在这一章,将解释为MySQL服务器创建一个靠谱的配置文件的过程。这是一个很绕的过程,有很多有意思的关注点和值得关注的思路。关注这些点很有必要,因为创建一个好配置的最快方法不是从学习配置项开始,也不是从问哪个配置项应该怎么设置或者怎么修改开始,更不是从检査服务器行为和询问哪个配置项可以提升性能开始。最好是从理解MySQL内核和行为开始。然后可以利用这些知识来指导配置MySQL。最后,可以将想要的配置和当前配置进行比较,然后纠正重要并且有价值的不同之处。
人们经常问,“我的服务器有32GB内存,12核CPU,怎样配置最好?”很遗憾,问题没这么简单。服务器的配置应该符合它的工作负载、数据,以及应用需求,并不仅仅看硬件的情况。
MySQL有大量可以修改的参数——但不应该随便去修改。通常只需要把基本的项配置正确(大部分情况下只有很少一些参数是真正重要的),应该将更多的时间花在schema的优化、索引,以及査询设计上。在正确地配置了MySQL的基本配置项之后,再花力气去修改其他配置项的收益通常就比较小了。
从另一方面来说,没用的配置导致潜在风险的可能更大。我们碰到过不止一个“高度调优”过的服务器不停地崩溃,停止服务或者运行缓慢,结果都是因为错误的配置导致的。我们将花一点时间来解释为什么会发生这种情况,并且告诉大家什么是不该做的。
那么什么是该做的呢?确保基本的配置是正确的,例如InnoDB的Buffer Pool和日志文件缓存大小,如果想防止出问题(提醒一下,这样做通常不能提升性能——它们只能避免问题),就设置一个比较安全和稳健的值,剩下的配置就不用管了。如果碰到了问题,那就小心地进行诊断。如果问题是由于服务器的某部分导致的,而这恰好可以通过某个配置项解决,那么需要做的就是更改配置。
有时候,在某些特定的场景下,也有可能设置某些特殊的配置项会有显著的性能提升。但无论如何,这些特殊的配置项不应该成为服务器基本配置文件的一部分。只有当发现特定的性能问题才应该设置它们。这就是为什么我们不建议通过寻找有问题的地方修改配置项的原因。如果有些地方确实需要提升,也需要在査询响应时间上有所体现。最好是从査询语句和响应时间入手来开始分析问题,而不是通过配置项。这可以节省大量的时间,避免很多的问题。
另一个节省时间和避免麻烦的好办法是使用默认配置,除非是明确地知道默认值会有问题。很多人都是在默认配置下运行的,这种情况非常普遍。这使得默认配置是经过最多实际测试的。对配置项做一些不必要的修改可能会遇到一些意料之外的bug。
1.MySQL配置的工作原理
在讨论如何配置MySQL之前,我们先来解释一下MySQL的配置机制。MySQL对配置要求非常宽松,但是下面这些建议可能会为你节省大量的工作和时间。
首先应该知道的是MySQL从哪里获得配置信息:命令行参数和配置文件。在类UNIX系统中,配置文件的位置一般在/etc/my.cnf或者/etc/mysql/my.cnf。如果使用操作系统的启动脚本,这通常是唯一指定配置设置的地方。如果手动启动MySQL,例如在测试安装时,也可以在命令行指定设置。实际上,服务器会读取配置文件的内容,删除所有注释和换行,然后和命令行选项一起处理。
任何打算长期使用的设置都应该写到全局配置文件,而不是在命令行特别指定。否则,如果偶然在启动时忘了设置就会有风险。把所有的配置文件放在同一个地方以方便检査也是个好办法:
配置文件通常分成多个部分,每个部分的开头是一个用方括号括起来的分段名称。MySQL程序通常读取跟它同名的分段部分,许多客户端程序还会读取client部分,这是一个存放公用设置的地方。服务器通常读取mysqld这一段。一定要确认配置项放在了文件正确的分段中,否则配置是不会生效的。
1.1 语法、作用域和动态性
配置项设置都使用小写,单词之间用下画线或横线隔开。下面的例子是等价的,并且可能在命令行和配置文件中都看到这两种格式:
/usr/sbin/mysqld --auto-increment-offset=5 /usr/sbin/mysqld --auto_increment_offset=5
建议使用一种固定的风格。这样在配置文件中搜索配置项时会容易得多。
配置项可以有多个作用域。有些设置是服务器级的(全局作用域),有些对每个连接是不同的(会话作用域),剩下的一些是对象级的。许多会话级变量跟全局变量相等,可以认为是默认值。如果改变会话级变量,它只影响改动的当前连接,当连接关闭时所有参数变更都会失效。下面有一些例子,应该清楚这些不同类型的行为:
- query_cache_size变量是全局的。
- sort_buffer_size变量默认是全局相同的,但是每个线程里也可以设置。
