前言
在分布式集群运行环境中,磁盘损坏是极为司空见惯的事情。损坏的一个直接影响是系统少了一个可用空间,同时也意味着上面存储数据的损坏。而对于这样磁盘的损坏,它分别对于存储系统和计算系统的影响并不相同。同样的,对于坏盘和处理逻辑,也未必是相同的。本文,笔者来聊聊Hadoop中HDFS,YARN模块分别对于此的处理过程。
磁盘损坏的定义
当我们说一个磁盘损坏了,我们的定义标准是如何的呢?
我们先暂不考虑硬件层面的检测标准,光从软件层面来考虑的话,我们一般有以下这样的标准:
1)文件无法被创建
2)已有文件无法被访问
基于这两点,系统一般会采用在目标目录下写一个简单的文件数据,然后尝试是否能获取文件的状态来进行基本的测试。
OK,下面我们进入本文的主题内容。
HDFS(存储系统)的磁盘检测
相比于计算系统,存储系统会更大规模的使用到磁盘作为数据存储的介质。当有磁盘损坏时,系统理性具有更高的敏感性,及时将上面丢失的数据replicate到其它节点上。
以此为基本原则,HDFS采用了一种异常触发的机制,当遇到以下读写数据异常时,存储节点会触发一次磁盘检测逻辑:
1)客户端读写数据抛出异常。
2)系统进行常规数据完整性检查行为时,发生读数据异常。
3)物理数据文件与系统文件元数据信息不一致的情况
以上3类情况并不是一定说是磁盘损坏导致,只是说大概率是此原因所致。
但系统确实检测出磁盘为坏盘时,它将会把盘移到坏盘列表内,不再允许此盘继续提供读写数据服务。但是HDFS在这里没有完全做到自动磁盘恢复的处理,只是提供了手动刷新磁盘的外部命令,来告诉系统恢复的磁盘。HDFS的磁盘检测流程图如下:

YARN(计算系统)的磁盘检测
YARN作为一个计算系统,它对于磁盘的使用程度没有存储系统高。它主要依赖磁盘存2类数据:
1)本地目录,存储诸如用户应用jar包,resource文件。
2)日志目录,应用日志数据。
相比较于存储系统对于数据高可用的保障要求,计算系统的要求就低很多了。YARN采用的是一种周期性检测的方式,然后将检测结果push到中心控制服务(即ResourceManager),然后由RM做handle处理。
在磁盘检测的逻辑中,YARN不仅做了磁盘的常规检测操作之外,还提供了允许额外健康脚本执行的方式。这个健康检测脚本由用户编写提供,这点上做的确实比HDFS更加灵活一些。综合这2个结果,NM将整合好的health report汇报给了RM。
YARN的磁盘检测过程如下图所示:
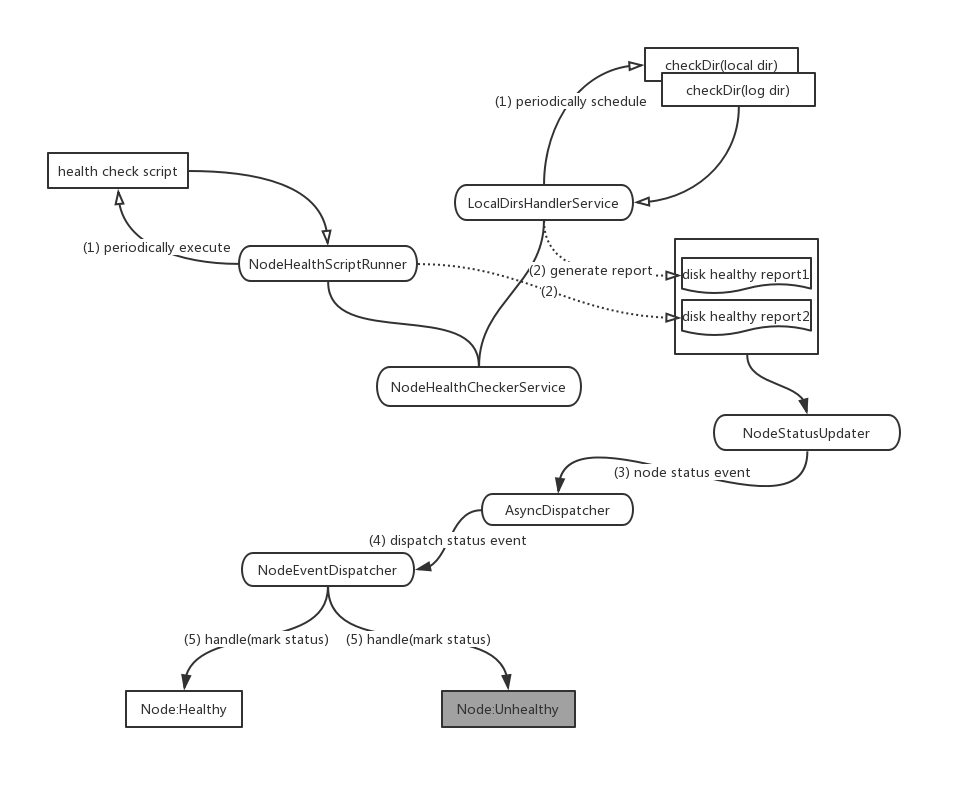
YARN内部大量采用了Event-Dispatch的方式来做处理,所以我们可以看到里面基本是以event作为主要的信息源。
附注:YARN AsyncDispatcher的内部细节流程
AsyncDispatcher实现主要基于以下几点:
- 采用了Queue的缓冲处理方式,增大处理的throughput。
- 通过不同的handler<Evenr, EventHandler>的注册,使Dispatcher分别派发对应Type的Event给Handler处理。
