2017-2018-1 201552228 《信息安全系统设计基础》第十三周学习总结
关于本篇博客的基本介绍
在《信息安全系统设计基础》课程即将结束之际,翻阅教材回顾一学期所学知识,个人感觉进程的并发是很重要的。
并发,在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
为什么我会这么认为呢?原因有以下两点
-
并发对于现代操作系统来说是至关重要的。即使是现在的计算机可以拥有多个处理器,并发还是在计算机操作系统中占有不可或缺的地位。理解并发的原理对理解计算机系统如何工作有着很大的帮助。
-
并发广泛地应用于各种程序的开发中。无论是序列密码算法的程序设计还是网络编程的web开发,并发都是绕不开的问题,也许有时候并发只是影响程序的效率,但是有时候并发却是编程的核心,不能很好地解决并发,算法的实现也是无从谈起。
通览全书,涉及进程的内容主要集中在第八章异常流控制和第十二章并发编程,前者侧重于并发在计算机操作系统中的实现,后者侧重于并发在程序开发过程的应用。当然并发的相关内容还在其他章节汇总有提到,比如说第九章虚拟内存中对fork和execve函数的讨论,第十一章网络编程的迭代服务器是并发服务器的基础等等。
本篇博客主要是把第九章和第十二章中涉及到并发的内容进行学习总结,以教材的脉络为基础,引入来自网络上相关知识点的补充,并加入自己的理解,再把练习题做个分析,希望能更系统更深入地理解并发,这就是写这篇博客的目标

教材学习内容总结
进程和进程控制
进程的上下文和上下文切换
进程的经典定义就是一个执行中程序的实例。
系统中的每个程序都运行在某个进程的上下文(context)中。上下文是由程序正确运行所需的状态组成的。这个状态包括存放在内存中的程序的代码和数据,它的栈、通用目的寄存器的内容、程序计数器、环境变量以及打开文件描述符的集合。
context这个东西不是一个具体的东西,在不同的地方表示不同的含义...其实说白了,和文章的上下文是一个意思,再通俗一点,叫环境更好。
一篇文章,给你摘录一段,没前没后,你读不懂,因为有语境,就是语言环境存在,一段话说了什么,要通过上下文(文章的上下文)来推断。子程序之于程序,进程之于操作系统,甚至app的一屏之于app,都是一个道理。
程序执行了部分到达子程序,子程序要获得结果,要用到程序之前的一些结果(包括但不限于外部变量值,外部对象等等)。
这个典型例子,理解成环境就可以,而且上下文虽然叫上下文,但是程序里面一般都只有上文而已,只是叫的好听叫上下文,进程中断在操作系统中是有上有下的。
在进程执行的某些时刻,内核可以决定抢占当前进程,并重新开始一个先前被抢占了的进程。这种决策就叫做调度(scheduling),是由内核中称为调度器(scheduler)的代码处理的。
调度器的任务是控制协调进程对CPU的竞争,即按一定的调度算法从就绪队列中选中一个进程,把CPU的使用权交给被选中的进程。
调度的层次
作业从进入系统成为后备作业开始,直到运行结束退出系统为止,需经历不同级别的调度:
- 高级调度(长程调度),又称宏观调度、作业调度:作业调度,决定哪些位于外存上、处于后备状态的作业调入内存,并为它创建进程,分配必要的资源,准备运行
- 中级调度(中程调度),又称交换调度:进程交换,决定哪些进程可参与竞争CPU目的:提高内存的利用率和系统的吞吐量操作:换进(激活);换出(挂起)
- 低级调度(短程调度),又称微观调度、进程调度:进程调度,决定哪个进程可以获得CPU

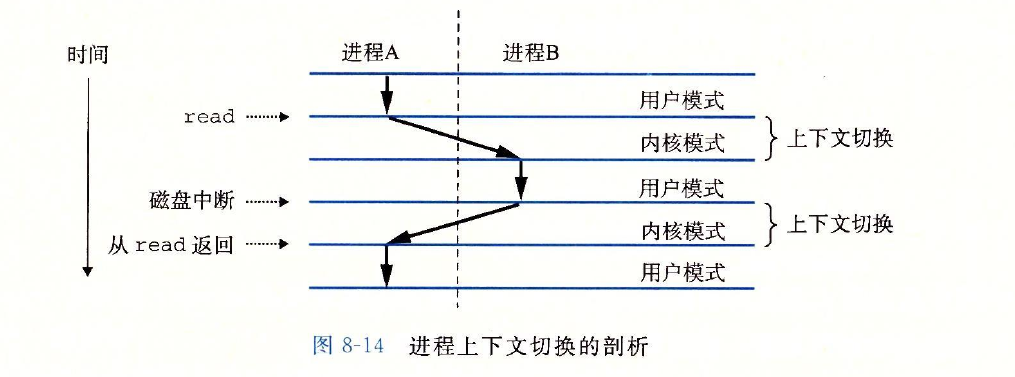
操作系统内核使用一种称为上下文切换(context switch)的较高层形式的异常控制流来实现多任务。
当内核选择一个新的进程运行时,就是指内核调度了这个进程。在内核调度了一个新的进程运行后,它就抢占当前进程,并使用一种称为上下文切换的机制来将控制转移到新的进程。
上下文切换的过程
- 保存当前进程的上下文;
- 恢复某个先前被抢占的进程被保存的上下文;
- 将控制传递给这个新恢复的进程。
逻辑控制流和并发流
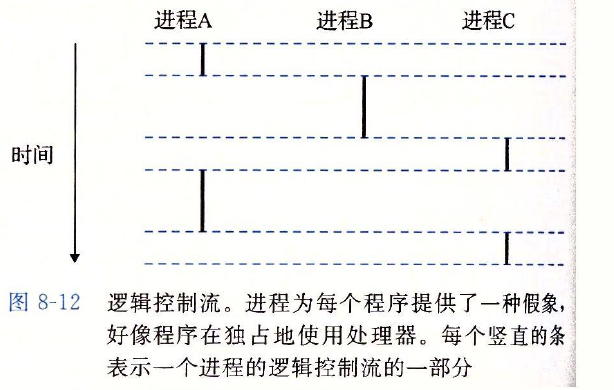
即使在系统中通常有许多程序在运行,进程也可以向每个程序提供一种假象,好像它在独占地使用处理器。如果用调试器单步执行程序,会看到一系列的程序计数器(PC)的值,这些值唯一地对应于包含在程序的可执行目标文件中的指令,或是包含在运行时动态链接到程序的共享对象中的指令。这个PC值的序列叫做逻辑控制流,或者简称逻辑流。
一个逻辑流的执行在时间上与另一个流重叠,称为并发流(concurrent flow),这两个流被称为并发地运行。更准确地说,流X和Y互相并发,当且仅当X在Y开始之后和Y结束之前开始,或者Y在X开始之后和X结束之前开始。例如,图8-12中,进程A和B并发地运行,A和C也一样。另一方面,B和C没有并发地运行,因为B的最后一条指令在C的第一条指令之前执行。
多个流并发地执行的一般现象被称为并发(concurrency)。一个进程和其他进程轮流运行的概念称为多任务(multitasking)。一个进程执行它的控制流的一部分的每一时间段叫做时间片(time slice)。因此,多任务也叫做时间分片(time slicing)。例如图中,进程A的流由两个时间片组成。
并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。倘若在计算机系统中有多个处理机,则这些可以并发执行的程序便可被分配到多个处理机上,实现并行执行,即利用每个处理机来处理一个可并发执行的程序,这样,多个程序便可以同时执行。
