先上一个源代码吧。
https://github.com/answershuto/Rental
欢迎指导交流。
效果图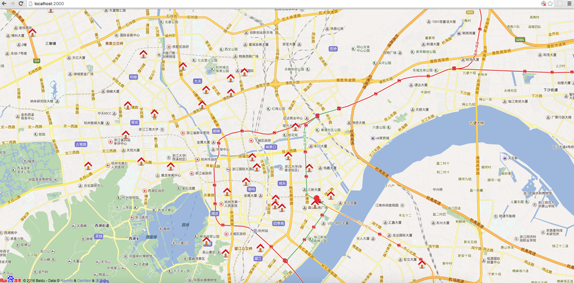
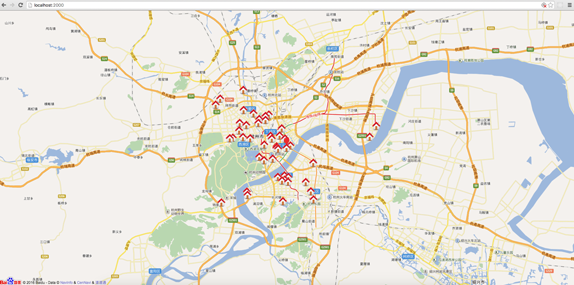
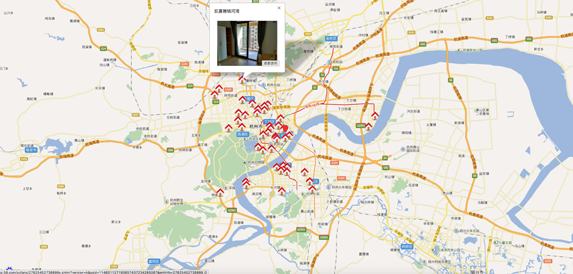
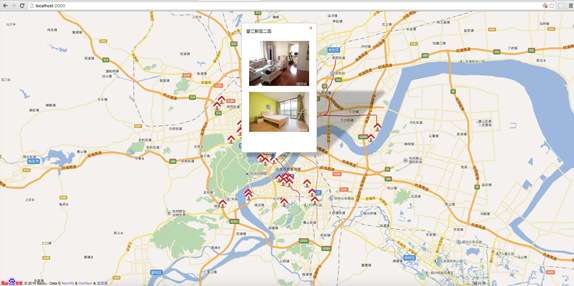
搭建Node.js环境及启动服务
安装node以及npm,用express模块启动服务,加入自己所需要的中间件即可,这个不是本文所要讨论的重点,可以参考网上的一些教程搭建环境。
获取导航页URL以及数据
打开58同城主页,我主要针对杭州的二手房进行了爬取分析,所以进入杭州租房。
http://hz.58.com/chuzu/pn1/?key=%E6%9D%AD%E5%B7%9E%E7%A7%9F%E6%88%BF%E5%AD%90&cmcskey=%E7%A7%9F%E6%88%BF%E5%AD%90&final=1&PGTID=0d3090a7-0004-f43c-ee04-95c2ea3d031f&ClickID=6
可以得到这一串URL,上下页查看后就不难发现,pn后面的数字就是页面的页码,?后面的是一些get请求带带参数。用一个函数即可通过页码得到正确的URL。
function getUrl(page = 1){ return ‘http://hz.58.com/chuzu/pn'+page+'/?key=%E6%9D%AD%E5%B7%9E%E7%A7%9F%E6%88%BF%E5%AD%90&cmcskey=%E7%A7%9F%E6%88%BF%E5%AD%90&final=1&PGTID=0d3090a7-0004-f43c-ee04-95c2ea3d031f&ClickID=6‘; }
根据上面的URL我们就可以访问到每一页的所有租房信息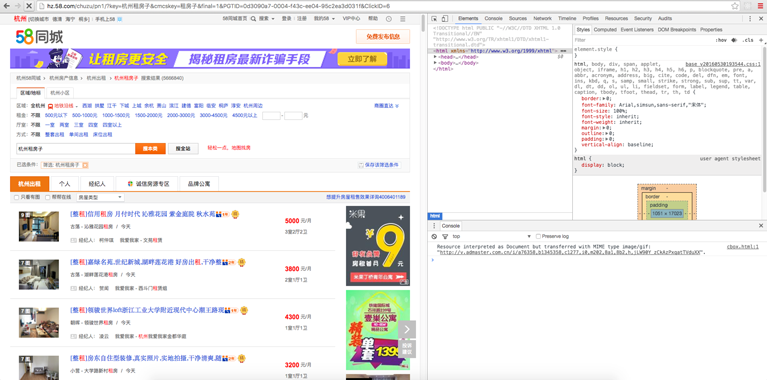
用cheerio模块解析dom
安装cheerio模块,使用cheerio模块解析dom,然后就可以类似jquery一样访问dom了。
var cheerio = require(‘cheerio’); let $ = cheerio.load(html);
获取每个租房信息的URL
打开开发者模式,osX(option + command + I),windows( F12 ),然后就可以在elements中看到文档结构了。(这里以chrome为例)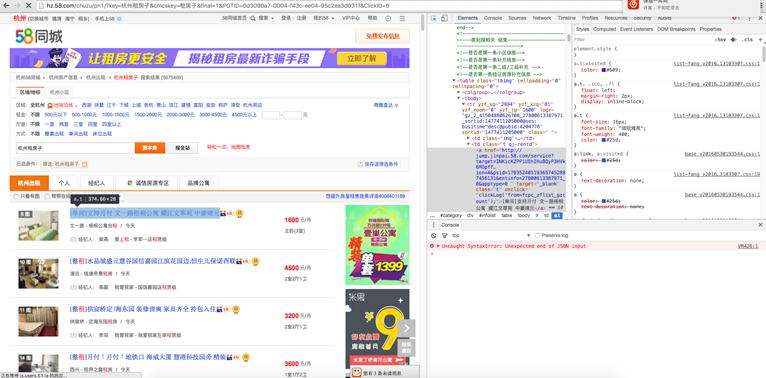
可以看到对应的a标签,我们只需要提取出该url即可,及对应的href,就是它点击跳转的URL。
该a标签的class为t,用$(‘a.t’)即可得到所有的a标签的对象,得到的是一个数组,遍历取出href属性即可。
for(let i = 0; i < (‘a.t’)[i].attribs.href) }
