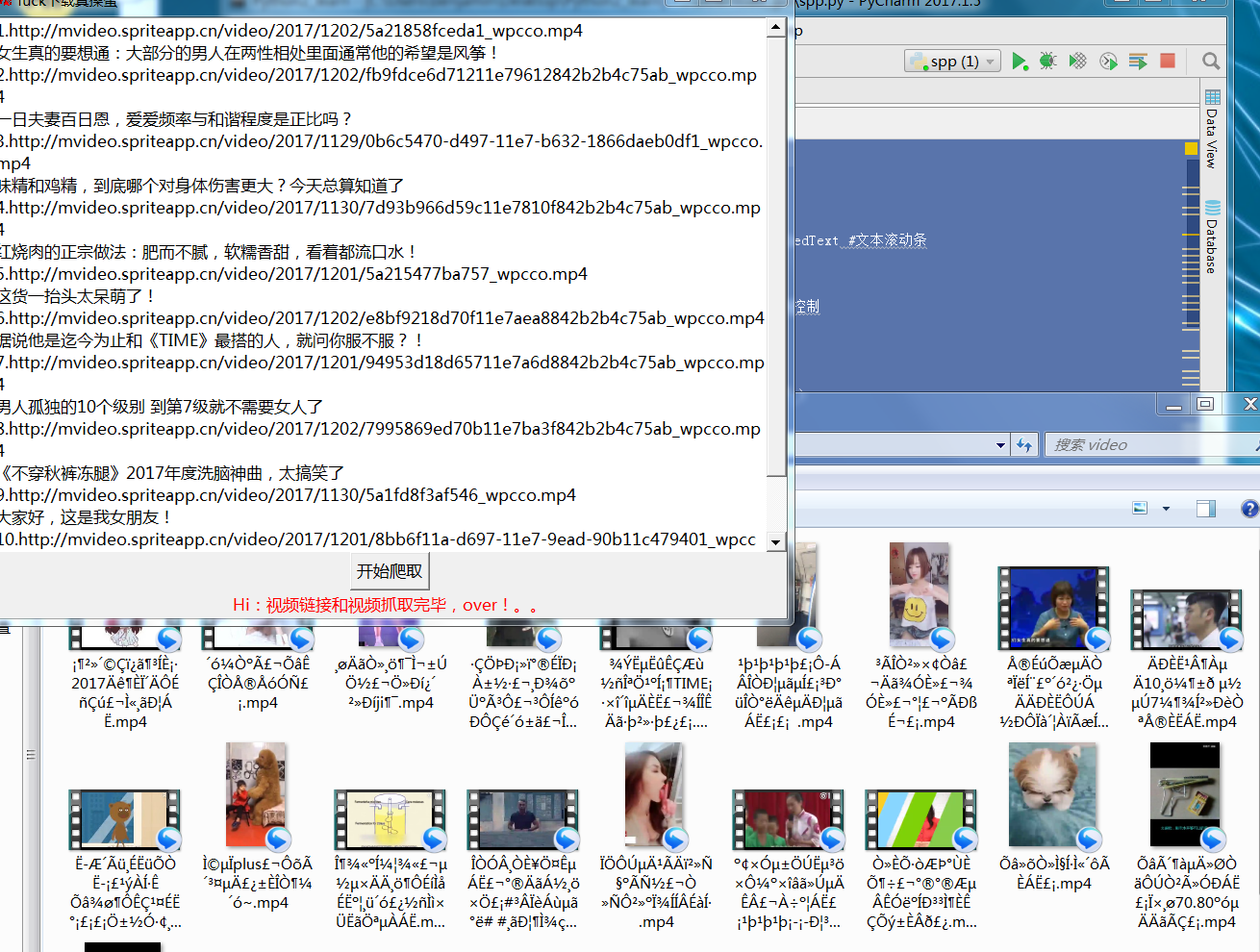
环境
python2.7 pycharm
课题:Python爬取视频(桌面版)---爬虫,桌面程序应用
优点:语法简洁,入门快,代码少,开发效率高,第三方库
1.图形用户界面---GUI
2.爬虫,爬取视屏下载
3.结合,展现在GUI
正则表达式:想要的东西 表达形式 模型
匹配findall(正则表达式,源码)
知识点:
1.如何创建一个窗口
2.如何进行填充 滚动条 点击按钮 文本框
3.解决网站禁止爬虫---加上头部信息(浏览器),伪装浏览器进行访问
4.打开网页获取源码 requests
5.获取视频 名称
6.下载并且展示
代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: benjaminYang
from Tkinter import *
from ScrolledText import ScrolledText #文本滚动条
import urllib,requests
import re
import threading #多线程处理与控制
#import time #
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
url_name=[] #url+name
a=1 #页数
def get():
global a #改变全局变量
hd={
'User - Agent': 'Mozilla / 5.0(Windows NT 6.1;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 62.0.3202.94Safari / 537.36'
}
url='http://www.budejie.com/video/'+str(a)
varl.set('已经获取第%s页的视屏'%(a))
html=requests.get(url,headers=hd).text #发送get请求,获取源码
# print html #网站全部源码
url_content=re.compile(r'(<div class="j-r-list-c">.*?</div>.*?</div>)',re.S) #编译,提高效率,匹配换行符
url_contents=re.findall(url_content,html)
# print url_contents #视屏的名称+视屏的url
for i in url_contents:
url_reg=r'data-mp4="(.*?)">'