练习题8.1
考虑三个具有下述起始和结束时间的进程:
| 进程 | 起始时间 | 终止时间 |
|---|---|---|
| A | 0 | 2 |
| B | 1 | 4 |
| C | 3 | 5 |
对于每对进程,指出它们是否是并发地运行:
| 进程对 | 并发的? |
|---|---|
| AB | |
| BC | |
| AC |
判断标准:一个逻辑流的执行在时间上与另一个流重叠,称为并发流(concurrent flow),这两个流被称为并发地运行。更准确地说,流X和Y互相并发,当且仅当X在Y开始之后和Y结束之前开始,或者Y在X开始之后和X结束之前开始。
题目分析:进程A和B是互相并发的,就像B和C一样,因为它们各自的执行是重叠的,也就是一个进程在另一个进程结束前开始。进程A和C不是并发的,因为它们的执行没有重叠;A在C开始之前就结束了。
私有地址空间和用户模式
进程为每个程序提供它自己的私有地址空间,形成一种假象,好像进程独占地使用系统地址空间。一般而言,和这个空间中某个地址相关联的那个内存字节是不能被其他进程读或者写的,从这个意义上说,这个地址空间是私有的。
处理器提供一种机制,限制一个应用可以执行的指令以及它可以访问的地址空间范围。处理器通常是用某个控制寄存器中的一个模式位(mode bit)来提供这种功能的,没有设置模式位时,进程就运行在用户模式中。
用户模式中的进程不允许执行特权指令(privileged instruction),比如停止处理器、改变模式位,或者发起一个I/O操作。也不允许用户模式中的进程直接引用地址空间中内核区内的代码和数据。
进程控制
获取进程ID
每个进程都有一个唯一的正数(非零)进程ID(PID)。getpid函数返回调用进程的PID,getppid函数返回它的父进程的PID(创建调用进程的进程)。
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
//getpid和getppid函数返回一个类型为pid_t的整数值,在Linux系统上它在types.h中被定义为int
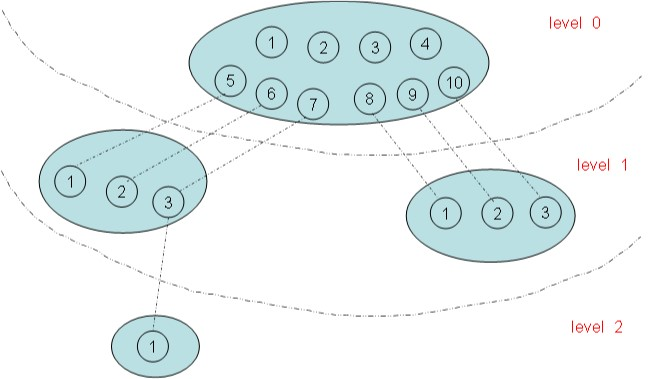
在上图有四个命名空间,一个父命名空间衍生了两个子命名空间,其中的一个子命名空间又衍生了一个子命名空间。以PID命名空间为例,由于各个命名空间彼此隔离,所以每个命名空间都可以有 PID 号为 1 的进程;但又由于命名空间的层次性,父命名空间是知道子命名空间的存在,因此子命名空间要映射到父命名空间中去,因此上图中 level 1 中两个子命名空间的六个进程分别映射到其父命名空间的PID 号5~10。
创建进程
父进程通过调用fork函数创建一个新的运行的子进程
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
-
关于返回值。fork函数,它只被调用一次,却会返回两次:一次是在调用进程(父进程)中,一次是在新创建的子进程中。在父进程中,fork返回子进程的PID。在子进程中,fork返回0。因为子进程的PID总是为非零,返回值就提供一个明确的方法来分辨程序是在父进程还是在子进程中执行。
-
关于fork的并发执行。父进程和子进程是并发运行的独立进程。内核能够以任意方式交替执行它们的逻辑控制流中的指令。一般而言,作为程序员,我们决不能对不同进程中指令的交替执行做任何假设。
-
关于父进程和子进程的相同点和不同点。新创建的子进程几乎但不完全与父进程相同。子进程得到与父进程用户级虚拟地址空间相同的(但是独立的)一份副本,包括代码和数据段、堆、共享库以及用户栈。父进程和新创建的子进程之间最大的区别在于它们有不同的PID。
父进程和子进程有相同但是独立的地址空间。每个进程有相同的用户栈、相同的本地变量值、相同的堆、相同的全局变量值,以及相同的代码。然而父进程和子进程是独立的进程,它们都有自己的私有地址空间,父进程和子进程对变量所做的任何改变都是独立的,不会反映在另一个进程的内存中。也就是说父进程和子进程调用变量对于同一个变量可以有会有不同的值。
总结起来,父进程调用fork函数会得到一个几乎与进程相同的子进程,由于代码相同,子进程中也有调用fork的语句,但是子进程不会新建进程而是直接返回0,而对于父进程来说,调用fork返回的值是子进程的PID(PID不为0),这可以用来区分父进程和子进程。父进程和子进程是相互独立的,不会互相影响。

Linux Programmer's ManualLinux程序员手册:FORK(2)
FORK(2)
NAME名称
fork - create a child process创建一个子进程
SYNOPSIS概要
#include <unistd.h>
pid_t fork(void);
DESCRIPTION描述
fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.
fork()通过复制调用过程来创建一个新的过程。新进程被称为子进程。调用过程被称为父进程。
The child process and the parent process run in separate memory spaces.At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect the other.
