目录
from urllib.parse import urlparse, quote, unquote, urlencode
1、解析url的组成成分:urlparse(url)
2、url的base64编解码:quote(url)、unquote(url)
3、字典变成一个字符串=&连接,并且被base64编码:urlencode(字典)
from urllib.parse import urlparse, quote, unquote, urlencode
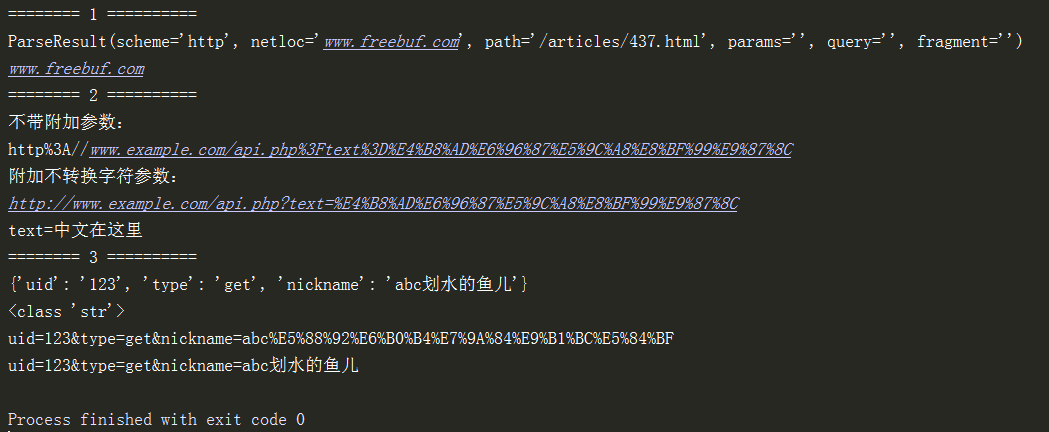
print("======== 1 解析url的组成==========")
url='http://www.freebuf.com/articles/437.html'
url_parse = urlparse(url)
print(url_parse)
print(url_parse.netloc)
print("======== 2 对字符串进行base64编码和反编码==========")
url = 'http://www.example.com/api.php?text=中文在这里'
# 不带附加参数
print('不带附加参数:
%s' % quote(url))
# 附带不转换字符参数
print('附加不转换字符参数:
%s' % quote(url, safe='/:?='))
print(unquote("text%3D%E4%B8%AD%E6%96%87%E5%9C%A8%E8%BF%99%E9%87%8C"))
print("======== 3 对字典转换为=&连接的字符串,并且base64编码==========")
params = {
"uid": "123",
"type": "get",
"nickname": "abc划水的鱼儿",
}
print(params)
data_str_base64 = urlencode(params) # 字典转为字符串,并且base64编码
print(type(data_str_base64))
print(data_str_base64)
data_str_unbase64 = unquote(data_str_base64) # 字符串中base64被反解码
print(data_str_unbase64)
输出结果:
到此看懂了,后面就可以不用看了。
1、解析url的组成成分:urlparse(url)
提取域名domain
from urllib.parse import urlparse url = 'http://www.freebuf.com/articles/437.html' url_parse = urlparse(url) print(url_parse) print(url_parse.netloc) print(url_parse.hostname)
输出:
ParseResult(scheme='http', netloc='www.freebuf.com', path='/articles/437.html', params='', query='', fragment='')
www.freebuf.com
www.freebuf.com
2、url的base64编解码:quote(url)、unquote(url)
url的base64编码 、解码
from urllib.parse import quote
url = 'http://www.example.com/api.php?text=中文在这里'
# 不带附加参数
print('
不带附加参数:
%s' % quote(url))
# 附带不转换字符参数
print('
附加不转换字符参数:
%s' % quote(url, safe='/:?='))
输出结果:

base64解码
print(unquote("text%3D%E4%B8%AD%E6%96%87%E5%9C%A8%E8%BF%99%E9%87%8C"))
(一)字符串转义为base64编码和解码(和上文重复,不用看)
import urllib.parse url_han = 'https://www.baidu.com/s?wd=北京' print(urllib.parse.quote(url_han)) # base64编码 # https%3A//www.baidu.com/s%3Fwd%3D%E5%8C%97%E4%BA%AC url_base64 = 'https://www.baidu.com/s?wd=%E6%B7%B1%E5%9C%B3' print(urllib.parse.unquote(url_base64)) # base64反编码 # https://www.baidu.com/s?wd=深圳
3、字典变成一个字符串=&连接,并且被base64编码
(二)字典转化为&连接的字符串
说明:字典转字符串后,发生了2件事
1、冒号变成等号;逗号变成&
2、汉字和特殊字符被base64编码
案例:
源代码:
import urllib.parse
params = {
"uid": "123",
"type": "get",
"nickname": "abc划水的鱼儿",
}
print(params)
data_str_base64 = urllib.parse.urlencode(params) # 字典转为字符串,并且base64编码
print(type(data_str_base64))
print(data_str_base64)
data_str_unbase64 = urllib.parse.unquote(data_str_base64) # 字符串中base64被反解码
print(data_str_unbase64)
输出结果:
{'uid': '123', 'type': 'get', 'nickname': 'abc划水的鱼儿'}
<class 'str'>
uid=123&type=get&nickname=abc%E5%88%92%E6%B0%B4%E7%9A%84%E9%B1%BC%E5%84%BF
uid=123&type=get&nickname=abc划水的鱼儿