Storm上游数据源之Kakfa
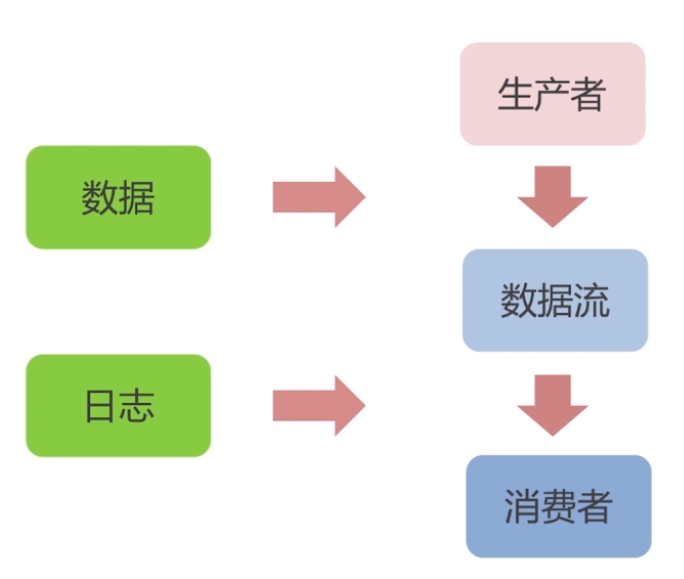
PS: 数据一直在不断的流动,日志一直不断的产生;所以有了kafka这种东西把数据有基的组织起来,就有生产者和消费者
PS:什么是kafka,为什么要学习它?
http://blog.csdn.net/zcf_0923/article/details/70859535
http://blog.csdn.net/SJF0115/article/details/78480433
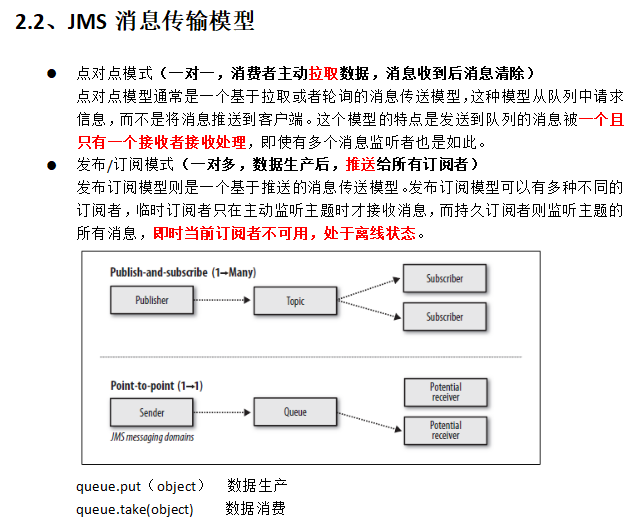
PS :kafka他不仅仅只是一个消息队列
PS:发布与订阅系统一般会有一个broker,也就是发布消息的中心点
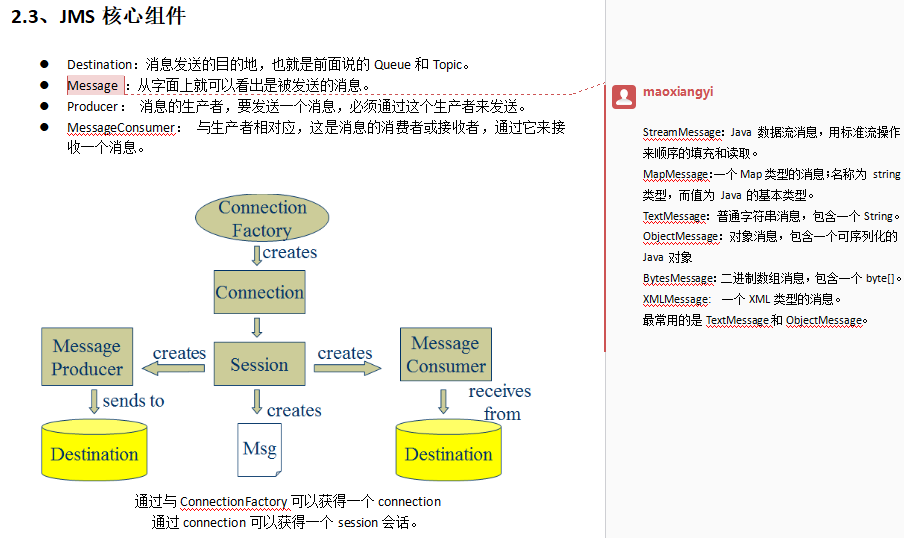
PS:kafka的数据单元被称为消息, 可以理解为数据库的一条记录
PS: def 批次





5.3 Kafka集群部署
PS:启动kafka时,要先启动zookeeper
5.3.1、下载安装包
http://kafka.apache.org/downloads.html
在linux中使用wget命令下载安装包
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz
5.3.2、解压安装包
tar -zxvf kafka_2.11-0.8.2.2.tgz -C /apps/
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
5.3.3、修改配置文件
cp /export/servers/kafka/config/server.properties
/export/servers/kafka/config/server.properties.bak
vi /export/servers/kafka/config/server.properties
输入以下内容:

5.3.4、分发安装包
scp -r /export/servers/kafka_2.11-0.8.2.2 kafka02:/export/servers
然后分别在各机器上创建软连
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
5.3.5、再次修改配置文件(重要)
依次修改各服务器上配置文件的的broker.id,分别是0,1,2不得重复。
PS: 1.按照这个进行配置
执行过程
1.启动zookeeper
2.创建log目录
3.修改配置文件,并发给每台机器
4.启动

5.4、Kafka常用操作命令
l 查看当前服务器中的所有topic
bin/kafka-topics.sh --list --zookeeper bee1:2181
l 创建topic
bin/kafka-topics.sh --create --zookeeper bee1:2181 --replication-factor 1 --partitions 3 --topic first
PS:创建并查看所创建的topic, 创建的备份数 区分数

l 删除topic
sh bin/kafka-topics.sh --delete --zookeeper zk01:2181 --topic test
需要server.properties中设置delete.topic.enable=true否则只是标记删除或者直接重启。
l 通过shell命令发送消息
kafka-console-producer.sh --broker-list kafka01:9092 --topic itheima
l 通过shell消费消息
sh bin/kafka-console-consumer.sh --zookeeper zk01:2181 --from-beginning --topic test1
l 查看消费位置
sh kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper zk01:2181 --group testGroup
l 查看某个Topic的详情
sh kafka-topics.sh --topic test --describe --zookeeper zk01:2181









---------------------------------------------------------------------------------------------------------------------------------





4、Consumer的负载均衡
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力,步骤如下:
1、 假如topic1,具有如下partitions: P0,P1,P2,P3
2、 加入group中,有如下consumer: C1,C2
3、 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4、 根据consumer.id排序: C0,C1
5、 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6、 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
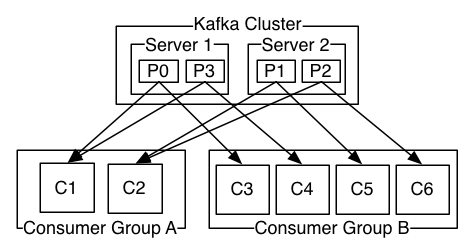
