数据库的基本操作
-
展示所有数据库
-
show databases;
-
-
切换数据库
-
user database_name;
-
-
创建数据库
-
create database database_name;
-
-
删除数据库
-
drop database database_name;
-
-
注意:当进入hive的命令行开始编写SQL语句的时候,如果没有任何相关的数据库操作,那么默认情况下,所有的表存在于default数据库,在hdfs上的展示形式是将此数据库的表保存在hive的默认路径下,如果创建了数据库,那么会在hive的默认路径下生成一个database_name.db的文件夹,此数据库的所有表会保存在database_name.db的目录下。
数据库表的基本操作
-
基本语法:
-
创建语句:
-
创建普通hive表(不包含行定义格式)
create table psn ( id int, name string, likes array<string>, address map<string,string> ) 对应的数据 1^A小王^A苹果^B香蕉^B橘子^Aa^Caa^Bb^Cbb^Bc^Ccc (蓝色^A=,(CTRL+V,CTRL+A) 蓝色^B=-(CTRL+V,CTRL+B) 蓝色^C=:(CTRL+V,CTRL+C)) 上传(local从你linux本地加载数据先上传到hdfs上,不加就是从hdfs拿取数据) load data local inpath '/tmp/data/data' into table psn; 问题:为什么load快? 因为load是从hdfs获取数据,直接move移动过来 -
创建自定义行格式的hive表
create table psn2 ( id int, name string, likes array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; 对应的数据: 1,小王,苹果-香蕉-橘子,a:aa-b:bb-c:cc 2,小王,苹果-香蕉-橘子,a:aa-b:bb-c:cc 3,小王,苹果-香蕉-橘子,a:aa-b:bb-c:cc 4,小王,苹果-香蕉-橘子,a:aa-b:bb-c:cc 通过正常的insert太慢了,使用文件上传模式 方式1.hdfs dfs -put data2 /user/hive_remote/warehouse/psn2 方式2.在hive中上传虚拟机本机文件:load data local inpath '/tmp/data/data' into table psn2; -
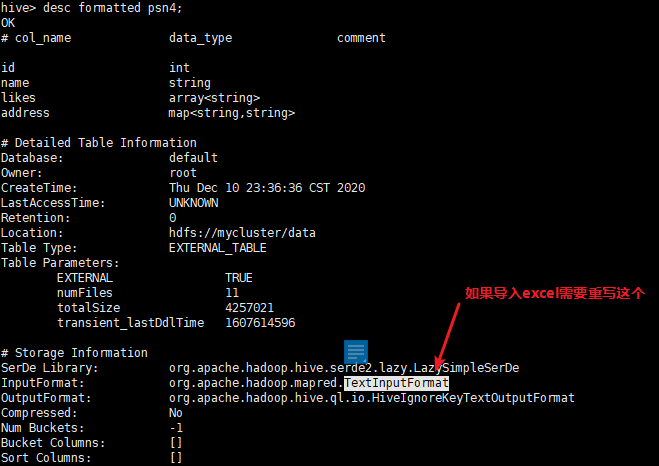
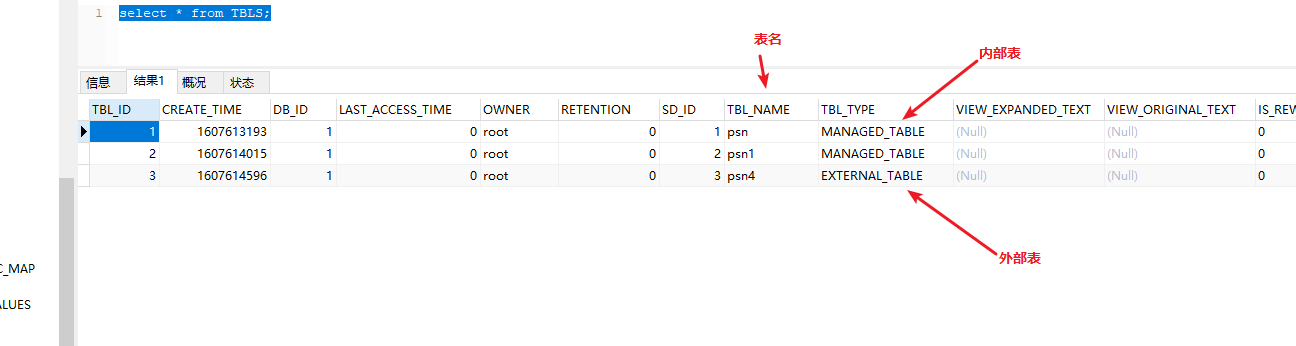
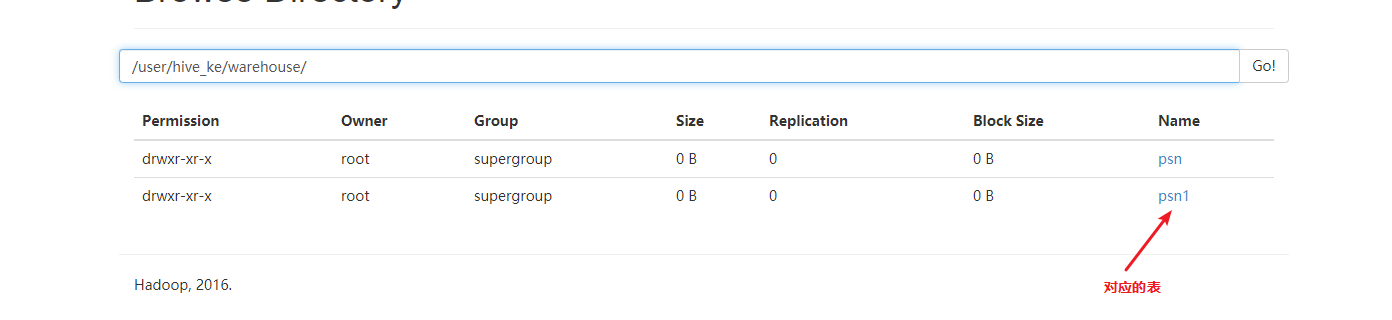
创建hive的外部表(需要添加external和location的关键字)
create external table psn4 ( id int, name string, likes array<string>, address map<string,string> ) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' location '/data'; 内部表和外部表区别 hive在默认情况下创建的是内部表,外部表创建的时候需要制定external的关键字同时需要制定location(制定存储目录) 内部表在进行删除的时候,将数据和元数据全部删除,外部表再删除的时候只会删除元数据,不会删除数据。 应用场景 内部表:先创建表,再添加数据。 外部表:可以先创建表再添加数据,也可以先添加数据,在创建表。(因为hive是读时检查,不是mysql那种写时检查) - 创建单分区表(partitioned by)
create table psn5( id int, name string, likes array<string>, address map<string, string>) partitioned by(gender string) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; -- 添加分区 alter table psn5 add partition(gender='one') alter table psn5 add partition(gender='two')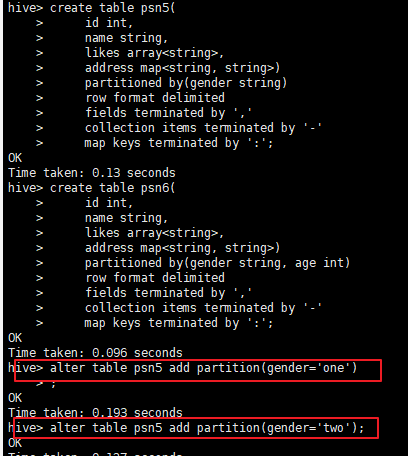

-
创建多分区表(partitioned by)
create table psn6( id int, name string, likes array<string>, address map<string, string>) partitioned by(gender string, age int) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':'; -- 添加分区 alter table psn6 add partition(gender='one', age=10); alter table psn6 add partition(gender='two', age=10); -- 添加数据 load data local inpath '/tmp/data/data' into table psn2 partition(gender='one'; 注意: 0、gender也是一列字段 1、当创建完分区表之后,在保存数据的时候,会在hdfs目录中看到分区列会成为一个目录,以多级目录的形式存在 2、当创建多分区表之后,插入数据的时候不可以只添加一个分区列,需要将所有的分区列都添加值 3、多分区表在添加分区列的值得时候,与顺序无关,与分区表的分区列的名称相关,按照名称就行匹配 分区注意: 1、添加分区列的值的时候,如果定义的是多分区表,那么必须给所有的分区列都赋值 2、删除分区列的值的时候,无论是单分区表还是多分区表,都可以将指定的分区进行删除(输入一个分即可删除) 问题: 1.当数据进去hive的时候,需要根据数据的某一个字段向hive表插入数据,此时无法满足需求,因此需要使用动态分区。 - 修复分区
--在hdfs创建目录并上传文件 hdfs dfs -mkdir /msb hdfs dfs -mkdir /msb/age=10 hdfs dfs -mkdir /msb/age=20 hdfs dfs -put /root/data/data /msb/age=10 hdfs dfs -put /root/data/data /msb/age=20 --创建外部表 create external table psn7 ( id int, name string, likes array<string>, address map<string,string> ) partitioned by(age int) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' location '/msb'; --查询结果(没有数据) select * from psn7; --修复分区 msck repair table psn7; --查询结果(有数据) select * from psn7; 问题: 1.以上面的方式创建hive的分区表会存在问题,每次插入的数据都是人为指定分区列的值,我们更加希望能够根据记录中的某一个字段来判断将数据插入到哪一个分区目录下,此时利用我们上面的分区方式是无法完成操作的,需要使用动态分区来完成相关操作。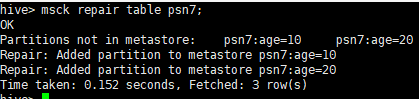
