一、HDFS概念
1、介绍
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。HDFS开始是为开源的apache项目nutch的基础结构而创建,HDFS是hadoop项目的一部分,而hadoop又是lucene的一部分。
2、发展历史

3、设计目标

4、HDFS不适合的应用类型

5、HDFS构成

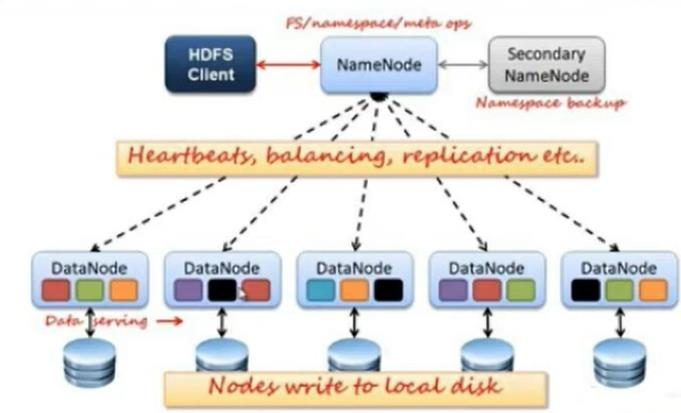
构成详解:




6、NameNode作用

7、DataNode作用


8、HDFS文件副本机制

9、机架感知
HDFS分布式文件系统的内部有一个副本存放策略:以默认的副本数=3为例:
1)第一个副本块存放本机
2)第二个副本块和第一个副本块存放一个机架不同主机(方便于第一个主机挂掉,立即接管)
3)第三个副本块存放不同机架的不同主机(防止一个机架所有主机出现问题)
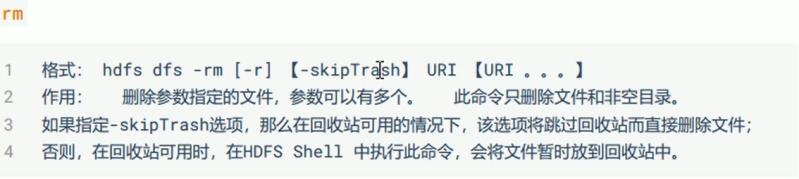
二、基本命令
web页面访问文件目录

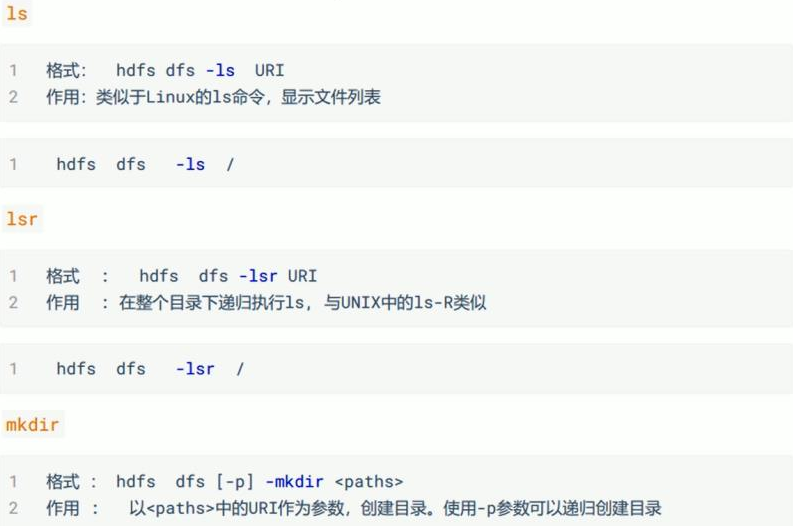
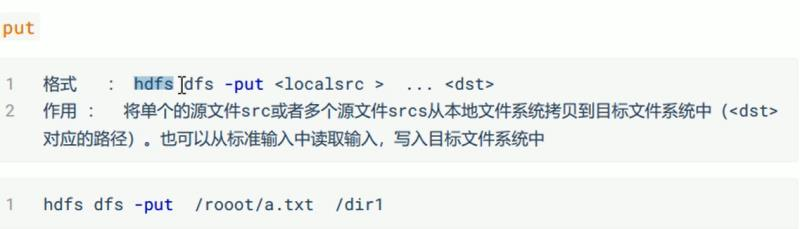
命令详解:
![]()

-cp