- join_buffer_size变量也有全局默认值且每个线程是可以设置的,但是若一个査询中关联多张表,可以为每个关联分配一个关联缓冲(join buffer),所以每个查询可能有多个关联缓冲。
另外,除了在配置文件中设置变量,有很多变量(但不是所有)也可以在服务器运行时修改。MySQL把这些归为动态配置变量。下面的语句展示了动态改变sort_buffer_size的会话值和全局值的不同方式:
SET sort_buffer_size = <value>; SET GLOBAL sort_buffer_size = <value>; SET @@sort_buffer_size := <value>; SET @@session.sort_buffer_size := <value>; SET @@global.sort_buffer_size := <value>;
如果动态地设置变量,要注意MySQL关闭时可能丢失这些设置。如果想保持这些设置,还是需要修改配置文件。
如果在服务器运行时修改了变量的全局值,这个值对当前会话和其他任何已经存在的会话都不起效果,这是因为会话的变量值是在连接创建时从全局值初始化来的。在每次变更之后,应该检査SHOW GLOBAL VARIABLES的输出,确认已经按照期望变更了。
有些变量使用了不同的单位,所以必须知道每个变量的正确单位。例如,table_cache变量指定了表可以被缓存的数量,而不是表可以被缓存的字节数。key_buffer_size则是以字节为单位,还有一些其他变量指定的是页的数量或者其他单位,例如百分比。
许多变量可以通过后缀指定单位,例如1M表示一百万字节。然而,这只能在配置文件或者作为命令行参数时有效。当使用SQL的SET命令时,必须使用数字值1048576,或者1024*1024这样的表达式。但在配置文件中不能使用表达式。
有个特殊的值可以通过SET命令赋值给变量:DEFAULT。把这个值赋给会话级变量可以把变量改为使用全局值,把它赋值给全局变量可以设置这个变量为编译内置的默认值(不是在配置文件中指定的值)。当需要重置会话级变量的值回到连接刚打开的时候,这是很有用的。建议不要对全局变量这么用,因为可能它做的事不是你希望的,它不会把值设置到服务器刚启动时候的那个状态。
1.2 设置变量的副作用
动态设置变量可能导致意外的副作用,例如从缓冲中刷新脏块。务必小心那些可以在线更改的设置,因为它们可能导致数据库做大量的工作。
有时可以通过名称推断一个变量的作用。例如,max_heap_table_size的作用就像听起 来那样:它指定隐式内存临时表最大允许的大小。然而,命名约定并不完全一样,所以不能总是通过看名称来猜测一个变量有什么效果。
让我们来看一些常用的变量和动态修改它们的效果。
key_buffer_size
设置这个变量可以一次性为键缓冲区(key buffer,也叫键缓存key cache)分配所有指定的空间。然而,操作系统不会真的立刻分配内存,而是到使用时才真正分配。
例如设置键缓冲的大小为1GB,并不意味着服务器立刻分配1GB的内存。
MySQL允许创建多个键缓存,这一章后面会探讨这个问题。如果把非默认键缓存的这个变量设置为0, MySQL将丢弃缓存在该键缓存中的索引,转而使用默认键缓存,并且当不再有任何引用时会删除该键缓存。为一个不存在的键缓存设置这个变量,将会创建新的键缓存。对一个已经存在的键缓存设置非零值,会导致刷新该键缓存的内容。这会阻塞所有尝试访问该键缓存的操作,直到刷新操作完成。
table_cache_size
设置这个变量不会立即生效——会延迟到下次有线程打开表才有效果。当有线程打开表时,MySQL会检査这个变量的值。如果值大于缓存中的表的数量,线程可以把最新打开的表放入缓存;如果值比缓存中的表数小,MySQL将从缓存中删除不常使用的表。
thread_cache_size
设置这个变量不会立即生效——将在下次有连接被关闭时产生效果。当有连接被关闭时,MySQL检查缓存中是否还有空间来缓存线程。如果有空间,则缓存该线程以备下次连接重用;如果没有空间,它将销毁该线程而不再缓存。在这个场景中,缓存中的线程数,以及线程缓存使用的内存,并不会立刻减少;只有在新的连接删除缓存中的一个线程并使用后才会减少。(MySQL只在关闭连接时才在缓存中增加线程,只在创建新连接时才从缓存中删除线程。)
query_cache_size
MySQL在启动的时候,一次性分配并且初始化这块内存。如果修改这个变量(即使设置为与当前一样的值),MySQL会立刻删除所有缓存的査询,重新分配这片缓存到指定大小,并且重新初始化内存。这可能花费较长的时间,在完成初始化之前服务器都无法提供服务,因为MySQL是逐个清理缓存的査询,不是一次性全部删掉。
read_buffer_size