子进程和父进程在不同的内存空间中运行。在fork()的时候,两个内存空间都有相同的内容。由其中一个进程执行的内存写入,文件映射(mmap(2))和取消映射(munmap(2))不会影响另一个进程。
The child process is an exact duplicate of the parent process except for the following points:
子进程与父进程完全相同,除了以下几点:
* The child has its own unique process ID, and this PID does not match the ID of any existing process group (setpgid(2)).
孩子有自己独特的进程ID,并且这个PID不匹配任何现有进程组(setpgid(2))的ID。
* The child's parent process ID is the same as the parent's process ID.
孩子的父进程ID与父进程ID相同。
Note the following further points:
请注意以下几点
* The child process is created with a single thread—the one that called fork(). The entire virtual address space of the parent is replicated in the child, including the states of mutexes, condition variables, and other pthreads objects; the use of pthread_atfork(3) may be helpful for dealing with problems that this can cause.
子进程是使用一个线程创建的,即一个调用fork()的线程。父项的整个虚拟地址空间被复制到子项中,包括互斥锁,条件变量和其他pthreads对象的状态;使用pthread_atfork(3)可能有助于处理这可能导致的问题。
* After a fork(2) in a multithreaded program, the child can safely call only async-signal-safe functions (see signal(7)) until such time as it calls execve(2).
多线程程序中的fork(2)之后,孩子可以安全地只调用异步信号安全函数(请参见signal(7)),直到调用execve(2)为止。
RETURN VALUE返回值
On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.
成功时,子进程的PID在父进程中返回,并且在子进程中返回0。 如果失败,则在父项中返回-1,不创建子进程,并且适当地设置errno。
NOTES注释
Under Linux, fork() is implemented using copy-on-write pages, so the only penalty that it incurs is the time and memory required to duplicate the parent's page tables, and to create a unique task structure for the child.
在Linux下,fork()是通过使用写时复制页面来实现的,所以唯一的代价就是复制父页表所需的时间和内存,并且创建一个独特的子任务结构。
终止进程
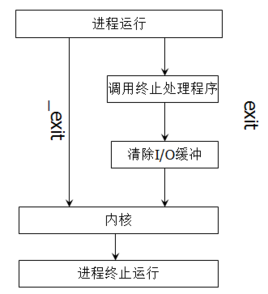
调用exit函数以status退出状态来终止进程
#include <stdlib.h>
void exit(int status)
exit(0)表示正常退出,exit(x)(x不为0)都表示异常退出,这个x是返回给操作系统(包括UNIX,Linux,和MS DOS)的,以供其他程序使用。
练习题8.2
考虑下面的程序:
int main()
{
int x=1
if (Fork()==0)
printf("pi:x=%d
",++x);
printf("p2:x=%d
",--x);
exit (0);
}
A.子进程的输出是什么?
B.父进程的输出是什么?
运行子进程时,fork的返回值为0,满足if的条件,所以会有x+1再x-1,而父进程因为fork的返回值不为0,不满足if条件,只有x-1,而对于父进程和子进程来说,x在开始时都是1
在这个程序中,父子进程执行的指令集合是相关的,因为父子进程有相同的代码段。
A.这里的关键点是子进程执行了两个printf语句。在fork返回之后,它执行第6行的printf然后它从if语句中出来,执行第7行的printf语句。下面是子进程产生的输出:
p1:x=2
p2:x=1
B.父进程只执行第7行的printf:
p2: x=0
回收子进程
一个进程可以通过调用waitpid函数来等待它的子进程终止或者停止。
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *statusp,int options)
- 关于参数
pid_t pid
| 取值 | 解释 |
|---|---|
| pid>0 | 等待集合就是一个单独的子进程,它的进程ID等于pid |
| pid=-1 | 等待集合就是由父进程所有的子进程组成的 |
等待集合是指父进程调用的waitpid函数考察的子进程的集合,也就是说waitpid函数会等待等待集合中的进程的终止
- 关于参数
int *statusp
| 取值 | 解释 |
|---|---|
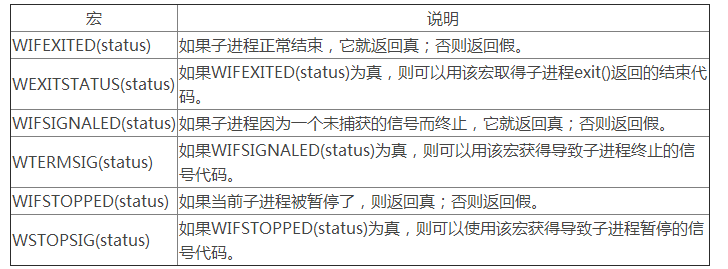
| WIFEXITED | 如果子进程通过调用exi七或者一个返回(return)正常终止,就返回真。 |
| WEXITSTATUS | 返回一个正常终止的子进程的退出状态。只有在WIFEXITED()返回为真时,才会定义这个状态。 |
| WIFSIGNALED | 如果子进程是因为一个未被捕获的信号终止的,那么就返回真。 |
| WTERMSIG | 返回导致子进程终止的信号的编号。只有在WIFSIGNALED()返回为真时,才定义这个状态。 |
| WIFSTOPPED | 如果引起返回的子进程当前是停止的,那么就返回真。 |
| WSTOPSIG | 返回引起子进程停止的信号的编号。只有在WIFSTOPPED ( )返回为真时,才定义这个状态。 |