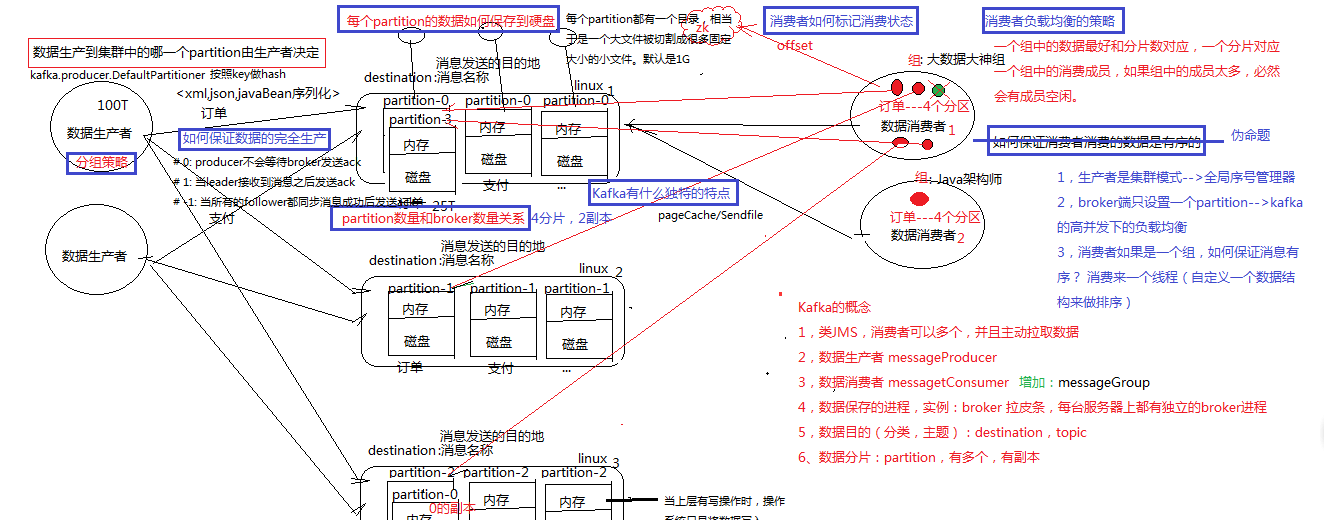
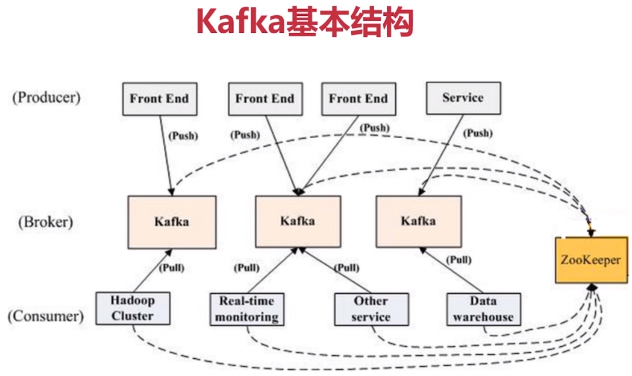
1、kafka是什么 类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据。 kafka是一个生产-消费模型。 Producer:生产者,只负责数据生产,生产者的代码可以集成到任务系统中。 数据的分发策略由producer决定,默认是defaultPartition Utils.abs(key.hashCode) % numPartitions Broker:当前服务器上的Kafka进程,俗称拉皮条。只管数据存储,不管是谁生产,不管是谁消费。 在集群中每个broker都有一个唯一brokerid,不得重复。 Topic:目标发送的目的地,这是一个逻辑上的概念,落到磁盘上是一个partition的目录。partition的目录中有多个segment组合(index,log) 一个Topic对应多个partition[0,1,2,3],一个partition对应多个segment组合。一个segment有默认的大小是1G。 每个partition可以设置多个副本(replication-factor 1),会从所有的副本中选取一个leader出来。所有读写操作都是通过leader来进行的。 特别强调,和mysql中主从有区别,mysql做主从是为了读写分离,在kafka中读写操作都是leader。 ConsumerGroup:数据消费者组,ConsumerGroup可以有多个,每个ConsumerGroup消费的数据都是一样的。 可以把多个consumer线程划分为一个组,组里面所有成员共同消费一个topic的数据,组员之间不能重复消费。 2、kafka生产数据时的分组策略 默认是defaultPartition Utils.abs(key.hashCode) % numPartitions 上文中的key是producer在发送数据时传入的,produer.send(KeyedMessage(topic,myPartitionKey,messageContent)) 3、kafka如何保证数据的完全生产 ack机制:broker表示发来的数据已确认接收无误,表示数据已经保存到磁盘。 0:不等待broker返回确认消息 1:等待topic中某个partition leader保存成功的状态反馈 -1:等待topic中某个partition 所有副本都保存成功的状态反馈 4、broker如何保存数据 在理论环境下,broker按照顺序读写的机制,可以每秒保存600M的数据。主要通过pagecache机制,尽可能的利用当前物理机器上的空闲内存来做缓存。 当前topic所属的broker,必定有一个该topic的partition,partition是一个磁盘目录。partition的目录中有多个segment组合(index,log) 5、partition如何分布在不同的broker上 int i = 0 list{kafka01,kafka02,kafka03} for(int i=0;i<5;i++){ brIndex = i%broker; hostName = list.get(brIndex) } 6、consumerGroup的组员和partition之间如何做负载均衡 最好是一一对应,一个partition对应一个consumer。 如果consumer的数量过多,必然有空闲的consumer。 算法: 假如topic1,具有如下partitions: P0,P1,P2,P3 加入group中,有如下consumer: C1,C2 首先根据partition索引号对partitions排序: P0,P1,P2,P3 根据consumer.id排序: C0,C1 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)] 7、如何保证kafka消费者消费数据是全局有序的 伪命题 如果要全局有序的,必须保证生产有序,存储有序,消费有序。 由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。 只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。
package cn.itcast.storm.kafka.simple; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; import java.util.Properties; import java.util.UUID; /** * 这是一个简单的Kafka producer代码 * 包含两个功能: * 1、数据发送 * 2、数据按照自定义的partition策略进行发送 * * * KafkaSpout的类 */ public class KafkaProducerSimple { public static void main(String[] args) { /** * 1、指定当前kafka producer生产的数据的目的地 * 创建topic可以输入以下命令,在kafka集群的任一节点进行创建。 * bin/kafka-topics.sh --create --zookeeper zk01:2181 --replication-factor 1 --partitions 1 --topic test */ String TOPIC = "orderMq"; /** * 2、读取配置文件 */ Properties props = new Properties(); /* * key.serializer.class默认为serializer.class */ props.put("serializer.class", "kafka.serializer.StringEncoder"); /* * kafka broker对应的主机,格式为host1:port1,host2:port2 */ props.put("metadata.broker.list", "bee1:9092,bee2:9092,bee3:9092"); /* * request.required.acks,设置发送数据是否需要服务端的反馈,有三个值0,1,-1 * 0,意味着producer永远不会等待一个来自broker的ack,这就是0.7版本的行为。 * 这个选项提供了最低的延迟,但是持久化的保证是最弱的,当server挂掉的时候会丢失一些数据。 * 1,意味着在leader replica已经接收到数据后,producer会得到一个ack。 * 这个选项提供了更好的持久性,因为在server确认请求成功处理后,client才会返回。 * 如果刚写到leader上,还没来得及复制leader就挂了,那么消息才可能会丢失。 * -1,意味着在所有的ISR都接收到数据后,producer才得到一个ack。 * 这个选项提供了最好的持久性,只要还有一个replica存活,那么数据就不会丢失 */ props.put("request.required.acks", "1"); /* * 可选配置,如果不配置,则使用默认的partitioner partitioner.class * 默认值:kafka.producer.DefaultPartitioner * 用来把消息分到各个partition中,默认行为是对key进行hash。 */ props.put("partitioner.class", "cn.itcast.storm.kafka.MyLogPartitioner"); // props.put("partitioner.class", "kafka.producer.DefaultPartitioner"); /** * 3、通过配置文件,创建生产者 */ Producer<String, String> producer = new Producer<String, String>(new ProducerConfig(props)); /** * 4、通过for循环生产数据 */ for (int messageNo = 1; messageNo < 100000; messageNo++) { // String messageStr = new String(messageNo + "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey," + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发" + // "用来配合自定义的MyLogPartitioner进行数据分发"); /** * 5、调用producer的send方法发送数据 * 注意:这里需要指定 partitionKey,用来配合自定义的MyLogPartitioner进行数据分发 */ producer.send(new KeyedMessage<String, String>(TOPIC, messageNo + "", "appid" + UUID.randomUUID() + "itcast")); } } }
package cn.itcast.storm.kafka.simple; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; import kafka.message.MessageAndMetadata; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class KafkaConsumerSimple implements Runnable { public String title; public KafkaStream<byte[], byte[]> stream; public KafkaConsumerSimple(String title, KafkaStream<byte[], byte[]> stream) { this.title = title; this.stream = stream; } @Override public void run() { System.out.println("开始运行 " + title); ConsumerIterator<byte[], byte[]> it = stream.iterator(); /** * 不停地从stream读取新到来的消息,在等待新的消息时,hasNext()会阻塞 * 如果调用 `ConsumerConnector#shutdown`,那么`hasNext`会返回false * */ while (it.hasNext()) { MessageAndMetadata<byte[], byte[]> data = it.next(); String topic = data.topic(); int partition = data.partition(); long offset = data.offset(); String msg = new String(data.message()); System.out.println(String.format( "Consumer: [%s], Topic: [%s], PartitionId: [%d], Offset: [%d], msg: [%s]", title, topic, partition, offset, msg)); } System.out.println(String.format("Consumer: [%s] exiting ...", title)); } public static void main(String[] args) throws Exception{ Properties props = new Properties(); props.put("group.id", "dashujujiagoushi"); props.put("zookeeper.connect", "bee1:2181,bee2:2181,bee3:2181"); props.put("auto.offset.reset", "largest"); props.put("auto.commit.interval.ms", "1000"); props.put("partition.assignment.strategy", "roundrobin"); ConsumerConfig config = new ConsumerConfig(props); String topic1 = "orderMq"; String topic2 = "paymentMq"; //只要ConsumerConnector还在的话,consumer会一直等待新消息,不会自己退出 ConsumerConnector consumerConn = Consumer.createJavaConsumerConnector(config); //定义一个map Map<String, Integer> topicCountMap = new HashMap<>(); topicCountMap.put(topic1, 3); //Map<String, List<KafkaStream<byte[], byte[]>> 中String是topic, List<KafkaStream<byte[], byte[]>是对应的流 Map<String, List<KafkaStream<byte[], byte[]>>> topicStreamsMap = consumerConn.createMessageStreams(topicCountMap); //取出 `kafkaTest` 对应的 streams List<KafkaStream<byte[], byte[]>> streams = topicStreamsMap.get(topic1); //创建一个容量为4的线程池 ExecutorService executor = Executors.newFixedThreadPool(3); //创建20个consumer threads for (int i = 0; i < streams.size(); i++) executor.execute(new KafkaConsumerSimple("消费者" + (i + 1), streams.get(i))); } }
-------------------------------------------2018-09-05
需求: 1、采集订单系统应用打印的日志文件 日志文件使用log4j生成,滚动生成。 xxxx.log xxxx.log xxxx.log xxxx.log.1 xxxx.log.1 xxxx.log.2 2、将采集的日志文件保存到kafka中 (source) 输入:tail -F xxxx.log (channel)存储:内存 (sink) 输出:kafka config al.source = s1 a1.channel = c1 al.sink = k1 source ==> exec tail -F xxxx.log channel ==> RAM sink ====> xxx.xxxx.xxxx.KafkaSink //该类必须存放lib目录 sink.topic = orderMq sink.itcast = itcast ------------------------------ map = getConfig() value = map.get("itcast") 3、通过Storm程序消费Kafka中数据 KafkaSpout() Bolt1() Bolt2() ------------------------------------------------------------------------- 业务: 订单系统---->MQ---->Kakfa--->Storm 数据:订单编号、订单时间、支付编号、支付时间、商品编号、商家名称、商品价格、优惠价格、支付金额 统计双十一当前的订单金额,订单数量,订单人数 订单金额(整个网站,各个业务线,各个品类,各个店铺,各个品牌,每个商品) totalAmount b1Amount c1Amount s1Amount p1Amount …… b2Amount+ c1Amount s1Amount p1Amount b3Amount