MySQL只会在有查询需要使用时才会为该缓存分配内存,并且会一次性分配该参数指定大小的全部内存。
read_rnd_buffer_size
MySQL只会在有査询需要使用时才会为该缓存分配内存,并且只会分配需要的内存大小而不是全部指定的大小。(max_read_rnd_buffer_size这个名字更能表达这个变量实际的含义。)
sort_buffer_size
MySQL只会在有査询需要做排序操作时才会为该缓存分配内存。然后,一旦需要排序,MySQL就会立刻分配该参数指定大小的全部内存,而不管该排序是否需要这么大的内存。
我们在其他地方也对这些参数做过更多细节的说明,这里不是一个完整的列表。这里的目的只是简单地告诉大家,当修改一些常见的变量时,会有哪些期望的行为发生。
对于连接级别的设置,不要轻易地在全局级别增加它们的值,除非确认这样做是对的。有一些缓存会一次性分配指定大小的全部内存,而不管实际上是否需要这么大,所以一个很大的全局设置可能导致浪费大量内存。更好的办法是,当査询需要时在连接级别单独调大这些值。
最常见的例子是sort_buffer_size,该参数控制排序操作的缓存大小,应该在配置文件里把它配置得小一些,然后在某些査询需要排序时,再在连接中把它调大。在分配内存后,MySQL会执行一些初始化的工作。
另外,即使是非常小的排序操作,排序缓存也会分配全部大小的内存,所以如果把参数设置得超过平均排序需求太多,将会浪费很多内存,增加额外的内存分配开销。许多读者认为内存分配是一个很简单的操作,听到内存分配的代价可能会很吃惊。不需要深入很多技术细节就可以讲清楚为什么内存分配也是昂贵的操作,内存分配包括了地址空间的分配,这相对来说是比较昂贵的。特别在Linux上,内存分配根据大小使用多种开销不同的策略。
总的来说,设置很大的排序缓存代价可能非常高,所以除非确定必须要这么大,否则不要增加排序缓存的大小。
如果査询必须使用一个更大的排序缓存才能比较好地执行,可以在査询执行前增加sort_buffer_size的值,执行完成后恢复为DEFAULT。
下面是一个实际的例子:
SET @@session.sort_buffer_size := <value>; -- Execute the query... SET @@session.sort_buffer_size := DEFAULT;
可以将类似的代码封装在函数中以方便使用。其他可以设置的单个连接级别的变量有read_buffer_size、read_rnd_buffer_size、tmp_table_size、以及myisam_sort_buffer_size(在修复表的操作中会用到)。
如果有需要也可以保存并还原原来的自定义值,可以像下面这样做:
SET @saved_<unique_variable_name> := @@session.sort_buffer_size; SET @@session.sort_buffer_size := <value>; -- Execute the query... SET @@session.sort_buffer_size := @saved_<unique_variable_name>;
提示:排序缓冲大小是关注的众多“调优”中一个设置。一些人似乎认为越大越好,我们甚至见过把这个变量设为1GB的。这可能导致服务器尝试分配太多内存而崩溃,或者为査询初始化排序缓存时消耗大量的CPU,这不是什么出乎意料的事。从MySQL的Bug 37359可以看到有关于这个问题的细节。
不要把排序缓存大小放在太重要的位置。査询真的需要128MB的内存来排序10行数据然后返回给客户端吗?思考一下査询语句是什么类型的排序、多大的排序,首先考虑通过索引和SQL写法来避免排序,这比调优排序缓存要快得多。并且应该仔细分析査询开销,看看排序是否是无论如何都需要重点关注的部分。
1.3 入门
设置变量时请小心,并不是值越大就越好,而且如果设置的值太髙,可能更容易导致问题:可能会由于内存不足导致服务器内存交换,或者超过地址空间。
应该始终通过监控来确认生产环境中变量的修改,是提高还是降低了服务器的整体性能。基准测试是不够的,因为基准测试不是真实的工作负载。如果不对服务器的性能进行实际的测量,可能性能降低了都没有发现。我们见过很多情况,有人修改了服务器的配置,并认为它提髙了性能,其实服务器的整体性能恶化了,因为在一个星期或一天的不同时间,工作负载是不一样的。
如果你经常做笔记,在配置文件中写好注释,可能会节省自己(和同事)大量的工作。一个更好的主意是把配置文件置于版本控制之下。无论如何,这是一个很好的做法,因为它让你有机会撤销变更。要降低管理很多配置文件的复杂性,简单地创建一个从配置文件到中央版本控制库的符号链接。
