随机森林的Python实现 (RandomForestClassifier)

# -*- coding: utf-8 -*- """ RandomForestClassifier skleran 的随机森林回归模型,应用流程。 2.源数据随机的切分:75%作为训练数据 25%最为测试数据 1.训练数据中的因变量(分类变量)处理成数字形式 3.设定参数,训练/fit 4.对测试数据,预测/predict结果y_pre 5.对预测数据y列,y_pre列,生成混淆矩阵,显示分类/预测效果 """
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier import pandas as pd import numpy as np iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) #合并 自变量 和 因变量 df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75 #相当于随机抽取了75%作为训练数据 df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names) #将数字类别转为文字类别 df.head() train, test = df[df['is_train']==True], df[df['is_train']==False] #拆分训练集和测试集 features = df.columns[:4] # 前4个指标 为自变量 clf = RandomForestClassifier(n_jobs=2) # n_jobs=2是线程数 y, _ = pd.factorize(train['species']) # 将文字类别 转为数字类别。一种序列化方法。第一参数是序列化后结果,第二个时参考 clf.fit(train[features], y) #训练过程 preds = iris.target_names[clf.predict(test[features])] # 获取测试数据预测结果 pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds']) #生成混淆矩阵
#有意思的输出
clf.feature_importances_ # 输出 自变量的总要程度
clf.predict_proba(test[features]) #输出每个测试样本对应几种数据类型的概率值
150个数据,112做训练 38个最测试.
df数据示例-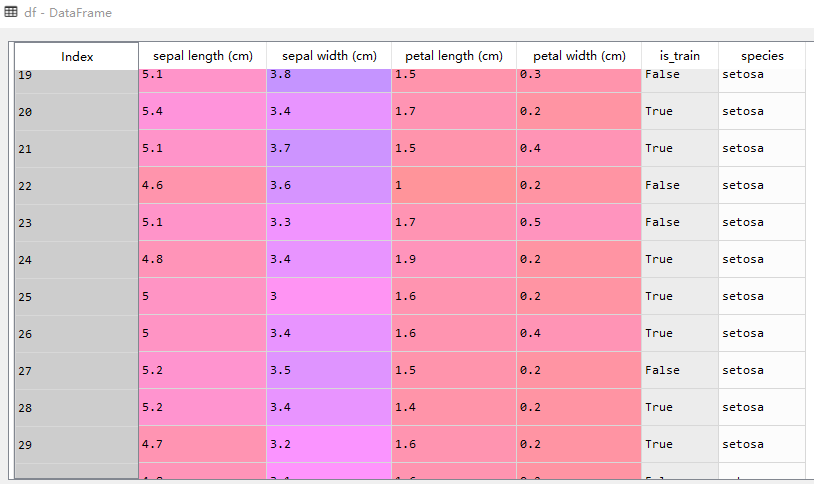 测试数据,输出结果-
测试数据,输出结果-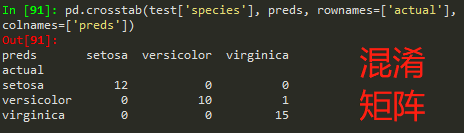
参考:[Machine Learning & Algorithm] 随机森林(Random Forest)
=============================================================================================================
知识点:
对 ‘RandomForestClassifier’ 原文 的 翻译
知识点:
#将数字类别转为文字类别
pd.Categorical.from_codes([0,1,2,1,0,0,1,-1], ['小猫','中猫','大猫'])
#Out[76]:
#[小猫, 中猫, 大猫, 中猫, 小猫, 小猫, 中猫, NaN]
#Categories (3, object): [小猫, 中猫, 大猫]
知识点:
# pd.factorize 用法
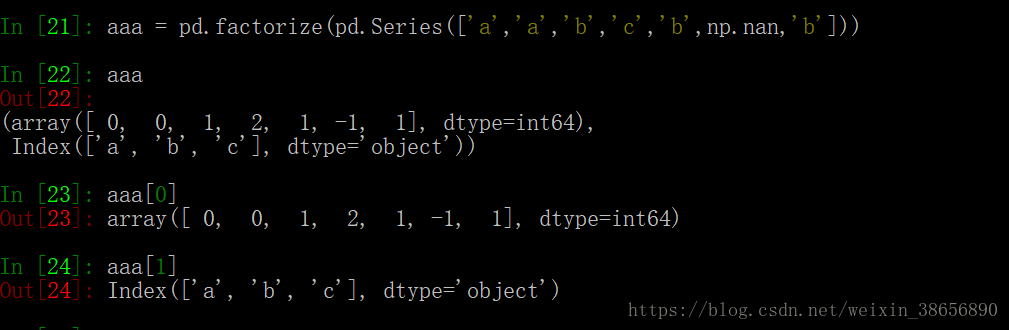
从例子中可以看到 pd.factorize() 返回的是一个tuple ,包含连个元素,第二个是源数据中所有数据的类别,当然取出了nan ,第一个是源数据在类别中对应的序号组成的array 看到这里可以发现 和pd.Categorical() 真的是非常像了。
知识点:
Pandas:透视表(pivotTab)和交叉表(crossTab)
知识点:
numpy.random.seed(1) #设定随机种子且仅在下一次随机时有效.
介绍Python-random模块的链接:
==================================================================================================================================================