介绍
今天在Flink 1.7.2版本上跑一个Flink SQL 示例 RetractPvUvSQL,报
Exception in thread "main" org.apache.flink.table.api.ValidationException: SQL validation failed. From line 1, column 19 to line 1, column 51: Cannot apply 'DATE_FORMAT' to arguments of type 'DATE_FORMAT(<VARCHAR(65536)>, <CHAR(2)>)'. Supported form(s): '(TIMESTAMP, FORMAT)'
从提示看应该是不支持参数为字符串,接下来我们自定义一个UDF函数来支持这种场景。
官网不建议使用DATE_FORMAT(timestamp, string) 这种方式

RetractPvUvSQL 代码
public class RetractPvUvSQL {
public static void main(String[] args) throws Exception {
ParameterTool params = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = TableEnvironment.getTableEnvironment(env);
DataStreamSource<PageVisit> input = env.fromElements(
new PageVisit("2017-09-16 09:00:00", 1001, "/page1"),
new PageVisit("2017-09-16 09:00:00", 1001, "/page2"),
new PageVisit("2017-09-16 10:30:00", 1005, "/page1"),
new PageVisit("2017-09-16 10:30:00", 1005, "/page1"),
new PageVisit("2017-09-16 10:30:00", 1005, "/page2"));
// register the DataStream as table "visit_table"
tEnv.registerDataStream("visit_table", input, "visitTime, userId, visitPage");
Table table = tEnv.sqlQuery(
"SELECT " +
"visitTime, " +
"DATE_FORMAT(max(visitTime), 'HH') as ts, " +
"count(userId) as pv, " +
"count(distinct userId) as uv " +
"FROM visit_table " +
"GROUP BY visitTime");
DataStream<Tuple2<Boolean, Row>> dataStream = tEnv.toRetractStream(table, Row.class);
if (params.has("output")) {
String outPath = params.get("output");
System.out.println("Output path: " + outPath);
dataStream.writeAsCsv(outPath);
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
dataStream.print();
}
env.execute();
}
/**
* Simple POJO containing a website page visitor.
*/
public static class PageVisit {
public String visitTime;
public long userId;
public String visitPage;
// public constructor to make it a Flink POJO
public PageVisit() {
}
public PageVisit(String visitTime, long userId, String visitPage) {
this.visitTime = visitTime;
this.userId = userId;
this.visitPage = visitPage;
}
@Override
public String toString() {
return "PageVisit " + visitTime + " " + userId + " " + visitPage;
}
}
}
UDF实现
实现参数为字符串的日期解析
public class DateFormat extends ScalarFunction {
public String eval(Timestamp t, String format) {
return new SimpleDateFormat(format).format(t);
}
/**
* 默认日期格式:yyyy-MM-dd HH:mm:ss
*
* @param t
* @param format
* @return
*/
public static String eval(String t, String format) {
try {
Date originDate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(t);
return new SimpleDateFormat(format).format(originDate);
} catch (ParseException e) {
throw new RuntimeException("日期:" + t + "解析为格式" + format + "出错");
}
}
}
因为flink 已经内置DATE_FORMAT函数,这里我们改个名字:DATEFORMAT
//register the function
tEnv.registerFunction("DATEFORMAT", new DateFormat());
Table table = tEnv.sqlQuery(
"SELECT " +
"visitTime, " +
"DATEFORMAT(max(visitTime), 'HH') as ts, " +
"count(userId) as pv, " +
"count(distinct userId) as uv " +
"FROM visit_table " +
"GROUP BY visitTime");
从UDF函数注册源码看,自定义函数在Table API或SQL API 都可以使用
/**
* Registers a [[ScalarFunction]] under a unique name. Replaces already existing
* user-defined functions under this name.
*/
def registerFunction(name: String, function: ScalarFunction): Unit = {
// check if class could be instantiated
checkForInstantiation(function.getClass)
// register in Table API
functionCatalog.registerFunction(name, function.getClass)
// register in SQL API
functionCatalog.registerSqlFunction(
createScalarSqlFunction(name, name, function, typeFactory)
)
}
执行的结果:
printing result to stdout. Use --output to specify output path.