c1Amount s1Amount+ p1Amount b4Amount c1Amount s1Amount p1Amount c1Amount s1Amount p1Amount c1Amount s1Amount p1Amount c1Amount+ s1Amount p1Amount c1Amount s1Amount p1Amount s1Amount p1Amount s1Amount p1Amount s1Amount p1Amount s1Amount p1Amount s1Amount p1Amount s1Amount p1Amount+ …… sql-->update 整个网站,各个业务线,各个品类,各个店铺,各个品牌,每个商品 Redis---> 整个网站:totalAmount 各个业务线:b1Amount,b1Amount,b1Amount,b1Amount,b1Amount 各个品类:c1Amount,c1Amount,c1Amount,c1Amount,c1Amount 各个店铺:s1Amount,s1Amount,s1Amount,s1Amount,s1Amount,s1Amount,s1Amount 各个品牌: p1Amount,p1Amount,p1Amount,p1Amount,p1Amount,p1Amount,p1Amount 每个商品:pidAmount,pidAmount,pidAmount,pidAmount,pidAmount,pidAmount totalAmount = get(totalAmount) totalAmount = set(totalAmount+orderAmount) 订单数量(整个网站,各个业务线,各个品类,各c1Amount个店铺,各个品牌,每个商品) 订单人数(整个网站,各个业务线,各个品类,各c1Amount个店铺,各个品牌,每个商品) 处理流程: 1、Spout获取外部数据源,数据源是订单的mq,mq有固定的格式,比如json串。 2、对订单mq进行解析,得到一个对象->JavaBean 订单编号、订单时间、支付编号、支付时间、商品编号、商家名称、商品价格、优惠价格、支付金额 3、对指标进行计数 //业务中一个订单包含多个商品,需要对每个商品进行指标计算 //创建订单和取消订单两种类型,在计算总数据的是考虑将取消订单的金额减掉 //订单中有拆单的逻辑,该如何计算 4、保存指标数据到Redis Storm程序 KafkaSpout FilterBolt IndexCountBolt
PS: 首先是通过flume读取日志文件 -》然后kafka执行相应,目前我的理解消队列-》到Storm处理数据流计算
package kafkaAndStorm; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.topology.TopologyBuilder; import storm.kafka.KafkaSpout; import storm.kafka.SpoutConfig; import storm.kafka.ZkHosts; public class KafkaAndStormTopologyMain { public static void main(String[] args) throws Exception{ TopologyBuilder topologyBuilder = new TopologyBuilder(); topologyBuilder.setSpout("kafkaSpout", new KafkaSpout(new SpoutConfig( new ZkHosts("zk01:2181,zk02:2181,zk03:2181"), "orderMq", "/myKafka", "kafkaSpout")),1); topologyBuilder.setBolt("mybolt1",new ParserOrderMqBolt(),1).shuffleGrouping("kafkaSpout"); Config config = new Config(); config.setNumWorkers(1); //3、提交任务 -----两种模式 本地模式和集群模式 if (args.length>0) { StormSubmitter.submitTopology(args[0], config, topologyBuilder.createTopology()); }else { LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("storm2kafka", config, topologyBuilder.createTopology()); } } }