-
动态分区
from testb insert overwrite table testa partition(create_time) select id,name,area,create_time distribute by create_time; 注意: 1.testb查询必须带上分区 2. distribute by create_time;可以省略 3.hive.exec.dynamici.partition=true; #开启动态分区,默认是false 4. set hive.exec.dynamic.partition.mode=nonstrict; #开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
- 根据分区查询
hive> select * from testb where create_time = '2021-07-02'; OK 1 zy1 SZ 1001 2021-07-02 2 zy2 SH 1002 2021-07-02 3 zy3 HZ 1003 2021-07-02 4 zy4 QD 1004 2021-07-02 5 zy5 SR 1005 2021-07-02
- 插入数据总结
- load方式
解释: --加载本地数据到hive表 load data local inpath '/root/data/data' into table psn;--(/root/data/data指的是本地 -- linux目录) --加载hdfs数据文件到hive表 load data inpath '/data/data' into table psn;--(/data/data指的是hdfs的目录) 注意: 1、load操作不会对数据做任何的转换修改操作 2、从本地linux load数据文件是复制文件的过程 3、从hdfs load数据文件是移动文件的过程 4、load操作也支持向分区表中load数据,只不过需要添加分区列的值 - insert
insert into psn values(1,'zhangsan') 会在mapreduce中生成任务 - insert-select
--注意:这种方式插入数据的时候需要预先创建好结果表 --从表中查询数据插入结果表 INSERT OVERWRITE TABLE psn9 SELECT id,name FROM psn - insert-select-many
--从表中获取部分列插入到新表中 from psn insert overwrite table psn9 select id,name insert into table psn10 select id - overwrite directory
--注意:路径千万不要填写根目录,会把所有的数据文件都覆盖 --将查询到的结果导入到hdfs文件系统中 insert overwrite directory '/result' select * from psn; --将查询的结果导入到本地文件系统中 insert overwrite local directory '/result' select * from ps
-
注意:
- Hive依赖于HDFS,理论上是不能进行删除、修改数据,只能增加不断的append数据。 但是Hive官网提供了修改、删除数据的方式,需要开启事务、增加许多配置,并不是修改原来的数据,而是在原来的数据上新增加一份数据,干掉之前的。
- 所有的hive-sql操作都是MR操作,之所以查询快是HIVE做了优化
- hive也可以导入excel