url_items=re.findall(url_reg,i)
# print url_items
if url_items:#如果有视屏存在,我就匹配名字,如果是图片,我就跳过
name_reg=re.compile(r'<a href="/detail-.{8}?.html">(.*?)</a>',re.S)
name_items=re.findall(name_reg,i)
# print name_items #列表中的中文是可迭代对象都是Unicode格式
for i,k in zip(name_items,url_items): #zip函数 将两个可迭代对象一一对应
url_name.append([i,k])
print i,k
return url_name
id=1 #视屏个数
def write():
global id
while id<10:
url_name=get()#调用获取视屏+名字
for i in url_name:
#windows只能识别gbk 先将Unicode解码,然后再编码成gbk
urllib.urlretrieve(i[1],'video\%s.mp4'%(i[0]).decode('utf-8').encode('gbk'))#下载的方法urlretrieve
text.insert(END,str(id)+'.'+i[1]+'
'+i[0]+'
')
url_name.pop(0) #删除一个元素
id+=1
varl.set('Hi:视频链接和视频抓取完毕,over!。。')
def start():
th=threading.Thread(target=write())#实例一条线程
th.start()
root=Tk() #实例化一个变量
root.title('fuck下载真操蛋')
text= ScrolledText(root,font=('微软雅黑',10))
text.grid()#实现布局的一种方法
button=Button(root,text='开始爬取',font=('微软雅黑',10),command=start) #按钮绑定start函数
button.grid() #按钮
varl=StringVar()#通过tk方法绑定一个变量
label=Label(root,font=('微软雅黑',10),fg='red',textvariable=varl)
label.grid()
varl.set('熊猫已经准备......')
root.mainloop() #创建窗口指令
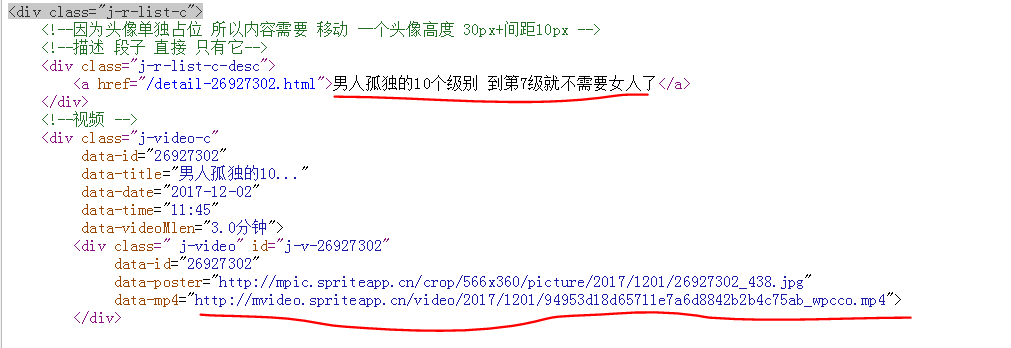
演示: