开两个命令行窗口:
服务端:nc –lp 8888
//客户端:nc localhost 8888
在默认情况下,Spark应用程序的日志级别是INFO的,我们可以自定义Spark应用程序的日志输出级别,可以到$SPARK_HOME/conf/log4j.properties文件里面进行修改:
DStream操作:
一、转换操作(惰性求值)
1、 无状态转换:每个批次的处理不依赖之前批次的数据
2、 有状态转换:使用之前批次的数据或者是中间结果来计算当前批次数据
1)、基于滑动窗口
2)、追踪状态变化
二、输出操作(触发之前的转换操作)
批次间隔
窗口时长(必须为批次间隔的整数倍)
滑动步长(必须为批次间隔的整数倍,默认值就等于窗口时长)
使用nc工具
nc -lp 9999创建streaming程序
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class SparkStreamWC {
public static void main(String[] args) {
//专门分出去的task去取数据来执行(“local[4]”),至少为2,多个线程
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("wordcount").set("spark.testing.memory", "2147480000");
//设置时间间隔为3s
JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(3000));
//设置服务器端口,从9999端口取数据 nc -lp localhost
JavaDStream<String> lines = jssc.socketTextStream("localhost", 9999);
jssc.sparkContext().setLogLevel("WARN");
//JavaSparkContext ctx = new JavaSparkContext(conf);
//使用DStream离散化流
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
System.out.println(s);
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
JavaPairDStream<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
counts.print(); //延迟操作
jssc.start(); //开启应用
try {
jssc.awaitTermination(); //阻塞,等待作业完成
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
reduceByKeyAndWindow
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
public class WC_Stream_Window {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("wordcount").set("spark.testing.memory", "2147480000");
//批次间隔1秒
JavaStreamingContext jssc = new JavaStreamingContext(conf, new Duration(1000));
jssc.sparkContext().setLogLevel("WARN");
jssc.checkpoint("file:///d:/checkpoint");
JavaDStream<String> lines = jssc.socketTextStream("localhost", 9999);
//JavaDStream<String> lines = jssc.textFileStream("file:///F:/workspace/PartitionDemo/src/bigdata12_1103");
//窗口时长6秒,滑动步长3秒,每次计算6个批次的窗口,每四个批次计算一次
//lines = lines.window(new Duration(6000), new Duration(3000));
//窗口时长6秒,滑动步长4秒
//lines = lines.window(new Duration(6000), new Duration(4000));
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
System.out.println("flatMap:" + s);
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> ones = words.mapToPair(s->new Tuple2<String, Integer>(s, 1));
//在整个窗口上执行规约 与上面的滑动窗口是相同的效果 (6000,4000)有重复数据 (4000,4000)就能够没有重复数据
// JavaPairDStream<String, Integer> counts = ones.reduceByKeyAndWindow(
// (x, y) ->{
// System.out.println("规约数据。。。");
// return x + y;
// },
// new Duration(6000), new Duration(4000));
//只考虑新进入窗口的数据,和离开窗口的数据,增量计算规约结果
