Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
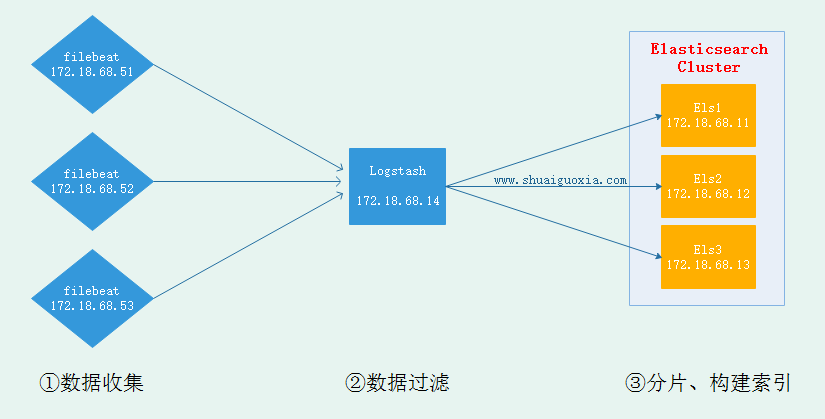
一、架构图
此次试验基于前几篇文章,需要先基于前几篇文章搭建基础环境。
二、安装Filebeat
- 下载并安装Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.1-x86_64.rpm
yum install ./filebeat-6.0.1-x86_64.rpm
- 修改Filebeat配置文件
vim /etc/filebeat/filebeat.yml # 主配置文件
- type: log # 文档类型
paths:
- /var/log/httpd/access.log* # 从哪里读入数据
# 输出在elasticsearch与logstash二选一即可
output.elasticsearch: #将数据输出到Elasticsearch。与下面的logstash二者选一
hosts: ["localhost:9200"]
output.logstash: # 将数据传送到logstash,要配置logstash使用beats接收
hosts: ["172.18.68.14:5044"]
- 启动Filebeat
systemctl start filebeat
三、配置Filebeat
- 配置Logstash接收来自Filebeat采集的数据
vim /etc/logstash/conf.d/test.conf
input {
beats {
port => 5044 # 监听5044用于接收Filebeat传来数据
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}" # 匹配HTTP的日志
}
remove_field => "message" # 不显示原信息,仅显示匹配后
}
}
output {
elasticsearch {
hosts => ["http://172.18.68.11:9200","http://172.18.68.12:9200","http://172.18.68.13:9200"] # 集群IP
index => "logstash-%{+YYYY.MM.dd}"
action => "index"
document_type => "apache_logs"
}
}
- 启动Logstash
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
四、模拟日志访问
通过curl命令来模拟客户访问,生成访问日志
curl 127.0.0.1
curl 172.18.68.51
curl 172.18.68.52
curl 172.18.68.53
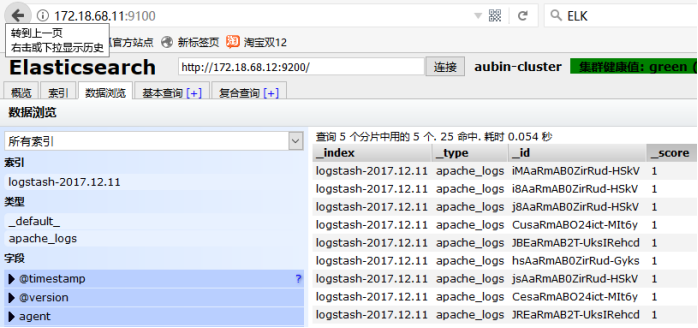
五、验证信息
清除之前实验的旧数据(删除时要在对话框中输入删除),然后可以看到filebeat采集数据经过Logtash过滤再送给Elasticsearch的数据。
扩展
随着ELK日志系统逐渐升级,现在已经能基于Filebeat采集各节点日志,Logstash过滤、修剪数据,最后到ELasticsearch中进行索引构建、分词、构建搜索引擎。现在可以基于Elasticsearch的Head查看在浏览器中查看,但是Head仅仅能简单查看并不能有效进行数据分析、有好展示。要想进行数据分析、有好展示那就需要用到Kibana,Kibana依然放在下一篇文章中讲解,这里先放上架构图。