在开始改变配置之前,应该优化査询和schema,至少先做明显要做的事情,例如添加索引。如果先深入调整配置,然后修改了査询语句和schema,也许需要回头再次评估配置。请记住,除非硬件、工作负载和数据是完全静态的,否则都可能需要重新检査配置文件。实际上,大部分人的服务器甚至在一天中都没有稳定的工作负载——意味着对上午来说“完美”的配置,下午就不对了!显然,追求传说中的“完美”配置是完全不切实际的。因此,没有必要榨干服务器的每一点性能,实际上,这种调优的时间投入产出是非常小的。我们建议在“足够好”的时候就可以停下了,除非有理由相信停下会导致放弃重大的性能提升的机会。
1.4 通过基准测试迭代优化
你也许期望(或者相信自己会期望)通过建立一套基准测试方案,然后不断迭代地验证对配置项的修改来找到最佳配置方案。通常我们都不建议大家这么做。这需要做非常多的工作和研究,并且大部分情况下潜在的收益是非常小的,这可能导致巨大的时间浪费。而把时间花在检査备份、监控执行计划的变动之类的事情上,可能会更有意义。
即使更改一个选项后基准测试出现了提升,也无法知道长期运行后这个变更会有什么副作用。基准测试也不能衡量一切,或者没有运行足够长的时间来检测系统的长期稳定性,修改就可能导致如周期性性能抖动或者周期性的慢查询等问题。这是很难察觉到的。
有的时候我们运行某些组合的基准测试,来仔细验证或压测服务器的某些特定部分,使得我们可以更好地理解这些行为。一个很好的例子是,我们使用了很多年的一些基准测试,用来理解InnoDB的刷新行为,来寻找更好的刷新算法,以适应多种工作负载和多种硬件类型。我们经常测试各种各样的设置,来理解它们的影响以及怎么优化它们。但这不是一件简单的事——这可能会花费很多天甚至很多个星期——而且对大部分人来说这没有收益,因为服务器特定部分的认识局限往往会掩盖了其他问题。例如,有时我们发现,特定的设置项组合,在特定的边缘场景可能有更好的性能,但是在实际生产环境这些配置项并不真的合适,例如,浪费大量的内存,或者优化了吞吐量却忽略了崩溃恢复的影响。
如果必须这样做,我们建议在开始配置服务器之前,开发一个定制的基准测试包。你必须做这些事情来包含所有可能的工作负载,甚至包含一些边缘的场景,例如很庞大很复杂的査询语句。在实际的数据上重放工作负载通常是一个好办法。如果已经定位到了一个特定的问题点——例如一个査询语句运行很慢——也可以尝试专门优化这个点,但是可能不知道这会对其他査询有什么负面影响。
最好的办法是一次改变一个或两个变量,每次一点点,每次更改后运行基准测试,确保 运行足够长的时间来确认性能是否稳定。有时结果可能会令你感到惊讶,可能把一个变量调大了一点,观察到性能提升,然后再调大一点,却发现性能大幅下降。如果变更后性能有隐患,可能是某些资源用得太多了,例如,为缓冲区分配太多内存、频繁地申请和释放内存。另外,可能导致MySQL和操作系统或硬件之间的不匹配。例如,我们发现sort_buffer_size的最佳值可能会被CPU缓存的工作方式影响,还有read_buffer_size需要服务器的预读和I/O子系统的配置相匹配。更大并不总是更好,还可能更糟糕。一些变量也依赖于一些其他的东西,这需要通过经验和对系统架构的理解来学习。
讨论:什么情况下进行基准测试是好的建议
对于前面提到不建议大多数人执行基准测试的情况也有例外的时候。我们有时会建议人们跑一些迭代基准测试,尽管通常跟“服务器调优”有不同的内容。这里有一些例子:
- 如果有一笔大的投资,如购买大量新的服务器,可以运行一下基准测试以了解硬件需求。(这里的上下文指是容量规划,不是服务器调优),我们特别喜欢对不同大小的InnoDB缓冲池进行基准测试,这有助于我们制定一个“内存曲线”,以展示真正需要多少内存,不同的内存容量如何影响存储系统的要求。
- 如果想了解InnoDB从崩溃中恢复需要多久时间,可以反复设置一个备库,故意让它崩溃,然后“测试”InnoDB在重启中需要花费多久时间来做恢复。这里的背景是做高可用性的规划。
- 以读为主的应用程序,在慢查询日志中捕捉所有的查询(或者用pt-query-digest对分析TCP流量)是个很好的主意,在服务器完全打开慢查询日志记录时,使用pt-log-player重放所有的慢查询,然后pt-query-digest用来分析输出报告。这可以观察在不同硬件、软件和服务器设置下,查询语句运行的情况。例如,我们曾经帮助客户评估迁移到更多的内存但硬盘更慢的服务器上的性能变化。大多数查询变得更快,但一些分析型查询语句变慢,因为它们是I/O密集型的。这个测试的上下文背景就是不同工作负载的比较。
2.什么不该做
在开始配置服务器之前,希望鼓励大家去避免一些我们已经发现有风险或有害的做法。警告:本节有些观点可能会让有些人不舒服!