| WIFCONTINUED | 如果子进程收到SIGCONT信号重新启动,则返回真。 |
如果statusp参数是非空的,那么statusp就会指向status,status中记录关于导致返回的子进程的状态信息,所以statusp主要就是记录子进程终止的原因。而wait.h头文件定义了解释status参数的几个宏参数
- 关于参数
int options
| 取值 | 解释 |
|---|---|
| WNOHANG | 如果等待集合中的任何子进程都还没有终止,那么就立即返回(返回值为0)。默认的行为是挂起调用进程,直到有子进程终止。在等待子进程终止的同时,如果还想做些有用的工作,这个选项会有用。 |
| WUNTRACED | 挂起调用进程的执行,直到等待集合中的一个进程变成已终止或者被停止。返回的PID为导致返回的已终止或被停止子进程的PID。默认的行为是只返回已终止的子进程。当你想要检查已终止和被停止的子进程时,这个选项会有用。 |
| WCONTINUED | 挂起调用进程的执行,直到等待集合中一个正在运行的进程终止或等待集合中一个被停止的进程收到SIGCONT信号重新开始执行。 |
options取值为WNOHANG就是父进程在调用waitpid函数后考察是否已经有子进程终止了,无论有没有子进程终止了,都是继续执行父进程不会停,而options取值为WUNTRACED就是让父进程在调用waitpid函数过后一直等着,等到有子进程终止为止
- 关于返回值
waitpid返回导致waitpid返回的已终止子进程的PID。此时,已终止的子进程已经被回收,内核会从系统中删除掉它的所有痕迹。如果调用进程没有子进程,那么waitpid返回-1,并且设置errno为ECHILD,如果waitpid函数被一个信号中断,那么它返回-1,并设置errn0为EINTR
- 关于
wait函数
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *statusp)
wait(&status)函数等价于waitpid(-1,&status,0),就是说调用wait函数会让父进程挂起等着任意一个子进程终止
练习题8.3
列出下面程序所有可能的输出序列:
int main()
{
if (Fork()==0){
printf("a");fflush(stdout);
}
else{
printf("b");fflush(stdout);
waitpid(一1,NULL, 0);
}
printf("c");fflush(stdout);
exit(0);
}
父进程调用fork函数后,子进程对if会执行打印a,然后打印c,而父进程对if会执行b,然后父进程会挂起等着子进程终止,才会执行打印c,所以最后一个打印出来的一定是父进程打印的c,但是之前的就无法确定了,有可能子进程直接执行完成就是acbc,有可能父进程先执行到挂起等着子进程执行完成就是bacc,还有可能子进程先执行打印,a父进程执行打印b,然后就随意了无论是父进程先执行waitpid还是子进程先执行打印c,都是abcc
我们知道序列acbc, abcc和bacc是可能的,因为它们对应有进程图的拓扑排序。而像bcac和cbca这样的序列不对应有任何拓扑排序,因此它们是不可行的。

waitpid函数实例
#include "csapp.h"
#define N 2
int main()
{
int status, i;
pid_t pid;
for (i = 0; i < N; i++)//父进程连续建立N个子进程
if ((pid = Fork()) == 0)//如果执行的进程是子进程的话
exit(100+i);子进程以100+i正常状态终止
while ((pid = waitpid(-1, &status, 0)) > 0)//如果执行的进程是父进程并且有子进程处于僵死模式的话
{
if (WIFEXITED(status))//如果子进程是正常终止的话
printf("child %d terminated normally with exit status=%d
",pid, WEXITSTATUS(status));//打印进程终止状态
else//如果子进程是异常终止的话
printf("child %d terminated abnormally
", pid);//打印进程是异常终止的
}
if (errno != ECHILD)//如果还有子进程是僵死模式但是父进程已经跳出了while循环的话
unix_error("waitpid error");//打印waitpid函数错误
exit(0);
}
进程休眠
sleep函数将一个进程挂起一段指定的时间
#include <unistd.h>
unsigned int sleep (unsigned int sets)
如果请求的时间量已经到了,sleep返回,否则返回还剩下的要休眠的秒数,进程的休眠时间还没到,sleep函数就返回是有可能的,如果因为sleep函数被一个信号中断,就会过早地返回。
我们会发现另一个很有用的函数是pause函数,该函数让调用函数休眠直到该进程收到一个信号。
#include <unistd.h>
int pause(void)
pause() causes the calling process (or thread) to sleep until a signal is delivered that either terminates the process or causes the invocation of a signal-catching function.暂停()会导致调用进程(或线程)进入休眠状态,直到传递信号,终止进程或引起信号捕获函数的调用。
练习题8. 5
编写一个sleep的包装函数,叫做snooze,带有下面的接口:
unsigned int snooze(unsigned int sets);
snooze函数和sleep函数的行为完全一样,除了它会打印出一条消息来描述进程实际休眠了多长时间:Slept for 4 of 5 sets
/* $begin snoozesignal */
#include "csapp.h"
/* SIGINT handler */
void handler(int sig)
{
return; /* Catch the signal and return */
}
/* $begin snooze */
unsigned int snooze(unsigned int secs) {
unsigned int rc = sleep(secs);
printf("Slept for %d of %d secs.