//减去了离开窗口的数据
//避免反复计算重复的数据
JavaPairDStream<String, Integer> counts = ones.reduceByKeyAndWindow(
(x, y) -> x + y,
(x, y) -> x - y,
new Duration(6000),
new Duration(4000));
// JavaPairDStream<String, Integer> counts = ones.reduceByKey(
// (x, y)->{
// System.out.println("规约数据: x:" + x + " y:" + y);
// return x + y;
// }
// );
counts.print();
jssc.start();
try {
jssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
jssc.close();
}
}此处举例:
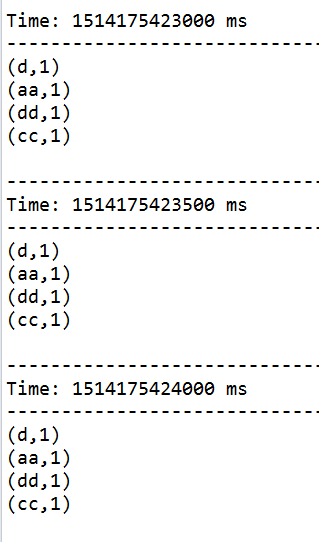
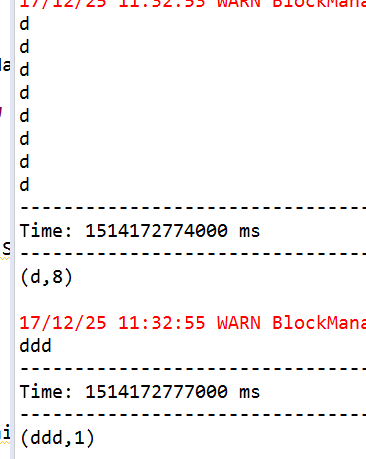
使用reduceByKeyAndWindow设置窗口时长和滑动步长。窗口时长为6个批次,滑动步长为个批次,每隔4个批次就对前6个批次的数据进行处理。(每隔4000s就对前6000s的数据进行处理)

使用UpdateStateByKey
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.Optional;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
public class UpdateStateByKeyDemo {
@SuppressWarnings("serial")
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[2]")
.setAppName("UpdateStateByKeyDemo").set("spark.testing.memory", "2147480000");
JavaStreamingContext jsc = new JavaStreamingContext(conf, new Duration(500));
jsc.sparkContext().setLogLevel("WARN");
jsc.checkpoint("file:///d:/checkpoint"); //不设目录会报错
JavaReceiverInputDStream<String> lines = jsc.socketTextStream("localhost", 9999);
//窗口时长6秒,滑动步长3秒,每次计算6个批次的窗口,每四个批次计算一次
//lines = lines.window(new Duration(6000), new Duration(3000));
//窗口时长6秒,滑动步长4秒
//lines = lines.window(new Duration(6000), new Duration(4000));
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
/*
*在这里是通过updateStateByKey来以Batch Interval为单位来对历史状态进行更新,
* 这是功能上的一个非常大的改进,否则的话需要完成同样的目的,就可能需要把数据保存在Redis、
* Tagyon或者HDFS或者HBase或者数据库中来不断的完成同样一个key的State更新,如果你对性能有极为苛刻的要求,
* 且数据量特别大的话,可以考虑把数据放在分布式的Redis或者Tachyon内存文件系统中;
*/
JavaPairDStream<String, Integer> wordsCount = pairs.updateStateByKey(
new Function2<List<Integer>, Optional<Integer>, Optional<Integer>>() {
@Override
public Optional<Integer> call(List<Integer> values, Optional<Integer> state)
throws Exception {
Integer updatedValue = 0 ;
if(state.isPresent()){ //检查optional是否包含值,存在位true
updatedValue = state.get(); //获取optional实例的值
}
for(Integer value: values){
updatedValue = value+updatedValue;
}
return Optional.of(updatedValue); //of方法通过工厂方法创建Optional类。需要注意的是,创建对象时传入的参数不能为null。如果传入参数为null,则抛出NullPointerException 。
}
}
);
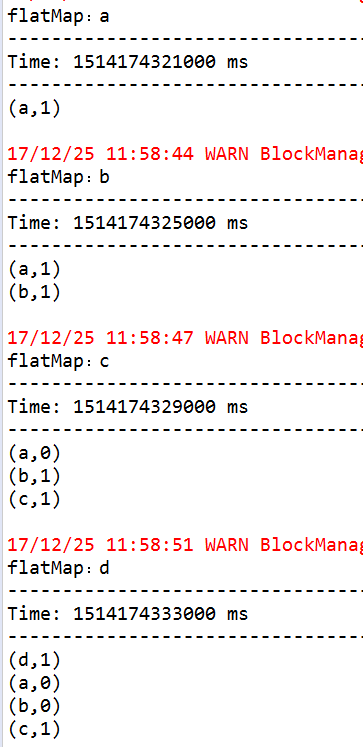
//打印键值对 计算所有批次的单词次数
wordsCount.print();
/*
* Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的,
* 当然其内部有消息循环体,用于 接受应用程序本身或者Executor中的消息;
*/
jsc.start();
try {
jsc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}
jsc.close();
}
}