首先,不要根据一些“比率”来调优。一个经典的按“比率”调优的经验法则是,键缓存的命中率应该高于某个百分比,如果命中率过低,则应该增加缓存的大小。这是非常错误的意见。无论别人怎么跟你说,缓存命中率跟缓存是否过大或过小没有关系。首先,命中率取决于工作负载——某些工作负载就是无法缓存的,不管缓存有多大——其次,缓存命中没有什么意义,将在后面解释原因。有时当缓存太小时,命中率比较低,增加缓存的大小确实可以提高命中率。然而,这只是个偶然情况,并不表示这与性能或适当的缓存大小有任何关系。
这种相关性,有时候看起来似乎真正的问题是,人们开始相信它们将永远是真的。Oracle DBA很多年前就放弃了基于命中率的调优,我们希望MySQL DBA也能跟着走。我们更强烈地希望人们不要去写“调优脚本”,把这些危险的做法编写到一起,并教导成千上万的人这么做。这引出了我们第二个不该做的建议:不要使用调优脚本!有几个这样的可以在互联网上找到的脚本非常受欢迎,最好是忽略它们。
(如果你还是不相信“按比率调优”的方法是错误的,请阅读Cary Millsap的Optimizing Oracle Performance(O’Reilly出版)。他甚至为这个主题专门写了一个附录,提供了一个可以智能地产生任何你想要的命中率的工具,甚至不管系统正运行得多么糟糕都可以做到很好的命中率!当然,这一切的目的都是为了说明比率是多么无用。)
我们还建议避免调(timing)这个词,我们在前面几段中使用这个词是有点随意的。我们更喜欢使用“配置(Configuration)”或“优化(Optimize)”来代替。“调优”这个词,容易让人联想到一个缺乏纪律的新手对服务器进行微调,并观察发生了什么。我们建议上一节的练习最好留给那些正在研究服务器内核的人。“调优”服务器可能浪费大量的时间。
另外说一句,在互联网搜索如何配置并不总是一个好主意。在博客、论坛等地方都可能找到很多不好的建议。虽然许多专家在网上贡献了他们了解的东西,但并不总是能容易地分辨出哪些是正确的建议。我们也不能给出中肯的建议在哪里能找到真正的专家但我们可以说,可信的、声誉好的MySQL服务供应商一般比简单的互联网搜索更安全,因为有好的客户才可能做出正确的事情。然而,即使是他们的意见,没有经过测试和理解就使用,也可能有危险,因为它可能对某种解决方案有了思维定势,跟你的思维不一样,可能用了一种你无法理解的方法。
最后,不要相信很流行的内存消耗公式——是的,就是MySQL崩溃时自身输出的那个内存消耗公式(我们这里就不再重复了)。这个公式已经很古老了,它并不可靠,甚至也不是一个理解MySQL在最差情况下需要使用多少内存的有用的办法。在互联网上可能还会看到这个公式的很多变种。即使在原公式上增加了更多原来没有考虑到的因素,还是有同样的缺陷。事实上不可能非常准确地把握MySQL内存消耗的上限。MySQL不是一个完全严格控制内存分配的数据库服务器。这个结论可以非常简单地证明,登录到服务器,并执行一些大量消耗内存的査询:
mysql> SET @crash_me_1 := REPEAT('a', @@max_allowed_packet); mysql> SET @crash_me_2 := REPEAT('a', @@max_allowed_packet); # ... run a lot of these ... mysql> SET @crash_me_1000000 := REPEAT('a', @@max_allowed_packet);
在一个循环中运行这些语句,每次都创建新的变量,最后服务器内存必然耗尽,然后系统崩溃!运行这个测试不需要任何特殊权限。
3.创建MySQL配置文件
正如在开头提到的,没有一个适合所有场景的“最佳配置文件”,比方说,对一台有16GB内存和12块硬盘的4路CPU服务器,不会有一个相应的“最佳配置文件”。应该开发自己的配置,因为即使是一个好的起点,也依赖于具体是如何使用服务器的。
MySQL编译的默认设置并不都是靠谱的,虽然其中大部分都比较合适。它们被设计成不要使用大量的资源,因为MySQL的使用目标是非常灵活的,它并没有假设自己是服务器上唯一的应用。默认情况下,MySQL只是使用恰好足够的资源来启动,运行一些少量数据的简单査询。如果有超过几MB的数据,就一定会需要自己定制MySQL配置。
你可能会先从一个包含在MySQL发行版本中的示例配置文件开始,但这些示例配置有自己的问题。例如,它们有很多注释掉的设置,可能会诱使你认为应该选择一个值,并取消注释(这有点让人联想到Apache配置文件)。同时它们有很多乏味的注释,只是为了解释选项的含义,但这些解释并不总是通顺、完整甚至正确的,有些选项甚至并不适用于流行的操作系统!最后,这些示例相对于现代的硬件和工作负载,总是过时的。
MySQL专家们关于如何解决这些问题多年来进行了许多对话,但这些问题依然存在。下面是我们的建议:不要使用这些文件作为(创建配置文件的)起点,也不要使用操作系统的安装包自带的配置文件。最好是从头开始。
这就是本章要做的事情。实际上MySQL的可配置性太强也可以说是个弱点,看起来好像需要花很多时间在配置上,其实大多数配置的默认值已经是最佳配置了,所以最好不要改动太多配置,甚至可以忘记某些配置的存在。这就是为什么这里创建了一个完整的最小的示例配置文件,可以作为自己的服务器配置文件的一个好的起点。有一些配置项是必选的,将在本章稍后解释。下面就是这个基础配置文件:
[mysqld] # GENERAL datadir = /var/lib/mysql socket = /var/lib/mysql/mysql.sock pid_file = /var/lib/mysql/mysql.pid user = mysql port = 3306 storage_engine = InnoDB # INNODB innodb_buffer_pool_size = <value> innodb_log_file_size = <value> innodb_file_per_table = 1 innodb_flush_method = O_DIRECT # MyISAM key_buffer_size = <value> # LOGGING log_error = /var/lib/mysql/mysql-error.log log_slow_queries = /var/lib/mysql/mysql-slow.log # OTHER tmp_table_size = 32M max_heap_table_size = 32M query_cache_type = 0 query_cache_size = 0 max_connections = <value> thread_cache_size = <value> table_cache_size = <value> open_files_limit = 65535 [client] socket = /var/lib/mysql/mysql.sock port = 3306
和你见过的其他配置文件相比,这里的配置选项可能太少了。但实际上已经超过了许多人的需要。有一些其他类型的配置选项可能也会用到,比如二进制日志,会在本章后面以及其他章节覆盖这些内容。
配置文件的第一件事是设置数据的位置。选择了/var/lib/mysql路径存储数据,因为在许多类UNIX系统中这是最常见的位置。选择另外的位置也没有错,可以根据需要决定。我们把PID文件也放到相同的位置,但许多操作系统希望放在目录下,这也可以。只需要简单地为这些选项配置一下就可以了。顺便说一下,不要把Socket文件和PID文件放到MySQL编译默认的位置,在不同的MySQL版本里这可能会导致一些错误。最好明确地设置这些文件的位置。(这么说并不是建议选择不同的位置,只是建议确保在my.cnf文件中明确指定了这些文件的存放地点,这样升级MySQL版本时这些路径就不会改变。)
这里还指定了操作系统必须用mysql用户来运行mysqld进程。需要确保这个账户存在,并且拥有操作数据目录的权限。端口设置为默认的3306,但有时可能需要修改一下。
我们选择InnoDB作为默认的存储引擎,这个值得向大家解释一下。InnoDB在大多数情况下是最好的考择,但并不总是如此。例如,一些第三方的软件,可能假设默认存储引擎是MyISAM,所以创建表时没有指定存储引擎。这可能会导致软件故障,例如,这些应用可能会假定可以创建全文索引默认存储引擎也会在显式创建临时表时用到,可能会引起服务器做一些意料之外的工作。如果希望持久化的表使用InnoDB,但所有临时表使用MyISAM,那应该确保在CREATE TABLE语句中明确指定了存储引擎。
一般情况下,如果决定使用一个存储引擎作为默认引擎,最好显式地进行配置。许多用户认为只使用了某个特定的存储引擎,但后来发现正在用的其实是另一个引擎,就是因为默认配置的是另外一个引擎。
接下来我们将阐述InnoDB的基础配置。InnoDB在大多数情况下如果要运行得很好,配置大小合适的缓冲池(Buffer Pool)和日志文件(Log File)是必须的。默认值都太小了。其他所有的InnoDB设置都是可选的,尽管示例配置中因为可管理性和灵活性的原因启用了innodb_file_per_table。设置InnoDB日志文件的大小和innodb_flush_method是本章后面要讨论的主题,其中innodb_flush_method是类UNIX系统特有的选项。
有一个流行的经验法则说,应该把缓冲池大小设置为服务器内存的约75%〜80%。这是另一个偶然有效的“比率”,但并不总是正确的。有一个更好的办法来设置缓冲池大小,大致如下:
1.从服务器内存总量开始。
2.减去操作系统的内存占用,如果MySQL不是唯一运行在这个服务器上的程序,还要扣掉其他程序可能占用的内存。
3.减去一些MySQL自身需要的内存,例如为每个査询操作分配的一些缓冲。
4.减去足够让操作系统缓存InnoDB日志文件的内存,至少是足够缓存最近经常访问的部分。(此建议适用于标准的MySQL, Percona Server可以配置日志文件用0_DIRECT方式打开,绕过操作系统缓存),留一些内存至少可以缓存二进制日志的最后一部分也是个很好的选择,尤其是如果复制产生了延迟,备库就可能读取主库上旧的二进制日志文件,给主库的内存造成一些压力。
5.减去其他配置的MySQL缓冲和缓存需要的内存,例如MyISAM的键缓存(Key Cache),或者査询缓存(Query Cache)。
6.除以105%,这差不多接近InnoDB管理缓冲池增加的自身管理开销。
7.把结果四舍五入,向下取一个合理的数值。向下舍入不会太影响结果,但是如果分配太多可能就会是件很糟糕的事情。
我们对这里有些内存总量相关的问题有一点感到厌倦——什么是“操作系统的一个位 (Bit)” ?那是变化的,在本章其余部分,我们将对此做一定深度的讨论。你必须了解你的系统,并且估算它需要多少内存才能良好地运转。这是为什么一个适合所有场景的配置文件是不存在的。经验,以及有时一点数学知识将给你提供指导。
