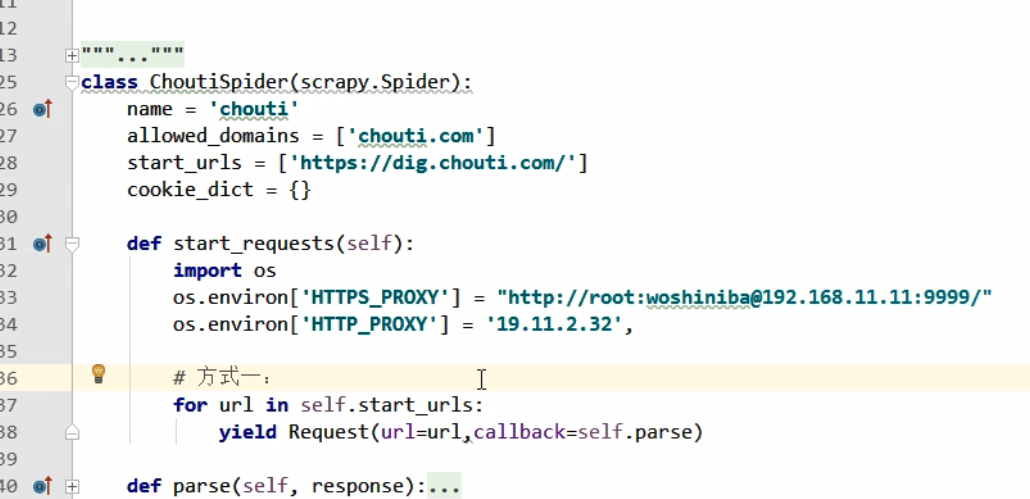
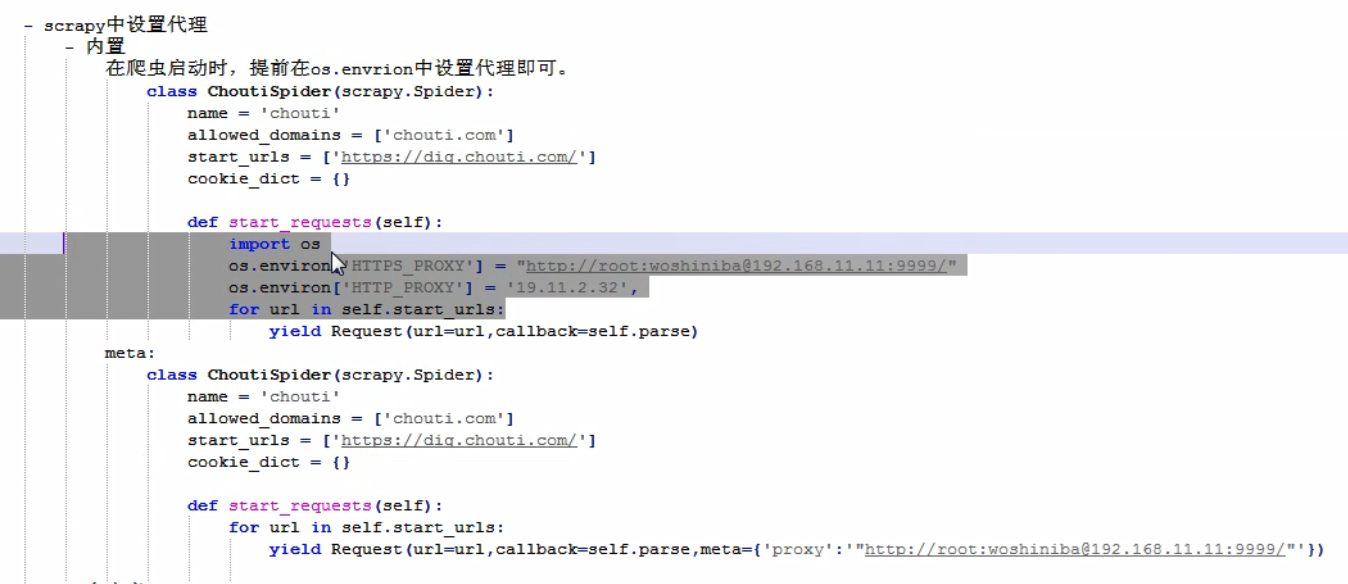
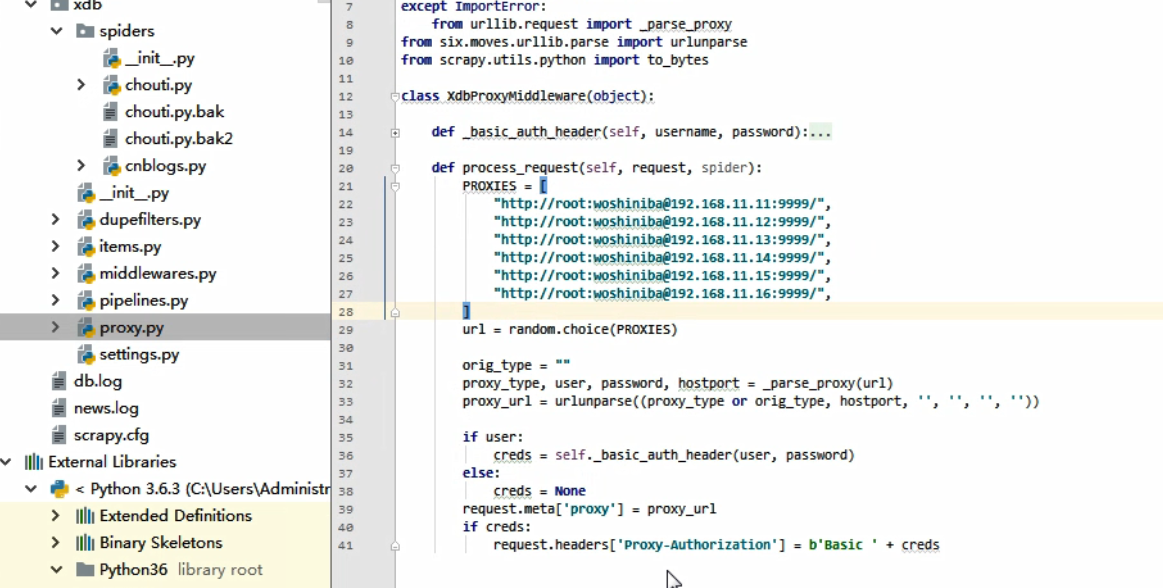

在 middlewares.py 中 更换
https://www.zhihu.com/question/387550141
https://zhuanlan.zhihu.com/p/77172092
class ProxiesMiddleware: ALL_EXCEPTIONS = (defer.TimeoutError, TimeoutError, DNSLookupError, ConnectionRefusedError, ConnectionDone, ConnectError, ConnectionLost, TCPTimedOutError, ResponseFailed, IOError, TunnelError) def __init__(self): self.proxy = redom_proxy() self.count = 0 self.information = self.information_func() def information_func(self): """ 用于计算每隔多久对代理进行更换方法 具体方法 获取更换节点时间 当前时间+7000秒+随机一个50到200之间的一个整数 为未来更换代理的时间 """ return time.time() + 7000 + random.randint(50, 200) def agentExecutable(self, name): """每个请求都会经过这里来重复缺点是否到达该更换代理的时间""" if time.time() > self.information: self.proxy = redom_proxy(spiderhost=name) self.information = self.information_func() def process_request(self, request, spider): source = request.meta.get("source") # 这是spider中传过来的来确定是哪个源的爬虫 if self.count % 10000 == 0 and self.count != 0: spider.logger.info("[一万个请求啦换代理了]") self.proxy = redom_proxy(spiderhost=source) self.count += 1 self.agentExecutable(source) # 用来判断是否需要更换代理 spider.logger.info("[request url] {}".format(request.url)) spider.logger.info("[proxy] {}".format(self.proxy)) request.meta["proxy"] = self.proxy def process_response(self, request, response, spider): if len(response.text) < 3000 or response.status in [403, 400, 405, 301, 302]: source = request.meta.get("source") spider.logger.info("[此代理报错] {}".format(self.proxy)) new_proxy = redom_proxy(spiderhost=source) self.proxy = new_proxy spider.logger.info("[更的的新代理为] {}".format(self.proxy)) new_request = request.copy() new_request_l = new_request.replace(url=request.url) return new_request_l return response def process_exception(self, request, exception, spider): # 捕获几乎所有的异常 if isinstance(exception, self.ALL_EXCEPTIONS): # 在日志中打印异常类型 source = request.meta.get("source") spider.logger.info("[Got exception] {}".format(exception)) spider.logger.info("[需要更换代理重试] {}".format(self.proxy)) new_proxy = redom_proxy(spiderhost=source) self.proxy = new_proxy spider.logger.info("[更换后的代理为] {}".format(self.proxy)) new_request = request.copy() new_request_l = new_request.replace(url=request.url) return new_request_l # 打印出未捕获到的异常 spider.logger.info("[not contained exception] {}".format(exception))