", secs-rc, secs);
return rc;
}
/* $end snooze */
int main(int argc, char **argv) {
if (argc != 2) {
fprintf(stderr, "usage: %s <secs>
", argv[0]);
exit(0);
}
if (signal(SIGINT, handler) == SIG_ERR) /* Install SIGINT handler */
unix_error("signal error
");
(void)snooze(atoi(argv[1]));
exit(0);
}
/* $end snoozesignal */
加载并运行程序
execve函数在当前进程的上下文中加载并运行一个新程序
#include <unistd.h>
int execve(const char *filename,const char *argv[],const char *envp[]);
execve() executes the program pointed to by filename.filename must be either a binary executable, or a script starting with a line of the form:#! interpreter [optional-arg]
execve()执行文件名指向的程序。filename必须是二进制可执行文件,或者是以下列格式的行开始的脚本:#! interpreter [optional-arg]
argv is an array of argument strings passed to the new program. By convention, the first of these strings should contain the filename associated with the file being executed. envp is an array of strings,conventionally of the form key=value, which are passed as environment to the new program. Both argv and envp must be terminated by a null pointer. The argument vector and environment can be accessed by the called program's main function, when it is defined as:
argv是传递给新程序的参数字符串数组。 按照惯例,这些字符串中的第一个应该包含与正在执行的文件相关的文件名。 envp是一个字符串数组,通常是key = value形式,作为环境传递给新程序。 argv和envp都必须由空指针终止。 参数向量和环境可以被调用程序的主函数访问,当它被定义为:
int main(int argc, char *argv[], char *envp[])
execve() does not return on success, and the text, data, bss, and stack of the calling process are overwritten by that of the program loaded.
execve()不会成功返回,调用进程的文本,数据,bss和堆栈将被加载的程序覆盖。
If the executable is an a.out dynamically linked binary executable containing shared-library stubs, the Linux dynamic linker ld.so(8) is called at the start of execution to bring needed shared objects into memory and link the executable with them.
如果可执行文件是包含共享库存根的a.out动态链接二进制可执行文件,则在执行开始时调用Linux动态链接程序ld.so(8),以将所需的共享对象带入内存,并将可执行文件与其链接起来。
If the executable is a dynamically linked ELF executable, the inter‐ preter named in the PT_INTERP segment is used to load the needed shared objects. This interpreter is typically /lib/ld-linux.so.2 for binaries linked with glibc.
如果可执行文件是动态链接的ELF可执行文件,则使用PT_INTERP段中指定的解释器来加载所需的共享对象。对于用glibc链接的二进制文件,这个解释器通常是/lib/ld-linux.so.2。
练习题8.6
编写一个叫做myech。的程序,打印出它的命令行参数和环境变量。
例如:
linux> ./myecho argl arg2
Command-ine argumen七s:
argv[of:myecho
argv[1]:argl
argv[2]:arg2
Environment variables:
envp[0]:PWD=/usr0/droh/ics/code/ecf
envp[1]:TERM=emacs
envp [25]:USER=droh
envp [26]:SHELL=/usr/local/bin八csh
envp [27]:HOME=/usr0/droh
/* $begin myecho */
#include "csapp.h"
int main(int argc, char *argv[], char *envp[])
{
int i;
printf("Command-line arguments:
");
for (i=0; argv[i] != NULL; i++)//如果argv[i]的指针不为空的话
printf(" argv[%2d]: %s
", i, argv[i]);//打印参数
printf("
");
printf("Environment variables:
");
for (i=0; envp[i] != NULL; i++)//如果envp[i]的指针不为空的话
printf(" envp[%2d]: %s
", i, envp[i]);//打印参数
exit(0);
}
/* $end myecho */
利用fork和execve实现shell
shell执行一系列的读/求值(read/evaluate)步骤,然后终止。读步骤读取来自用户的一个命令行。求值步骤解析命令行,并代表用户运行程序。
以下是展示了对命令行求值的代码。它的首要任务是调用parseline函数,这个函数解析了以空格分隔的命令行参数,并构造最终会传递给execve的argv向量。第一个参数被假设为要么是一个内置的shell命令名,马上就会解释这个命令,要么是一个可执行目标文件,会在一个新的子进程的上下文中加载并运行这个文件。
如果最后一个参数是一个“&”字符,那么parseline返回1,表示应该在后台执行该程序(shell不会等待它完成)。否则,它返回0,表示应该在前台执行这个程序(shell会等待它完成)。
在解析了命令行之后,eval函数调用builtin command函数,该函数检查第一个命令行参数是否是一个内置的shell命令。如果是,它就立即解释这个命令,并返回值1。否则返回0。简单的shell只有一个内置命令—quit命令,该命令会终止shell。实际使用的shell有大量的命令,比如pwd. jobs和fgo
如果builtin command返回0,那么shell创建一个子进程,并在子进程中执行所请求的程序。如果用户要求在后台运行该程序,那么shell返回到循环的顶部,等待下一个命令
行。否则,shell使用waitpid函数等待作业终止。当作业终止时,shell就开始下一轮迭代。
/* $begin shellmain */
#include "csapp.h"
#define MAXARGS 128
#define MAXLINE 128
/* Function prototypes */
void eval(char *cmdline);
int parseline(char *buf, char **argv);
int builtin_command(char **argv);
int main()
{
char cmdline[MAXLINE]; /* Command line */
while (1) {
/* Read */
printf("> ");
Fgets(cmdline, MAXLINE, stdin);
//cmdline:字符型指针,cmdline[MAXLINE]字符数组用来存储命令。
//MAXLINE:整型数据,记录命令的长度。
//stdin:文件结构体指针,文件结构体指针,将要读取的文件流。这里是标准输入设备,在unix或者linux系统中,硬件设备也被认为是文件
if (feof(stdin))
//判断是否有输入
exit(0);
//没有输入就退出程序
/* Evaluate */
eval(cmdline);
//将cmdline中的命令传给eval函数
}
}
/* $end shellmain */
/* $begin eval */
/* eval - Evaluate a command line */
void eval(char *cmdline)
{
char *argv[MAXARGS]; /* Argument list execve() */
char buf[MAXLINE]; /* Holds modified command line */
int bg; /* Should the job run in bg or fg? */
pid_t pid; /* Process id */
strcpy(buf, cmdline);
//把cmdline中的命令放到buf字符串中
bg = parseline(buf, argv);
//调用parseline函数解析命令
if (argv[0] == NULL)
//忽略空行
return;
if (!builtin_command(argv))
//如果命令不为空
{
if ((pid = Fork()) == 0)//新建子进程,如果是子进程话
{
if (execve(argv[0], argv, environ) < 0)//如果调用execve失败返回
{
printf("%s: Command not found.