下面是一个例子,假设有一个192GB内存的服务器,只运行MySQL并且只使用InnoDB,没有查询缓存(Query Cache),也没有非常多的连接连到服务器。如果日志文件总大小是4GB,可能会像这样处理:“我认为所有内存的5%或者2GB,取较大的那个,应该足够操作系统和MySQL的其他内存需求,为日志文件减去4GB,剩下的都给InnoDB用”。结果差不多是177GB,但是配置得稍微低一点可能是个好主意。比如可以先配置缓存池为168GB。在服务器实际运行中若发现还有不少内存没有分配使用,在出于某些目的有机会重启时,可以再适当调大缓冲池的大小。
如果有大量MyISAM表需要缓存它们的索引,结果自然会有很大不同。在Windows下这也是完全不同的,大多数的MySQL版本在Windows下使用大内存都有问题(虽然在MySQL5.5中有所改进),或者是出于某种原因不使用0_DIRECT也会有不同的结果。
正如你所看到的,从一开始就获得精确的设置并不是关键。从一个比默认值大一点但不 是大得很离谱的安全值开始是比较好的,在服务器运行一段时间后,可以看看服务器真实情况需要使用多少内存。这些东西是很难预测,因为MySQL的内存利用率并不总是可以预测的:它可能依赖很多的因素,例如査询的复杂性和并发性。如果是简单的工作负载,MySQL的内存需求是非常小的——大约256KB的每个连接。但是,使用临时表、排序、存储过程等的复杂査询,可能使用更多的内存。
这就是我们选择一个非常安全的起点的原因。可以看到,即使是保守的InnoDB的缓冲池设置,实际上也是服务器内存的87.5%——超过75%,这就是为什么我们说简单地按比例是不正确的方法的原因。
我们建议,当配置内存缓冲区的时候,宁可谨慎,而不是把它们配置得过大。如果把缓冲池配置得比它可以设的值少了 20%,很可能只会对性能产生小的影响,也许就只影响几个百分点。如果设置得大了 20%,则可能会造成更严重的问题:内存交换、磁盘抖动,甚至内存耗尽和硬件死机。
这份InnoDB配置的例子说明了我们配置服务器的首选途径:了解它内部做了什么,以及参数之间如何相互影响,然后再决定。
示例配置文件中的其他一些设置,大多是不言自明的,其中很多配置都是是与否的判断。在本章的其余部分,我们将探讨其中的几个。可以看到,我们已经启用日志记录、禁用了查询缓存,等等。在这一章的后面,我们还将讨论一些安全性和完整性的设置,它可以使服务器更强健,并对防止数据损坏和其他问题非常有帮助。我们并没有在这里展示这些设置。
这里需要解释的一个选项是open_files_limit。在典型的Linux系统上我们把它设置得尽可能大。现代操作系统中打开文件句柄开销都很小。如果这个参数不够大,将会碰到经典的24号错误,“打开的文件太多(too many open files)”。
跳过其他的直接看到末尾,在配置文件的最后一节,是为了如mysql和mysqladmin之类的客户端程序做的设置,可以简化这些程序连接到服务器的步骤。应该为客户端程序设置那些匹配服务器的配置项。
讨论:时间改变一切
精确地配置MySQL的内存缓冲区随着时间的推移变得不那么重要。当一个强大的服务器只有4GB内存的时候,我们努力地平衡其资源使它可以运行1000个连接。 这通常需要我们为MySQL保留1GB的内存,这是服务器总内存的四分之一,而且会极大地影响我们设置缓冲池的大小。
如今类似的服务器有144GB的内存,但是在大多数应用中我们通常看到的连接数是相同的,每个连接的缓冲区并没有真的改变太多。因此,我们可能会慷慨地为MySQL保留4GB的内存,这只是九牛一毛而已。它不会对我们的缓冲池的大小设置产生太大影响。
3.1 检查MySQL服务器状态变量
有时可以使用SHOW GLOBAL STATUS的输出,作为配置的输入,以更好地通过工作负载来自定义配置。为了达到最佳效果,既要看绝对值,又要看值是如何随时间而改变的,最好为高峰和非髙峰时间的值做几个快照。可以使用以下命令每隔60秒来査看状态变量的增量变化:
$ mysqladmin extended-status -ri60
在解释配置设置的时候,我们经常会提到随着时间的推移各种状态变量的变化。所以通常可以预料到需要分析如刚才那个命令的输出的情况。有一些有用的工具,如Percona Toolkit中的pt-mext或PT-mysql-summary;,可以简洁地显示状态计数器的变化,不用直接看那些SHOW命令的输出。
好吧,前面的内容算是预热,接下来我们将进入一些服务器内核的东西,并将相关的配 置建议穿插在其中。然后再回头来看示例配置文件,就会有足够的背景知识来选择适当的配置选项的值了。
4.配置内存使用
配置MySQL正确地使用内存量对高性能是至关重要的。肯定要根据需求来定制内存使用。可以认为MySQL的内存消耗分为两类:可以控制的内存和不可以控制的内存。无法控制MySQL服务器运行、解析査询,以及其内部管理所消耗的内存,但是为特定目的而使用多少内存则有很多参数可以控制。用好可以控制的内存并不难,但需要对配置的含义非常清楚。
像前面展示的,按下面的步骤来配置内存:
1.确定可以使用的内存上限。
2.确定每个连接MySQL需要使用多少内存,例如排序缓冲和临时表。
3.确定操作系统需要多少内存才够用。包括同一台机器上其他程序使用的内存,如定时任务。
4.把剩下的内存全部给MySQL的缓存,例如InnoDB的缓冲池,这样做很有意义。
将在后面的章节详细说明这些步骤,然后我们对各种MySQL的缓存需求做更细节的分析。