得到了这些URL,接下来就可以用这些URL访问具体的租房信息了,每个URL对应一个租房页面。
根据租房信息的URL访问相应页面,爬取数据
还是先进入页面打开开发者模式。
这次我们需要解析房屋所在地信息,用来可视化显示。
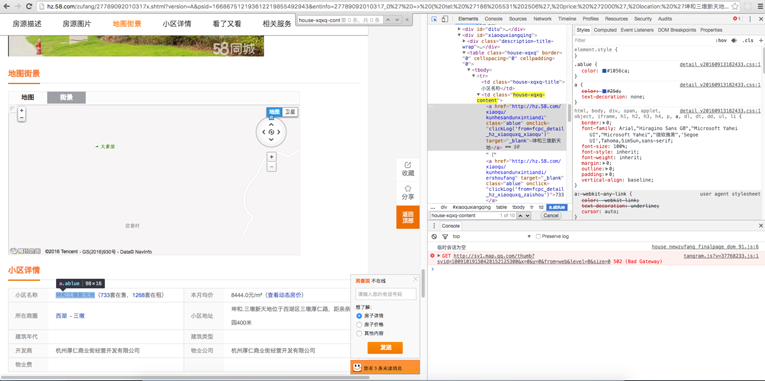
$('td.house-xqxq-content a.ablue')
加上父标签可以过滤出更有针对性的dom,此时过滤出的是小区名称、本月均价、所在商圈等信息的dom,我们现在只需要第一个dom里面的数据,所以访问数组的[0]即可。
除此之外为还需要页面里面的一张展示房屋信息的一张图片,找到对应dom可以发现id为smainPic。
$(‘#smainPic’)[‘0’].attribs.src
这样访问即可得到图片的URL。
其他我们还可以用同样的方法获取很多相关数据,比如(‘span.tel-num.tel-font’).text()可以得到房东的联系方式。
通过百度地图进行可视化展示
这里使用百度地图api
http://lbsyun.baidu.com/index.php?title=jspopular
var map = new BMap.Map(“container”); // 创建地图实例 map.centerAndZoom(“杭州”, 12); var localSearch = new BMap.LocalSearch(map); localSearch.setSearchCompleteCallback(function(searchResult){ var poi = searchResult.getPoi(0);/地理位置信息/ }) ocalSearch.search(params[url].location);
获取经纬度以后再掉用相应的api在地图上显示即可,显示后再做什么效果,可自行发挥想象了。
关于反爬虫
在爬取过程中发现58同城的反爬虫策略,快速访问会让你输入验证码来验证是人在操作而不是代码访问。只要是人可以正常访问并不影响用户正常体验的网站都有办法绕过反爬虫策略。
先采用较慢的方式发送http请求访问,此外每隔一段时间最好停一下,然后再继续访问。除此之外用User-Agent字段伪装成浏览器。最保险的方法就是购买代理,让代理用不同的ip地址去访问网站,即可绕过反爬虫机制。
具体做法可以参照相关反爬虫策略的文章。
关于
作者:染陌
Email:answershuto@gmail.com or answershuto@126.com
Github: https://github.com/answershuto
Blog:http://answershuto.github.io/
知乎专栏:https://zhuanlan.zhihu.com/ranmo
掘金: https://juejin.im/user/58f87ae844d9040069ca7507
osChina:https://my.oschina.net/u/3161824/blog
转载请注明出处,谢谢。
欢迎关注我的公众号