package kafkaAndStorm; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; import com.google.gson.Gson; import order.OrderInfo; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; import java.util.HashMap; import java.util.Map; /** * Created by maoxiangyi on 2016/5/4. */ public class ParserOrderMqBolt extends BaseRichBolt { private JedisPool pool; @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { //change "maxActive" -> "maxTotal" and "maxWait" -> "maxWaitMillis" in all examples JedisPoolConfig config = new JedisPoolConfig(); //控制一个pool最多有多少个状态为idle(空闲的)的jedis实例。 config.setMaxIdle(5); //控制一个pool可分配多少个jedis实例,通过pool.getResource()来获取; //如果赋值为-1,则表示不限制;如果pool已经分配了maxActive个jedis实例,则此时pool的状态为exhausted(耗尽)。 //在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的; config.setMaxTotal(1000 * 100); //表示当borrow(引入)一个jedis实例时,最大的等待时间,如果超过等待时间,则直接抛出JedisConnectionException; config.setMaxWaitMillis(30); config.setTestOnBorrow(true); config.setTestOnReturn(true); /** *如果你遇到 java.net.SocketTimeoutException: Read timed out exception的异常信息 *请尝试在构造JedisPool的时候设置自己的超时值. JedisPool默认的超时时间是2秒(单位毫秒) */ pool = new JedisPool(config, "127.0.0.1", 6379); } @Override public void execute(Tuple input) { Jedis jedis = pool.getResource(); //获取kafkaSpout发送过来的数据,是一个json String string = new String((byte[]) input.getValue(0)); //解析json OrderInfo orderInfo = (OrderInfo) new Gson().fromJson(string, OrderInfo.class); //java和json对象之间的转换//整个网站,各个业务线,各个品类,各个店铺,各个品牌,每个商品 //获取整个网站的金额统计指标 // String totalAmount = jedis.get("totalAmount"); jedis.incrBy("totalAmount",orderInfo.getProductPrice()); //获取商品所属业务线的指标信息 String bid = getBubyProductId(orderInfo.getProductId(),"b"); // String bAmout = jedis.get(bid+"Amout"); jedis.incrBy(bid+"Amount",orderInfo.getProductPrice()); jedis.close(); } private String getBubyProductId(String productId,String type) { // key:value //index:productID:info---->Map // productId-----<各个业务线,各个品类,各个店铺,各个品牌,每个商品> Map<String,String> map = new HashMap<>(); map.put("b","3c"); map.put("c","phone"); map.put("s","121"); map.put("p","iphone"); return map.get(type); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { } }
package bee.id.haha; import com.google.gson.Gson; /** * Gson使用 * */ public class App { public static void main( String[] args ) { System.out.println( "Hello World!" ); // 使用new方法 Gson gson = new Gson(); User user = new User(); user.setId("1232"); user.setName("bee"); // toJson 将bean对象转换为json字符串 String jsonStr = gson.toJson(user, User.class); System.out.println( jsonStr ); //序列化对象 User user2 = gson.fromJson(jsonStr, User.class); System.out.println( user2.toString() ); System.out.println( user2==user); /*Hello World! {"id":"1232","name":"bee"} id: 1232 name: bee false*/ } }
PS: 可以看看课程代码