自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
1.1 基本概念
以识别芒果的好坏的案例来说明概念。
特征:描述物体的属性值,例如芒果的颜色、大小、形状、产地、品牌等;
特征向量:由物体的特征值构成的向量。
标签:标识物体的准确属性,识别的目标值。例如芒果的甜度、水分、成熟度的综合评分。
样本:独立的一份特征数据和标记,例如一个标记好特征和标签的芒果。
训练集:用于训练算法的样本集。
测试样本:用于测试算法有效性准确性的样本集。
1.2 机器学习三要素
模型,学习准则,优化算法
1.2.1 模型
机器学习的目标是找到一个模型近似真实的映射函数,将输入转化为输出,输出和目标结果近似。
(1)线性模型,wT是权重向量,b为偏置。
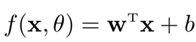
(2)非线性模型,ϕ(x)是K个非线性基函数组成的向量,ϕk(x)是一个非线性函数。f(x,θ)是非线性函数的线性组合。
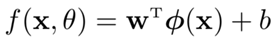
如果"ϕ(x)"为可学习的非线性基函数,"f(x,θ)"就等价于神经网络。
1.2.2 学习准则
好的模型应该在输入输出取值覆盖真实的情况,模型函数与真实的映射函数之间一致,计算出的误差在很小的范围内。可以通过期望风险这个参数来判断模型的好坏。p(x,y)表示真实的数据分布,£(f(x),y)为损失函数。
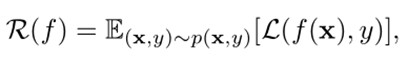
损失函数
用来量化模型预测和真实标签之间的差异。
(1)01损失函数,将预测值和实际值比较,正确为1,不正确为0直观,但是不连续。
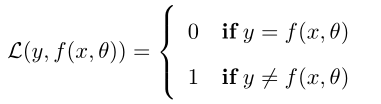
(2)平方损失函数,求出预测值和实际值差的平方和取均值。
(3)经验风险最小化,找到一组参数是的模型在训练集上的平均损失(经验风险)最小。经验风险最小化准则容易导致模型在训练集上过拟合。所以需要参数加入一个正则化项来限制模型能力,使模型不要过度的最小化经验风险,这个叫做结构风险最小化。正则化项是参数的范德蒙范数乘以系数λ。
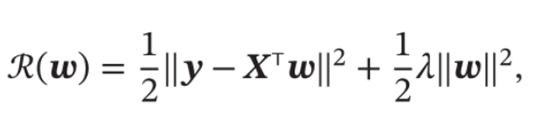
1.2.3 过拟合和欠拟合
过拟合:算法对训练集学习很好,但是由于训练集是真实数据的一个子集,存在噪声等原因,在训练集上面错误率低,但是在未知数据上错误率很高。
欠拟合:模型不能很好的拟合训练数据,在训练集上错误率比较高。
1.2.4 优化算法
确定了训练集,假设空间,和学习准则。找到一个最优的模型就是最优化求解过程。
(1) 参数模型f(x,θ)的参数θ可以通过算法优化进行学习。
(2) 超参数,用来定义模型结构或者优化策略的参数,例如梯度下降法中的步长,神经网络的层数,正则化项系数λ等。超参数一般根据经验来设定,或者搜索的方法对一组超参数进行试错调整。