6> (true,2017-09-16 10:30:00,10,1,1)
4> (true,2017-09-16 09:00:00,09,1,1)
4> (false,2017-09-16 09:00:00,09,1,1)
6> (false,2017-09-16 10:30:00,10,1,1)
4> (true,2017-09-16 09:00:00,09,2,1)
6> (true,2017-09-16 10:30:00,10,2,1)
6> (false,2017-09-16 10:30:00,10,2,1)
6> (true,2017-09-16 10:30:00,10,3,1)
Process finished with exit code 0
我们看下这个结果是什么意思:
Flink RetractStream 用true或false来标记数据的插入和撤回,返回true代表数据插入,false代表数据的撤回,在网上看到一个图很直观地说明RetractStream 为什么存在?
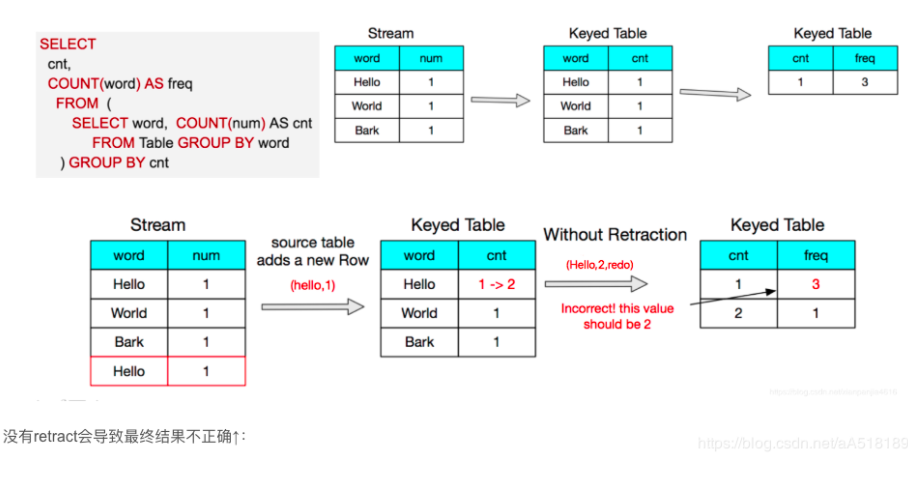
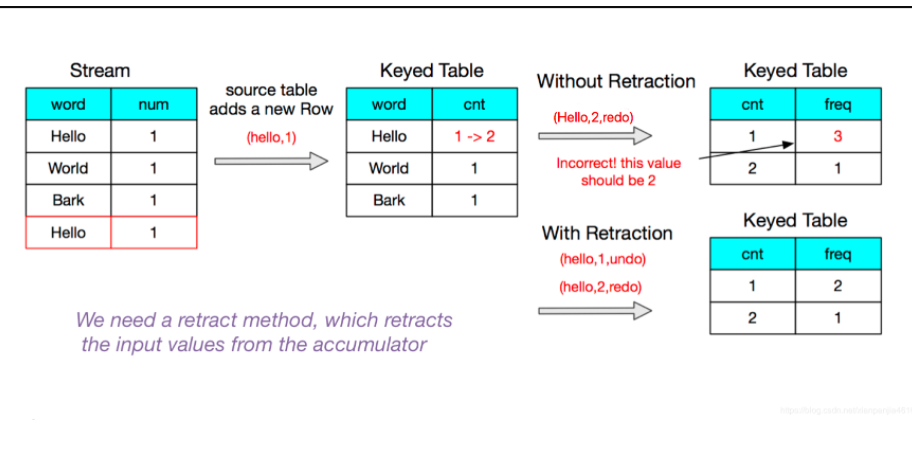
看我们的source数据,9点与10点半的数据刚开始pv,uv都为新增,对应的第二条数据来的时候,pv发生变化, 此时要撤掉第一次的结果,更新为新的结果数据 ,就好比我们有时候更新数据的一种办法先删除再插入,后面到来的数据以此类推。
总结
1.Flink处理数据把表转换为流的时候,可以使用toAppendStream与toRetractStream,前者适用于数据追加的场景, 后者适用于更新,删除场景
2.FlinkSQL中可以使用我们自定义的函数.Flink UDF自定义函数实现:evaluation方法必须定义为public,命名为eval。evaluation方法的输入参数类型和返回值类型决定着函数的输入参数类型和返回值类型。evaluation方法也可以被重载实现多个eval。同时evaluation方法支持变参数,例如:eval(String... strs)。