前言
很多人估计都听过哈希,顾名思义,一般程序的直接反映就是做映射的嘛,哈希算法,当然这不是今天本文所讲的重点,今天主要所讲的是另外一个名词,一致性哈希算法,光从字面上的意思想,这一定是对于原有算法的一个改进了。
Hash
我们先从最简单的hash方法开始说起,哈希方法可以有很多种类型,字符串哈希,数值类型的哈希,实体类的哈希,其实这些都可以统称为对象的哈希,用一个方法就可以表示就是hashcode()方法,在java里反正是存在的,其他的语言是不是这么写我确实还不太清楚。一般哈希方法常用来做一种关系映射,然后进行分配的,最终起到一个均匀分配,负载均衡的目的,这个在很多开源代码中都会有类似这样的实现。但是这其中会存在一个隐患,举个例子,若干个对象分配到若干个机器节点上,首先使用规范的哈希映射再%N,效果还不错,差不多均匀分配,但是突然有一天有个机器挂了,那么问题大了,很多的映射就会不准了,因为N变了。为了保持住原有的一致性,因此提出了一致性哈希算法。
一致性哈希
一致性哈希算法的提出是在由麻省理工学院在1997年提出的,旨在解决因特网中的Hot Spot热点问题的。一致性哈希算法在不改变原有的哈希算法的前提下,提出了哈希环的概念,将对象和机器映射到一个0~2的31次方的数值,然后假想数字是一个从小到大的患空间,对象的分配方式是以顺时针方向,离对象最近的机器就是对象所分配的机器节点。用图形表示就是下面这个样子:
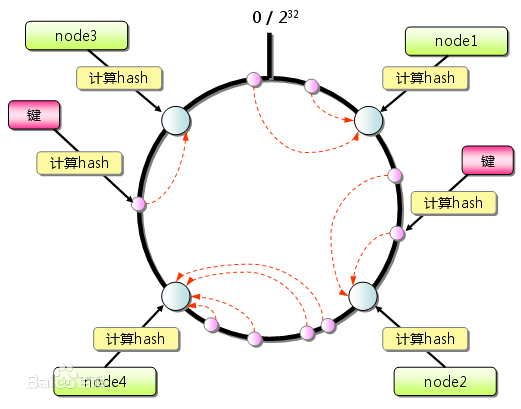
这样就好理解多了吧。这样就能够很好的解决之前的问题了,机器的删除和添加只会影响到个别节点,其余的对象分配依然是不变的。
虚拟节点
上述的哈希环的方式看起来已经非常的完美了,不过还是有可能会造成一个问题,节点分配不均衡,导致对象的分配不均衡,经过多次的节点的添加,删除,可能左半环的节点数量,明显多于右半边的节点数,这个时候有没有什么改进的方案呢,答案是有,用虚拟节点表示,相当于每个节点有replication副本数的概念,每个机器的副本可以用ip或机器名+数字后缀的形式进行哈希映射,详细可以参见后面我的代码实现。效果图是下面这个样子:
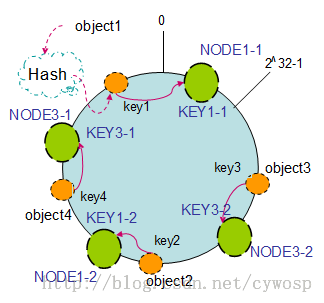
代码实现
全部代码链接在此:https://github.com/linyiqun/lyq-algorithms-lib/tree/master/ConsistentHash
下面给出核心的算法实现ConsistentHashTool.java(hashcode映射时偶尔会有越界的情况发生):
package ConsistentHash;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.text.MessageFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
/**
* 一致性哈希算法工具类
*
* @author lyq
*
*/
public class ConsistentHashTool {
// 机器节点信息文件地址
private String filePath;
// 每个节点虚拟节点的个数
private int virtualNodeNum;
// 测试实体对象列表
private ArrayList<Entity> entityLists;
// 节点列表
private ArrayList<Node> totalNodes;
// 结果分配列表
private HashMap<Entity, Node> assignedResult;
public ConsistentHashTool(String filePath, int virtualNodeNum,
ArrayList<Entity> entityLists) {
this.filePath = filePath;
this.virtualNodeNum = virtualNodeNum;
this.entityLists = entityLists;
readDataFile();
}
/**
* 从文件中读取数据
*/
private void readDataFile() {
File file = new File(filePath);
ArrayList<String[]> dataArray = new ArrayList<String[]>();
try {
BufferedReader in = new BufferedReader(new FileReader(file));
String str;
String[] tempArray;
while ((str = in.readLine()) != null) {
tempArray = str.split(" ");
dataArray.add(tempArray);
}
in.close();
} catch (IOException e) {
e.getStackTrace();