", argv[0]);
exit(0);
}
}
//如果是父进程的话
if (!bg)//如果子进程要在shell中执行
{
int status;
if (waitpid(pid, &status, 0) < 0)
//等待子进程执行完成
unix_error("waitfg: waitpid error");
}
else//如果子进程不用在shell中执行
printf("%d %s", pid, cmdline);
}
return;//返回
}
/* If first arg is a builtin command, run it and return true */
int builtin_command(char **argv)
{
if (!strcmp(argv[0], "quit")) /* quit command */
exit(0);
if (!strcmp(argv[0], "&")) /* Ignore singleton & */
return 1;
return 0; /* Not a builtin command */
}
/* $end eval */
/* $begin parseline */
/* parseline - Parse the command line and build the argv array */
int parseline(char *buf, char **argv)
{
char *delim; /* Points to first space delimiter */
int argc; /* Number of args */
int bg; /* Background job? */
buf[strlen(buf)-1] = ' ';
//将命令的最后一个符号回车替换为空格
while (*buf && (*buf == ' '))
//忽略命令中的空格
buf++;
argc = 0;
while ((delim = strchr(buf, ' ')))
//以空格为分隔符将命令中的各个参数取出来放到字符串数组argv中
{
argv[argc++] = buf;
*delim = '�';
buf = delim + 1;
while (*buf && (*buf == ' '))
buf++;
}
argv[argc] = NULL;//最后一个字符串设为空
if (argc == 0)
//判断命令是否为空
return 1;
if ((bg = (*argv[argc-1] == '&')) != 0)
argv[--argc] = NULL;
return bg;
}
/* $end parseline */
简而言之,MyShell就是利用fork函数在父进程中建立子进程,在子进程中调用execve函数执行命令,在父进程中使用wait函数等待子进程结束完成,除此之外还要有解析命令的过程。
基于进程的并发编程
三种基本的构造并发程序的方法
并发现象
如果逻辑控制流在时间上重叠,那么它们就是并发的(concurrent)。并发出现在计算机系统的许多不同层面上:硬件异常处理程序、进程和Linux信号处理程序。
并发程序
使用应用级并发的应用程序。
三种基本的构造并发程序的方法
- 进程。用这种方法,每个逻辑控制流都是一个进程,由内核来调度和维护。因为进程有独立的虚拟地址空间,想要和其他流通信,控制流必须使用某种显式的进程间通信(interprocess communication, IPC)机制。
- I/O多路复用。在这种形式的并发编程中,应用程序在一个进程的上下文中显式地调度它们自己的逻辑流。逻辑流被模型化为状态机,数据到达文件描述符后,主程序显式地从一个状态转换到另一个状态。因为程序是一个单独的进程,所以所有的流都共享同一个地址空间。
- 线程。线程是运行在一个单一进程上下文中的逻辑流,由内核进行调度。你可以把线程看成是其他两种方式的混合体,像进程流一样由内核进行调度,而像I/O多路复用流一样共享同一个虚拟地址空间。
进程与线程的区别
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。一个程序至少有一个进程,一个进程至少有一个线程。
-
在分配空间方面,进程有独立的地址空间,在执行过程中拥有独立的内存单元,一个进程崩溃后不会对其它进程产生影响。而线程只是一个进程中的不同执行路径,有自己的堆栈和局部变量,但没有单独的地址空间。
-
在效率方面,因为线程的划分尺度小于进程,使得多线程程序的并发性高,极大地提高了程序的运行效率,但是一个线程死掉就等于整个进程死掉。多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
-
在执行方面,每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
-
在逻辑方面,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。
I/O复用原理
如果用监控来自10根不同地方的水管(I/O端口)是否有水流到达(即是否可读),那么需要10个人(即10个线程或10处代码)来做这件事;如果利用某种技术(比如摄像头)把这10根水管的状态情况统一传达到某一点,那么就只需要1个人在那个点进行监控就行了。
让应用程序可以同时对多个I/O端口进行监控以判断其上的操作是否可以进行,达到时间复用的目的。由于I/O多路复用是在单一进程的上下文中的,因此每个逻辑流程都能访问该进程的全部地址空间,所以开销比多进程低得多;缺点是编程复杂度高。
基于进程的并发编程
一个构造并发服务器的自然方法就是,在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。
假设我们有两个客户端和一个服务器,服务器正在监听一个监听描述符(比如指述符3)上的连接请求。
现在假设服务器接受了客户端1的连接请求,并返回一个已连接描述符(比如指述符4),如图12-1所示。

在接受连接请求之后,服务器派生一个子进程,这个子进程获得服务器描述符表的完整副本。子进程关闭它的副本中的监听描述符3,而父进程关闭它的已连接描述符4的副本,因为不再需要这些描述符了。这就得到了图12-2中的状态,其中子进程正忙于为客户端提供服务。
