果希望链表尽可能少些,要提前扩容。有的数组空间有可能一直没有存储数据,负载因子尽可能小一些。
- 所以既兼顾数组利用率又考虑链表不要太多,经过大量测试 0.75 是最佳方案。
12. HashMap 中 hash 函数是怎么实现的?还有哪些hash函数的实现方式??
- 对于 key 的 hashCode 做 hash 操作,无符号右移 16 位然后做异或运算。
- 还有平方取中法,伪随机数法和取余数法。
- 这三种效率都比较低。而无符号右移 16 位异或运算效率是最高的。
13. 什么是哈希碰撞,如何解决哈希碰撞??
- 只要两个元素的 key 计算的哈希码值相同就会发生哈希碰撞。
- jdk7 使用链表解决哈希碰撞。
- jdk8之后使用链表 + 红黑树解决哈希碰撞。
14. 延伸题:
- HashSet的存储特性:
- 无序 且不可重复
- 无序 且不重复原因??
- 因为HashSet底层就是用HashMap的key来实现存储的,所以HashSet具备了HashMap的key的特性
- 特性: 无序: hash值和数组长度来确定索引位置; 不可重复:hash值和key值相同则直接替换value值