grep
-c: 只输出匹配行的计数
-i 不区分大 小写
-h 查询多文件时不显示匹配文件名前缀
-l 只列出文件名,不显示内容
-n 同时显示行号
-s 不显示不存在的或者无法读取文件的错误信息
-v 只显示不匹配的文本行
-w 匹配整个单词
-x 匹配整个文本行
-r 递归搜索文件及各层文件夹
-q 不显示结果,只以状态码的形式表示结果是否成功,0代表找到
-b 打印匹配的文本行到文件头的偏移量
-E 支持扩展正则表达式
-P 支持Perl正则表达式
-F 不支持正则表达式,只以字面的意思进行匹配
教常用的参数-i -l -r -n -c
egrep 使用扩展正则表达式作为默认的正则表达式引擎?
sed 流编辑
从文件或者标准输入中一次读取一行数据,参数,
-n: 取消默认输出,
-e: 允许执行多个脚本,
-f: 从脚本文件中读取命令,
-i: 直接修改原始文件,
-l: 指定行的长度,
-r: 在脚本中使用扩展正则表达式, /regexp/
-s: 默认情况下,将把命令行指定的多个文件名作为一个长的连续的输入流,Gnu.Sed.则,允许把他们当做单独的文件,这样的话,正则表达式不进行跨文件匹配。
sed 编辑命令基本语法
[address1 [address2] ] command [argument]
选择文本:
sed '1,3p' student.txt #输出1-3行,不使用-n;
sed -n '/^2020/ p' student.txt #输出开头为2020的行
sed -n '1 p' stu.txt ##输出第一行
sed -n '$ p' stu.txt ###输出最后一行
sed -n '1~2 p' stu.txt ####输出奇数行,1,1+2,1+2+2.....1,2 p是1-2行。
sed -n '0~2 p' stu.txt ####输出偶数行
sed -n '/abc/ ,5 p' stu.txt ####输出从第一个含有abc(匹配处)开始,到第5行结束。
替换文本:
[address1 [address2]] s/pattern/replacemen/[flag]
flag:
g :global,全局替换
N :十进制数字,替换第N个
p :替换第一个,并将缓冲区输出到标准输出
w :替换第一个,并将受影响的行输出到磁盘文件中
空 :则替换第一个
sed '1,3 s/e/E/g'stu.txt ###替换第1-3行中所有的
sed '1,/^2020/ s/e/E/g' stu.txt ###替换第一行开始,到第一个匹配项所在行为止,之间所有内容
sed 's/<[^>]*>//g' html.txt ###将文件中的html标记替换为空
sed 's/tring/long &/' demo.txt ###&或
;n=1-9;表示引用匹配模式,把string替换为 long string
删除文本:
[ad1 [ad2]] d
sed -e '1 d' stu.txt ####删除第一行
sed -e '$ d' stu.txt ####删除最后一行
sed -e '1,4 d' stu.txt ####删除1-4行
sed -e '1~2 d' stu.txt ####删除奇数行
sed -e '0~2 d' stu.txt ####删除偶数行
sed -e '1,/^2020/ d' student.txt ####删除1到匹配的行
sed -e '4,$ d' stu.txt ####删除第4到最后一行
追加文本:行后追加
[address] a string
sed '2 a 2020 tom' stu.txt ####在第二行后面追加"2020 Tom"
插入文本:行前插入
[address] i string
sed '2 i 2020 tom' stu.txt ####在第二行前面插入"2020 Tom"
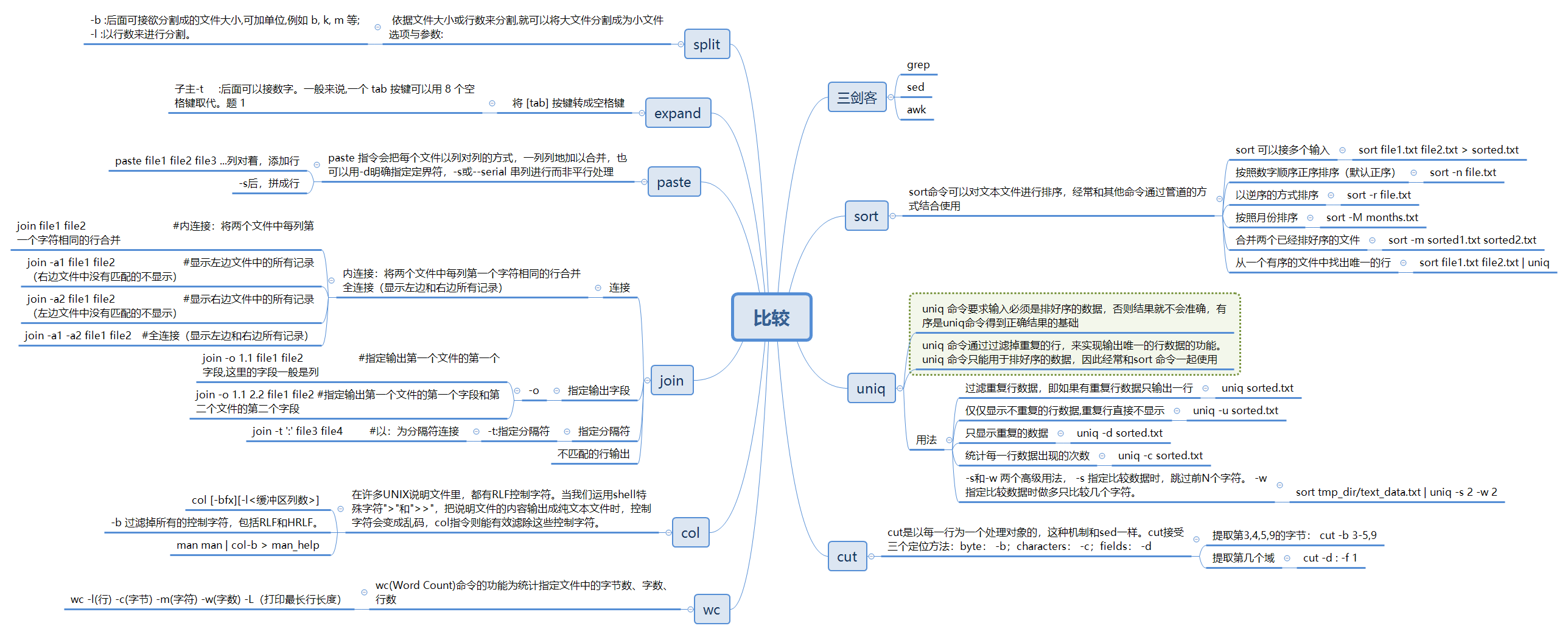
#################################################待补充##########################################
awk 处理