}
Node node;
String name;
String ip;
long hashValue;
this.totalNodes = new ArrayList<>();
// 解析出每行的节点名称和ip地址
for (String[] array : dataArray) {
name = array[0];
ip = array[1];
// 根据IP地址进行hash映射
hashValue = ip.hashCode();
node = new Node(name, ip, hashValue);
this.totalNodes.add(node);
}
// 对节点按照hashValue值进行升序排列
Collections.sort(this.totalNodes);
}
/**
* 哈希算法分配对象实例
*/
public void hashAssigned() {
Node desNode;
this.assignedResult = new HashMap<>();
for (Entity e : this.entityLists) {
desNode = selectDesNode(e, this.totalNodes);
this.assignedResult.put(e, desNode);
}
outPutAssginedResult();
}
/**
* 通过虚拟节点的哈希算法分配
*/
public void hashAssignedByVirtualNode() {
String name;
String ip;
long hashValue;
// 用以生成随机数数字后缀
Random random;
Node node;
ArrayList<Node> virtualNodes;
random = new Random();
// 创建虚拟节点
virtualNodes = new ArrayList<>();
for (Node n : this.totalNodes) {
name = n.name;
ip = n.ip;
// 复制虚拟节点个数
for (int i = 0; i < this.virtualNodeNum; i++) {
// 虚拟节点的哈希值用ip+数字后缀的形式生成
hashValue = (ip + "#" + (random.nextInt(1000) + 1)).hashCode();
node = new Node(name, ip, hashValue);
virtualNodes.add(node);
}
}
// 进行升序排序
Collections.sort(virtualNodes);
// 哈希算法分配节点
Node desNode;
this.assignedResult = new HashMap<>();
for (Entity e : this.entityLists) {
desNode = selectDesNode(e, virtualNodes);
this.assignedResult.put(e, desNode);
}
outPutAssginedResult();
}
/**
* 在哈希环中寻找归属的节点
*
* @param entity
* 待分配的实体
* @param nodeList
* 节点列表
* @return
*/
private Node selectDesNode(Entity entity, ArrayList<Node> nodeList) {
Node desNode;
int hashValue;
desNode = null;
hashValue = entity.hashCode();
for (Node n : nodeList) {
// 按照顺时针方向,选择一个距离最近的哈希值节点
if (n.hashValue > hashValue) {
desNode = n;
break;
}
}
// 如果没有找到说明已经超过最大的hashValue,按照环状,被划分到第一个
if (desNode == null) {
desNode = nodeList.get(0);
}
return desNode;
}
/**
* 输出分配结果
*/
private void outPutAssginedResult() {
Entity e;
Node n;
for (Map.Entry<Entity, Node> entry : this.assignedResult.entrySet()) {
e = entry.getKey();
n = entry.getValue();
System.out.println(MessageFormat.format("实体{0}被分配到了节点({1}, {2})",
e.name, n.name, n.ip));
}
}
}
参考文献
百度百科
http://blog.csdn.net/cywosp/article/details/23397179/