Reduction并行分析:
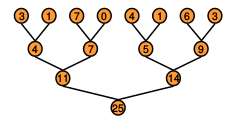
每个线程是基于一个树状的访问模型,从上至下,上一层读取数据相加得到下一层的数据.不停的迭代,直到访问完所有的数据.
利用这么多的线程块(thread block)我们需要做的事情如下:
1. 处理非常大的数组
2. 让GPU的每个处理器保持忙碌
3. 每个thread block迭代减少数组的区域. 比如这个图,第一次是8个数据,第二次是4个.
但是碰到一个问题,在thread block中的线程可以利用同步,但是每个thread block都处理完了,CUDA中并不能提供block级别的同步机制.为什么CUDA不支持全局同步呢?由两个原因:
1. 打造高性能GPU处理器的硬件个数是非常昂贵的,处理器越多越贵.
2. 这就强制程序员尽可能少的使用block个数以避免产生死锁,(此处还为弄明白:block个数不能大于处理器个数* )
这个问题该怎么处理呢,全局同步问题?
利用多个kernel来解决这个问题:
cuda kernel lanuch可以当做全局同步点.
cuda kernel lanuch硬件方面的消耗几乎可以忽略,软件消耗非常底.
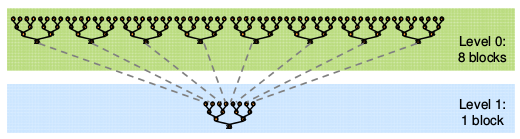
Level0 是第一个kernel,level1 是第二个kernel.
我们的优化目标是?
1. 努力达到GPU性能极限.
2. 选择合适的度量,有两种:
GFLOP/s: (FLOPS是Floating-point Operations Per Second每秒所执行的浮点运算次数的英文缩写)用于分析计算kernel的计算性能.
Band用于分析kernel的内存使用情况.
3. reduction是算数密集度非常低的,每个元素一个FLOP.所以我们需要优化极限带宽来提高信能.
4.以Nvida G80型号的GPU为例:
.384bit 存储接口宽度,900MHZ DDR. 384*1800(DDR 是doubel rate)/8 = 86.4GB/s
Reduction1: Interleaved Addressing
kernel代码:


__global__ void reduce0(int *g_idata, int *g_odata) { extern __shared__ int sdata[]; // each thread loads one element from global to shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads(); // do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { if (tid % (2*s) == 0) { sdata[tid] += sdata[tid + s]; } __syncthreads(); } // write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = sdata[0]; }
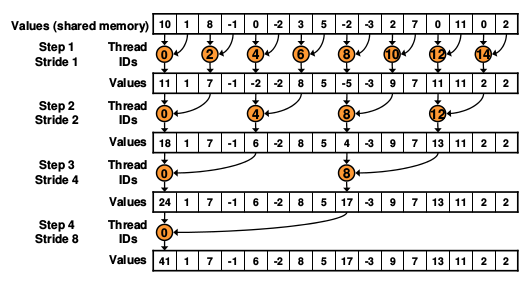
从图中可以看出,寻址的方式并不是联系的,而是交叉的. 所以称这个kernel为interleaved addressing.
分析kernel代码:
使用了sharedMemory,这里的大小是16,
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
上面两行可以看出block的size也是16. 这个kernel是一维的.
看for循环的代码,s 是访问内存的步长stride,随着迭代的深入,每一下一层的stride都会变成2倍,第一次是1,然后一次是2,4,8. 每个block的结果最终加到tid=0的线程里面.这是访问的存储的部分.计算部分:
第一次是tid[0]计算0,1两个元素,tid[2]计算2,3元素.....t[14]计算14,15元素.
所以第二次需要把tid[0],tid[2]...tid[14]的结果相加. 得到tid[0],tid[3]...tid[11].可以看到stride变化.
但不是每个线程都需要执行计算任务,只有每次只有一半的任务执行,第一次是8,第二次是4个最后是一个,用if(tid %(2*s) ==0)来约束.
在for循环体中有:
if(tid % (2*s) == 0){
sdata[tid] += sdata[tid + s];
__syncthreads();
}
if(tid ==0)g_odata[blockId.x] = sdata[0]. 最终每个block的结果保存在sdata[0]中并赋值给global outputdata. 当然这并没计算完最终的结果,最终结果需要在host端把这些global的结果累加得到.
所以上面的kernel可以看出:
1. 有很多线程并不执行计算.
2. 内存访问并不连续,而是交叉的.
3. if(tid % (2*s) == 0) 会导致大量的warp divergence.降低性能.
性能:

Reduction2: 消除warp divergence
把reduction1中的for循环体变成:
for (unsigned int s=1; s < blockDim.x; s *= 2) {
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[index] += sdata[index + s];
}
__syncthreads();
}
可以看出,改成这样计算什么都没变,但是消除了warp divergence,虽然如此,却引起了新的问题:bank conflict.
如果s =2, 那么thread0,thread2就会有bankconflict.
如果s=4, 那么thread0,thread4就会有bankconflict.关于bank conflict的概念可以参考下面的这篇文章
2.2CUDA-Memory(存储)和bank-conflict
reduction2的性能:

Reduction3: sequential addressing(连续寻址,就是合并访问)
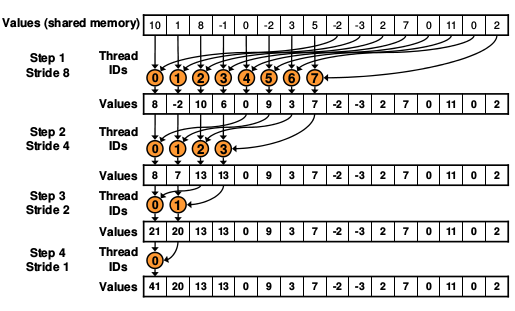
如上图,如果增加步长的长度,可以起到合并访问的效果,提高内存访问速率.
从上图可以看出stride不在是从小到大变化,而是由大到小的变化,从8到4,2,1
修改for循环体:
for (unsigned int s=blockDim.x/2; s>0; s>>=1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
但是bandwidth的性能提升是明显的,见下图:

继续分析,发现有一半的线程是一直没有在执行计算任务的.这很浪费处理器资源嘛.
Reduction4:第一次加载内存时执行相加.
我们把sharedMemory提高到之前的2倍,之前一个block算一个block的和,那么现在一个block计算两个block大小的和.
for循环题和reduction3的相同,修改加载代码:
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2)+ threadIdx.x
sdata[tid] = g_idata[i] + g_idata[i+blockDim.x];
这样sharedMemory,16个数据已经执行了一次加法,把blocksize*2的数据变成了blocksize的数据,后面的循环体和上面的reduction3相同. 所以称这总叫做:第一次载入执行相加,重点是每个载入的元素已经是一次加法的和,stride步长是blocksize.
reduction4的性能:
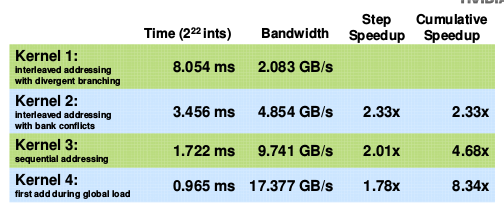
Reduction5: 修改最后一个warp
这时我们的数据带宽已经达到了17 GB/s,而我们清楚Reduction的算术强度(arithmetic intensity)很低,因此系统的瓶颈可能是由于Parallel Slowdown,即系统对于指令、调度的花费超过了实际数据处理的花费。在本例中即address arithmetic and loop overhead。
我们的解决办法是将for循环展开(Unroll the loop)。我们知道,在Reduce的过程中,活动的线程数是越来越少的,当活动的线程数少于32个时,我们将只有一个线程束(Warp)。在单个Warp中,指令的执行遵循SIMD(Single Instruction Multiple Data)模式,也就是说在活动线程数少于32个时,我么不需要进行同步控制,即我们不需要 if (tid < s) 。
修改kernel如下:
首先展开最后一个warp.
for (unsigned int s=blockDim.x/2; s>32; s>>=1) //步长stride小于32不用进循环,执行下面的动//作,并且不需要同步
{
if (tid < s)
sdata[tid] += sdata[tid + s];
__syncthreads();
}
if (tid < 32) {
if (blockSize >=64) sdata[tid] += sdata[tid + 32];
if (blockSize >=32) sdata[tid] += sdata[tid + 16];
if (blockSize >=16) sdata[tid] += sdata[tid + 8];
if (blockSize >=8) sdata[tid] += sdata[tid + 4];
if (blockSize >=4) sdata[tid] += sdata[tid + 2];
if (blockSize >=2) sdata[tid] += sdata[tid + 1];
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}Reduction6:完全展开循环体
if (blockSize >= 512) {
if (tid < 256) { sdata[tid] += sdata[tid + 256]; } __syncthreads();
}
if (blockSize >= 256) {
if (tid < 128) { sdata[tid] += sdata[tid + 128]; } __syncthreads();
}
if (blockSize >= 128) {
if (tid < 64) { sdata[tid] += sdata[tid + 64]; } __syncthreads();
}
if (tid < 32) {
if (blockSize >=64) sdata[tid] += sdata[tid + 32];
if (blockSize >=32) sdata[tid] += sdata[tid + 16];
if (blockSize >=16) sdata[tid] += sdata[tid + 8];
if (blockSize >=8) sdata[tid] += sdata[tid + 4];
if (blockSize >=4) sdata[tid] += sdata[tid + 2];
if (blockSize >=2) sdata[tid] += sdata[tid + 1];
}
上面代码所有红色的部分在编译阶段都会进行优化,结果是一个非常有效率的内循环.
Reduction5,6性能: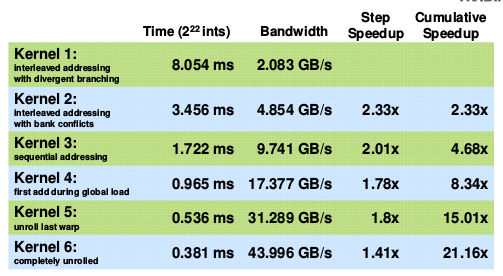
到此并行规约算法分析完毕,只要是符合规约类型的运算均符合这种优化思路