反爬
网上网页的反爬手段千奇百怪,常见的有ip封锁,动态加载数据,链接加密,验证码登录等等,最近碰到一个之前没见到过的反爬手段:字体反爬。情况如图:
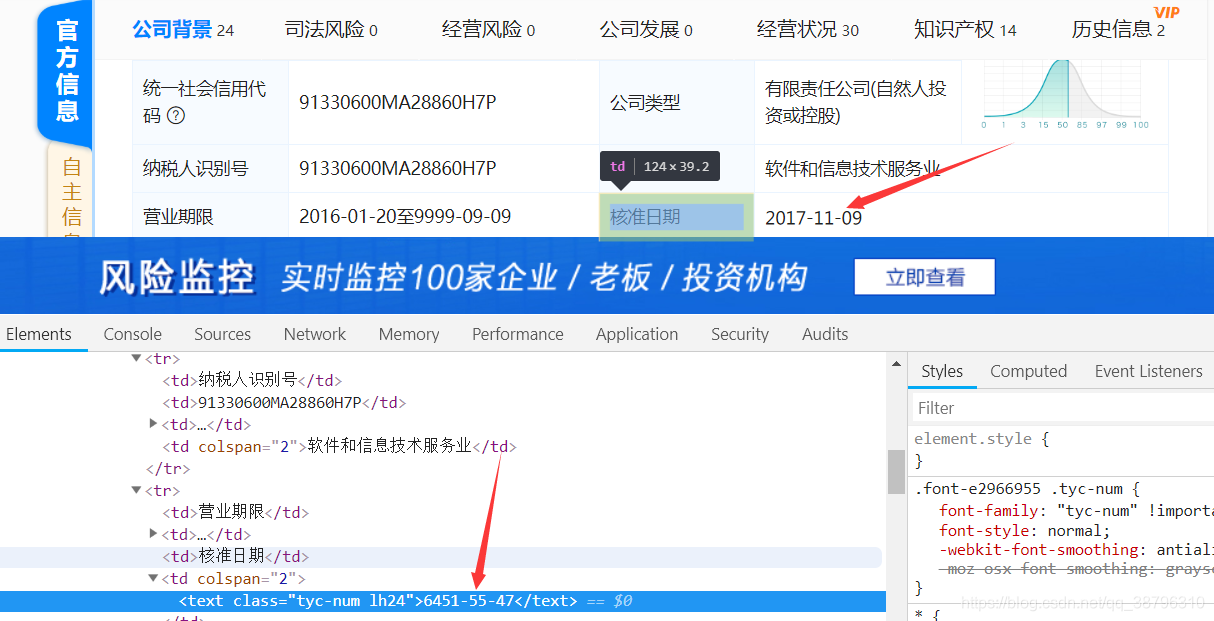
箭头所示的标签为同一个数据。可以清楚的看到页面上的日期与源码中的日期不一致。这就是字体反爬,下载页面中的字体文件通过百度的字体编辑器可以看到数字的对应关系。
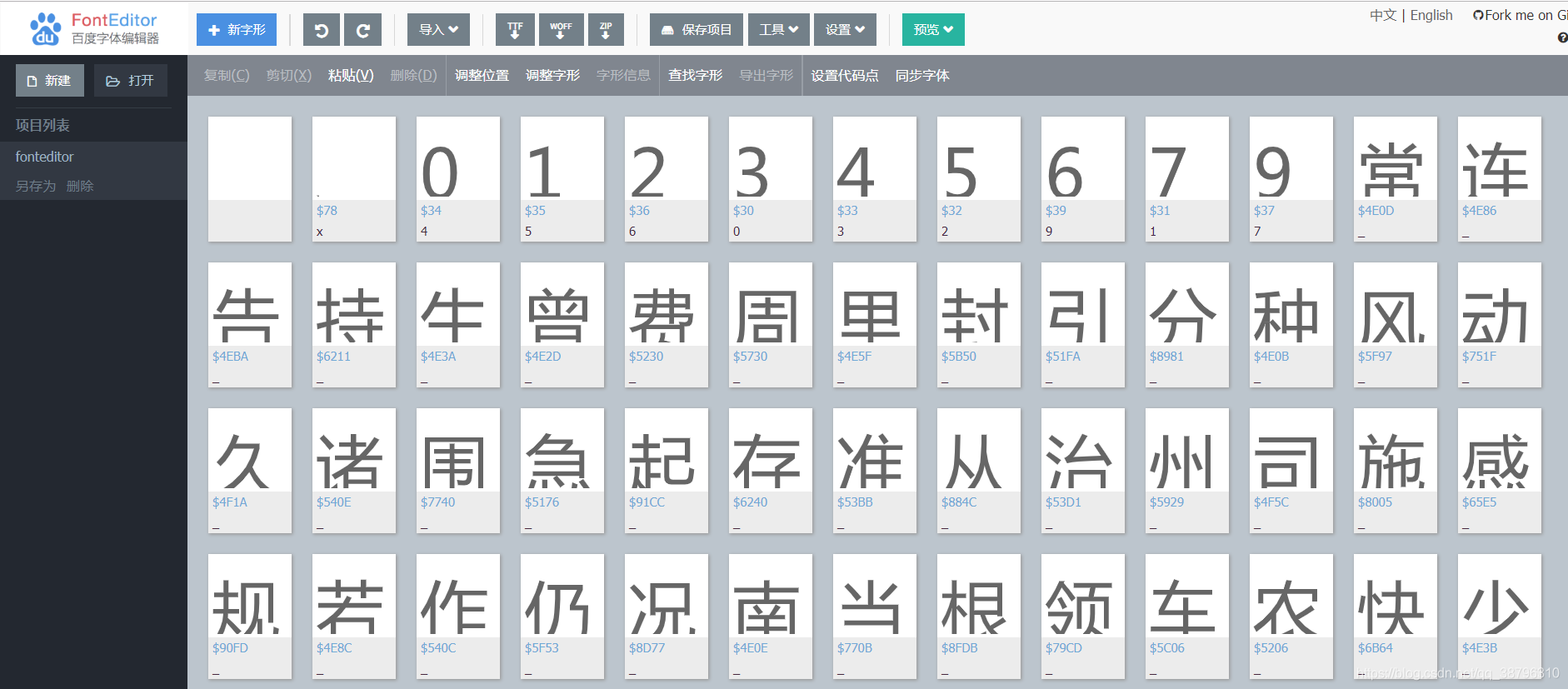
fonttools
fonttools为python的一个第三方库,可以使用该库打开并读取字体文件。
通过pip安装
pip install fonttools
下载字体文件
可以从网页源码中获取字体文件的下载地址,将其下载到本地后使用代码打开并读取所需信息
from fontTools.ttLib import TTFont
Font = TTFont('tyc-num.woff') # 加载字体文件
code = {}
for i in range(10):
try:
uni_list = Font.getGlyphID(str(i))
code[str(i)] = str(uni_list - 2) #生成对应编码表
except:
pass
str1 = '6451-55-47'
new_str = ''
for i in str1:
if i =="-":
new_str += '-'
try:
if i in code.keys():
new_str += code[i]
except:
pass
print(new_str)
运行代码,即可得到对应的真正日期。

该代码只作为笔者学习之用。