因为父、子进程中的已连接描述符都指向同一个文件表表项,所以父进程关闭它的已连接描述符的副本是至关重要的。否则,将永不会释放已连接描述符4的文件表条目,而且由此引起的内存泄漏将最终消耗光可用的内存,使系统崩溃。
现在,假设在父进程为客户端1创建了子进程之后,它接受一个新的客户端2的连接请求,并返回一个新的已连接描述符(比如描述符5),如图12-3所示。
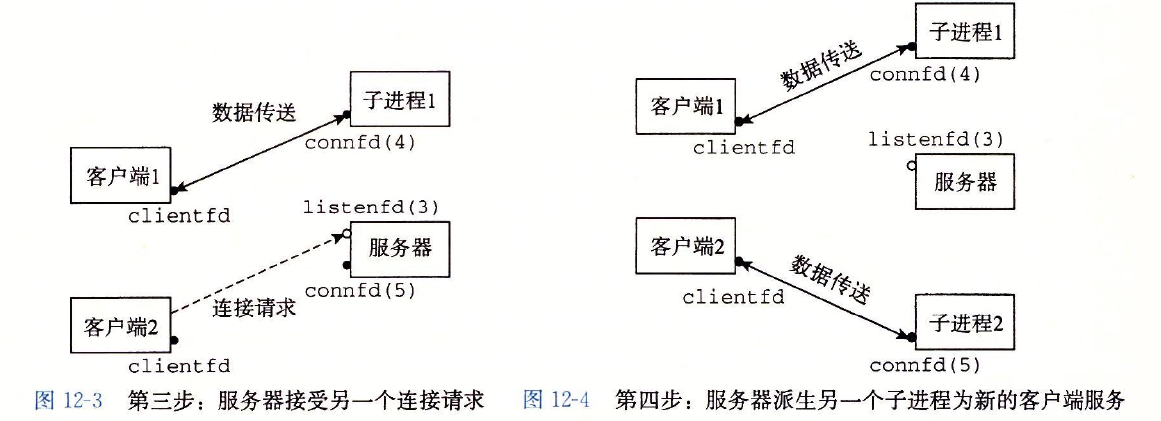
然后,父进程又派生另一个子进程,这个子进程用已连接描述符5为它的客户端提供服务,如图12-4所示。此时,父进程正在等待下一个连接请求,而两个子进程正在并发地为它们各自的客户端提供服务。
这一过程概括起来就是服务器进程收到客户端进程的连接请求的时候,服务器进程产生一个子进程为客户端进程服务,而服务器端进程继续监听其他客户端进程的请求。简而言之,服务器进程负责监听,子进程负责服务。
/*
* echoclient.c - An echo client
*/
/* $begin echoclientmain */
#include "csapp.h"
int main(int argc, char **argv)
{
int clientfd;
char *host, *port, buf[MAXLINE];
rio_t rio;
if (argc != 3) {
fprintf(stderr, "usage: %s <host> <port>
", argv[0]);
exit(0);
}
host = argv[1];
port = argv[2];
clientfd = Open_clientfd(host, port);
Rio_readinitb(&rio, clientfd);
while (Fgets(buf, MAXLINE, stdin) != NULL) {
Rio_writen(clientfd, buf, strlen(buf));
Rio_readlineb(&rio, buf, MAXLINE);
Fputs(buf, stdout);
}
Close(clientfd);
exit(0);
}
/* $end echoclientmain */
/*
* echoserverp.c - A concurrent echo server based on processes
*/
/* $begin echoserverpmain */
#include "csapp.h"
void echo(int connfd);
void sigchld_handler(int sig) //line:conc:echoserverp:handlerstart
{
while (waitpid(-1, 0, WNOHANG) > 0)
;
return;
} //line:conc:echoserverp:handlerend
int main(int argc, char **argv)
{
int listenfd, connfd;
socklen_t clientlen;
struct sockaddr_storage clientaddr;
if (argc != 2) {
fprintf(stderr, "usage: %s <port>
", argv[0]);
exit(0);
}
Signal(SIGCHLD, sigchld_handler);
listenfd = Open_listenfd(argv[1]);
while (1) {
clientlen = sizeof(struct sockaddr_storage);
connfd = Accept(listenfd, (SA *) &clientaddr, &clientlen);
if (Fork() == 0) {
Close(listenfd); /* Child closes its listening socket */
echo(connfd); /* Child services client */ //line:conc:echoserverp:echofun
Close(connfd); /* Child closes connection with client */ //line:conc:echoserverp:childclose
exit(0); /* Child exits */
}
Close(connfd); /* Parent closes connected socket (important!) */ //line:conc:echoserverp:parentclose
}
}
/* $end echoserverpmain */
进程的优劣
对于在父、子进程间共享状态信息,进程有一个非常清晰的模型:共享文件表,但是不共享用户地址空间。进程有独立的地址空间既是优点也是缺点。这样一来,一个进程不可能不小心覆盖另一个进程的虚拟内存,这就消除了许多令人迷惑的错误—这是一个明显的优点。
另一方面,独立的地址空间使得进程共享状态信息变得更加困难。为了共享信息,它们必须使用显式的IPC(进程间通信)机制。基于进程的设计的另一个缺点是,它们往往比较慢,因为进程控制和IPC的开销很高。
简而言之,基于进程的并发编程的优势在于父子进程有各自独立的内存空间以及相应的代码,命令,变量等等,但是缺点就是父子进程交互困难,系统开销比较大。
教材学习中的问题和解决过程
练习题8.4
考虑下面的程序:
#include "csapp.h"
/* $begin waitprob1 */
/* $begin wasidewaitprob1 */
int main()
{
int status;
pid_t pid;
printf("Hello
");
pid = Fork();
printf("%d
", !pid);
if (pid != 0)
{
if (waitpid(-1, &status, 0) > 0)
{
if (WIFEXITED(status) != 0)
printf("%d
", WEXITSTATUS(status));
}
}
printf("Bye
");
exit(2);
