首先,rollback到底是什么意思呢?在关系型数据库中因为有事务的概念,操作数据后在没有commit之前是可以执行rollback命令进行数据回退的。
而在单实例mongodb中,写入就写入了,删除就删除了,没有事务的概念,也没有rollback的操作,所以这里要讨论的是replicaset(复制集)的rollback
事故演示:
步骤1: 客户端向Primary写入3笔数据 1、2、3, 经过oplog日志后同步到secondary节点上,此时各个节点数据一致
步骤2: 但当Primary节点再次被写入一笔数据4的时候,发生宕机,此时 数据4 还没来得及同步到从节点上
步骤3: 此时集群短时间关闭写操作开始竞选,经过一系列选举后有了新的primary节点,此时新Primary节点上是没有数据4的
步骤4: 新的primary承接了客户端的write请求,写入新数据 5,此时新primary的数据状态为1,2,3,5
步骤5: 原primary节点重新启动后申请加入replica member作为secondary节点,因为此时它与新primary数据不一致,
所以就会发生rollback(回滚)动作,将数据状态恢复为1,2,3
步骤6:回滚完之后,将继续同步新primary节点的数据,之后数据状态变为1,2,3,5
rollback发生的具体过程:
请看下图

流程说明:
客户端驱动在连接mongo之后进行写操作的大致流程就是这样的,写操作会按照编号顺序进行, 当Client收到5号的response反馈后即认为写入成功,
而如何数据已写入journal files,但是尚未oplog同步到Secondary节点重放,如果此时发生Primary宕机,则就会造成主从之间数据不一致,即原Primary中有
刚才新写入的数据,但新选举出来的Primary却没有那部分数据,从来造成数据丢失
结论:
综上所述,rollback的发生,主要是Primary写入数据后还未来得及同步到secondary节点时,发生宕机事故,导致数据缺失,
经重新选举后产生新primary节点,但当原Primary重新加入集群时,由于要追随新Primary节点进行强一致性处理,所以会回滚宕机前未同步的数据。
存放位置:
那么回滚的数据跑到哪里去了呢?当rollback发生时,MongoDB将把rollback的数据以BSON格式存放到dbpath路径下rollback文件夹中,BSON文件的命名格式如下:
<database>.<collection>.<timestamp>.bson
还原数据:
那么这个rollback数据如何写回到mongodb呢?我们可以利用mongorestore命令进行基于文件的恢复操作,具体操作可以看我另外一篇关于mongodump/mongorestore的文章
mongorestore --host <hostname:port> --db db1 --collection c2 -u admin_user -p"123456"
--authenticationDatabase admin rollback/c2_rollback.BSON
同步源:
链式复制
平时我们都说主备同步主备同步,那同步源肯定是主节点了?其实不一定,MongoDB很早就支持了链式复制,即备节点可以从另外一个备节点拉取oplog,而不只从主节点拉取。这样一来可以减少主节点的负载,二来各节点可以选择离自己近的节点进行同步。当然,在某些情况下,这可能会导致一些备节点的延迟变大。链式复制可以通过以下命令来打开或关闭:
cfg = rs.config()
cfg.settings.chainingAllowed = true/false
rs.reconfig(cfg)
Secondary节点如何选择同步源
Secondary节点会根据以下原则选择一个同步源:
- 如果之前有通过命令replSetSyncFrom指定了同步源,那么使用此同步源
- 由于后续需要根据到其他节点的ping值(通过心跳进行统计)信息进行选择,这里会判断一下是否已有足够的信息,需要等待更多的心跳包,如果不需要,继续,否则直接返回,等下次需要选择时再看
- 如果没有开启Chained Replication(链式复制),那么选择Primary
4、通过两轮选择,基于以下规则选择一个ping值最低的节点:
i 如果自己可以建索引,那么只能从同样可以建索引的节点同步
ii oplog的时间戳比我新(这里是获取该节点上次心跳包里带的appliedOpTime的时间戳进行比较)
iii 不在黑名单中(注:何时将同步节点加进黑名单?1. 连接不上该节点,加10s黑名单;2. 落后该节点太多无法继续同步,加1min黑名单)
其中在第一轮选择中,会额外考虑以下条件:
1、拥有投票权的节点只能从同样拥有投票权的节点同步
2、不能从hidden节点同步
3、不能从落后Primary太多(超过配置的maxSyncSourceLagSecs)的节点同步
4、不能从配置了比自己拥有更大delay的节点同步
如果第一轮没有选出合适的节点,那么再进行第二轮选择,放宽上述条件的限制。
避免策略:
要讲避免策略那就应先讲讲Write Concern(写关注),也就是关心写操作。是在驱动的connection level进行配置,
支持一下值:
w:0 | 1 | n | majority | tag
j:1
wtimeout: millis
w:0 unacknowledged
驱动只是一味的进行写入操作,不会关心是否写入成功,也就是mongo不会返回操作结果
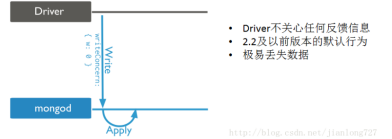
w:1 Acknowledged
看图我们很容易理解,Driver在做写入操作后会收到mongod的反馈OK还是NG,而这个反馈行为只是在确认数据被成功写入Data Buffer,Journal Buffer
后的状态,不保证数据能够被写入datafile(落盘)

J:1 Journaled
驱动写操作不仅要写入Journal Buffer,Data Buffer中,还要确认数据持久化到Journal file中后才反馈结果。
即使数据库宕机,重启后,操作已经持久化到journal中,可以完全恢复,但前提是mongod一定要开启journal参数
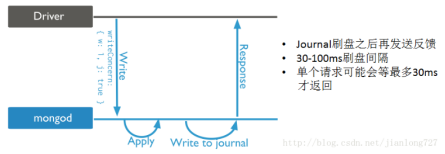
w:2/n/majority Replica Acknowledged
看到下图,你应该就明白一半了,好的,下一半让小弟再给你解释一下。
rollback的发生就是因为数据成功写入Primary,但是尚未同步到Secondary节点,此时Primary宕机,
当原Primary重新加入集群后则会发生灰色数据自行rollback的现象,那么怎么避免呢?当然就是在发送反馈信息给驱动前
确保数据已经更新到至少一个Secondary节点,不就完美解决此问题了。是的,使用w:2/n/majority的配置参数
就能实现,当然,为了防止网络问题出现阻塞等待,我们可以设置wtimeout

整理于网络 https://blog.csdn.net/jianlong727/article/details/73321905