}
/* $end waitprob1 */
/* $end wasidewaitprob1 */
A. 这个程序会产生多少输出行?
B. 这些输出行的一种可能的顺序是什么?
父进程打印Hello,创建子进程。子进程中,pid=0取反得1,打印1,打印bye,终止。父进程中,pid!=0取反得0,打印0,打印子进程终止状态2,打印bye,终止,共计6行

A. 只简单地计算进程图(图8-49)中printf顶点的个数就能确定输出行数。在这里,有6个这样的顶点,因此程序会打印6行输出。
B. 任何对应有进程图的拓扑排序的输出序列都是可能的。例如:Hello,1,0,Bye,2,Bye是可能的
代码调试中的问题和解决过程
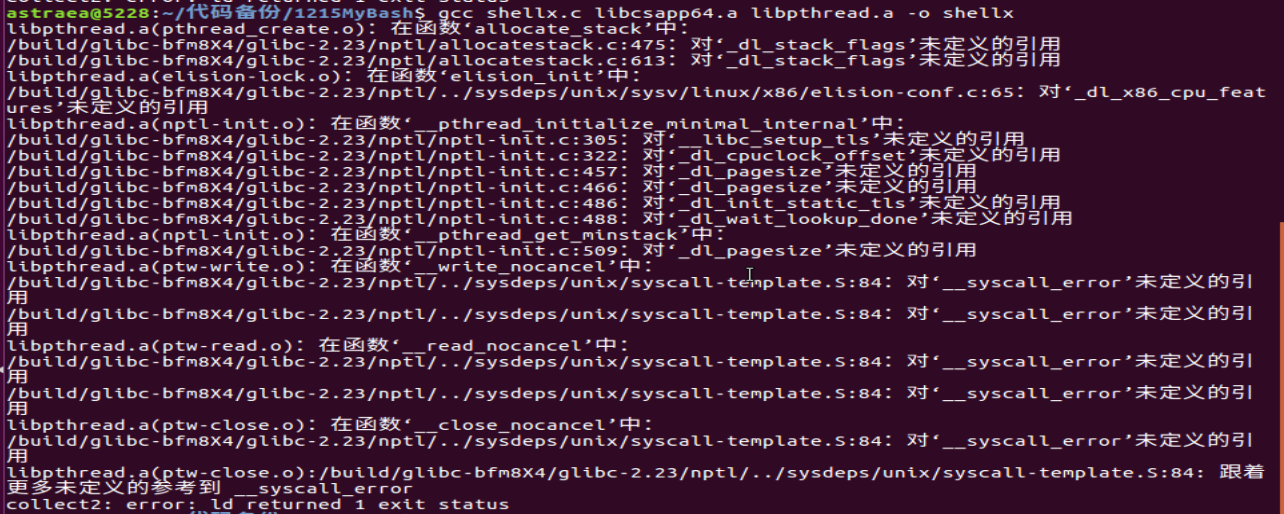
关于教材代码中的"csapp.h"头文件以及"libcsapp64.a"静态链接库的问题
我在编译教材P643的echoclient.c代码时遇到了问题。
-
第一次编译报错提示没有csapp.h头文件,我到教材官网上下载了csapp.h头文件并放到/usr/include目录中。
-
第二次编译报错说有未定义的函数引用,我打开csapp.h文件找了一下未定义的函数,只有声明没有定义。
-
我又从官网上下了libcsapp64.a库函数文件,但是不知道放在哪里,我输入编译命令gcc echoclient.c -l libcsapp64.a -o server提示在usr/bin/ld找不到libcsapp64.a,
-
然后我把csapplib64.a放到usr/bin/ld目录下,再编译的时候还是报错:/usr/bin/ld: 2: /usr/bin/ld: Syntax error: newline unexpected,
-
我把libcsapp64.a放在echoclient.c同一个文件夹里然后用gcc echoclient.c libcsapp64.a -o client还是出现相同的问题,百度上没找到解决办法
后来我在编译教材P524上的代码的时候又遇到了类似的问题。
- 编译报错说在静态库libcsapp64.a有对未定义函数的引用,我上网查了一下未定义的函数在一个名叫pthread.a的静态库里。

- 然后在系统里找到了这个静态库并拷到C文件所在目录里,但是再次编译时又报错说在pthread.a中有未定义的函数引用。

- 我感觉静态库连着静态库,静态库在调用其他静态库里的函数,那我不是要把所有静态库全部放到目录里才能编译代码了?
代码托管

上周考试错题总结
实验4,Linux中通过把设备抽象成文件来简化操作的,我们可以用open/read/write/close来像访问文件一样访问设备, 这里需要一个结构提供设备驱动程序接口,这个结构是()
A . struct file
B . struct inode
C . struct file_operations
D . struct UTMP
正确答案: C 你的答案: A
在系统内部,I/O设备的存取操作通过特定的入口点来进行,而这组特定的入口点恰恰是由设备驱动程序提供的。通常这组设备驱动程序接口是由结构file_operations结构体向系统说明的,它定义在include/linux/fs.h中
实验3中,在Ubuntu虚拟机中编译多线程程序时,gcc使用()选项
A . -g
B . -lthread
C . -pthread
D . -lpthread
正确答案: C 你的答案: D 查看知识点 | 收起解析
实际环境中只有-pthread可用
实验1:mount -t nfs -o nolock 192.168.0.56:/root/share /host,其中的IP是()的IP
A . Windows 宿主机
B . Ubuntu虚拟机
C . ARM实验箱
D . 以上都不对
正确答案: B 你的答案: A
嵌入式开发中,通过nfs系统把Ubuntu虚拟机的一个目录映射成ARM实验箱的Linux系统的一个目录进行调试是一个惯用法,程序调试没有问题了,再烧写到实验箱的Linux的系统中,这样实验箱重启了程序也可以用了。
实验1中Windows 宿主机,Ubuntu虚拟机,ARM实验箱三者IP要在同一网段,操作中是根据()的IP来确定网段的。
A . Windows 宿主机
B . Ubuntu虚拟机
C . ARM实验箱
D . 以上都可以
正确答案: C 你的答案: A
ARM实验箱的IP修改要重新烧录Linux系统,Windows宿主机,Ubuntu虚拟机的IP比较容易修改,所以我们在超级终端中通过ifconfig查看ARM实验箱的IP,把Windows 宿主机,Ubuntu虚拟机的IP改成和ARM实验箱同一个网段。
本周结对学习情况
给你的结对学习搭档讲解你的总结并获取反馈
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 200/200 | 2/2 | 20/20 | |
| 第二周 | 300/500 | 2/4 | 18/38 | |
| 第三周 | 500/1000 | 3/7 | 22/60 | |
| 第四周 | 300/1300 | 2/9 | 30/90 | |
| 第五周 | 400/900 | 2/6 | 6/30 | |
| 第五周 | 400/900 | 2/6 | 6/30 | |
| 第六周 | 200/1100 | 1/7 | 6/30 | |
| 第七周 | 500/1600 | 2/9 | 6/36 | |
| 第八周 | 300/1900 | 1/10 | 6/42 | |
| 第九周 | 1000/2900 | 3/13 | 6/48 | |
| 第十一周 | 200/3100 | 2/15 | 6/56 | |
| 第十三周 | 200/3300 | 2/17 | 12/68 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
参考:
-
计划学习时间:12小时
-
实际学习时间:12小时
-
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)