4.1 MySQL可以使用多少内存
在任何给定的操作系统上,MySQL都有允许使用的内存上限。基本出发点是机器上安装了多少物理内存。如果服务器就没装这么多内存,MySQL肯定也不能用这么多内存。
还需要考虑操作系统或架构的限制,如32位操作系统对一个给定的进程可以处理多少内存是有限制的。因为MySQL是单进程多线程的运行模式,它整体可用的内存量也许会受操作系统位数的严格限制——例如,32位Linux内核通常限制任意进程可以使用的内存量在2.5GB〜2.7GB范围内。运行时地址空间溢出是非常危险的,可能导致MySQL崩溃。现在这种情况非常难得一见,但以前这种情况很常见。
有许多其他的操作系统——特殊的参数和古怪的事情必须考虑到,例如不只是每个进程有限制,而且堆栈大小和其他设置也有限制。系统的glibc库也可能限制每次分配的内存大小。例如,若glibc库支持单次分配的最大大小是2GB,那么可能就无法设置innodb_buffer_pool的值大于 2 GB。
即使在64位服务器上,依然有一些限制。例如,许多我们讨论的缓冲区,如键缓存(Key Buffer),在5.0以及更早的MySQL版本上,有4GB的限制,即使在64位服务器上也是如此。在MySQL5.1中,部分限制被取消了,在MySQL手册中记载了每个变量的最大值,有需要可以查阅。
4.2 每个连接需要的内存
MySQL保持一个连接(线程)只需要少量的内存。它还要求一个基本量的内存来执行任何给定査询。你需要为高峰时期执行的大量査询预留好足够的内存。否则,查询执行可能因为缺乏内存而导致执行效率不佳或执行失败。
知道在高峰时期MySQL将消耗多少内存是非常有用的,但一些习惯性用法可能意外地 消耗大量内存,这使得对内存使用量的预测变得比较困难。绑定变量就是一个例子,因为可以一次打开很多绑定变量语句。另一个例子是InnoDB数据字典。
当预测内存峰值消耗时,没必要假设一个最坏情况。例如,配置MySQL允许最多100 个连接,在理论上可能出现100个连接同时在运行很大的查询,但在现实情况中,这可能不会发生。例如,设置myisam_sort_buffer_size为256MB,最差情况下至少需要使用25GB内存,但这种最差情况在实际中几乎是不可能发生的。使用了许多大的临时表或复杂存储过程的査询,通常是导致高内存消耗最可能的原因。
相对于计算最坏情况下的开销,更好的办法是观察服务器在真实的工作压力下使用了多少内存,可以在进程的虚拟内存大小那里看到。在许多类UNIX系统里,可以观察命令中的VIRT列,或者ps命令中的VSZ列的值。下一章有更多关于如何监视内存使用情况的信息。
4.3 为操作系统保留内存
跟査询一样,操作系统也需要保留足够的内存给它工作。如果没有虚拟内存正在交换(Paging)到磁盘,就是表明操作系统内存足够的最佳迹象。
至少应该为操作系统保留1GB〜2GB的内存——如果机器内存更多就再多预留一些。我们建议2GB或总内存的5%作为基准,以较大者为准。为了安全再额外增加一些预留,并且如果机器上还在运行内存密集型任务(如备份),则可以再多增加一些预留。不要为操作系统的缓存增加任何内存,因为它们可能会变得非常大。操作系统通常会利用所有剩下的内存来做文件系统缓存,我们认为,这应该从操作系统自身的需求里分离出来。
4.4 为缓存分配内存
如果服务器只运行MySQL,所有不需要为操作系统以及査询处理保留的内存都可以用作MySQL缓存。
相比其他,MySQL需要为缓存分配更多的内存。它使用缓存来避免磁盘访问,磁盘访问比内存访问数据要慢得多。操作系统可能会缓存一些数据,这对MySQL有些好处(尤其是对MyISAM),但是MySQL自身也需要大量内存。
下面是我们认为对大部分情况来说最重要的缓存:
- InnoDB缓冲池
- InnoDB日志文件和MyISAM数据的操作系统缓存
- MyISAM键缓存
- 査询缓存
- 无法手工配置的缓存,例如二进制日志和表定义文件的操作系统缓存
还有些其他缓存,但是它们通常不会使用太多内存。我们在前面的章节中讨论了査询缓存(Query Cache)的细节,所以接下来的部分我们专注于InnoDB和MyISAM良好工作需要的缓存。
如果只使用单一存储引擎,配置服务器就简单多了。如果只使用MyISAM表,就可以完全关闭InnoDB,而如果只使用InnoDB,就只需要分配最少的资源给MyISAM(MySQL内部系统表采用MyISAM)。但是如果正混合使用各种存储引擎,就很难在它们之间找到恰当的平衡。我们发现最好的办法是先做一个有根据的猜测,然后在运行中观察服务器(再进行调整)。
4.5 InnoDB 缓冲池(Buffer Pool)
如果大部分都是InnoDB表,InnoDB缓冲池或许比其他任何东西更需要内存。InnoDB缓冲池并不仅仅缓存索引:它还会缓存行的数据、自适应哈希索引、插入缓冲(Insert Buffer)、锁,以及其他内部数据结构。InnoDB还使用缓冲池来帮助延迟写入,这样就能合并多个写入操作,然后一起顺序地写回。总之,InnoDB严重依赖缓冲池,你必须确认为它分配了足够的内存,通常就像这一章前面展示的那样处理。可以使用通过SHOW命令得到的变量或者例如innotop这样的工具监控InnoDB缓冲池的内存利用情况。
如果数据量不大,并且不会快速增长,就没必要为缓冲池分配过多的内存。把缓冲池配置得比需要缓存的表和索引还要大很多实际上没有什么意义。当然,对一个迅速增长的数据库做超前的规划没有错,但有时我们也会看到一个巨大的缓冲池只缓存一点点数据,这就没有必要了。
很大的缓冲池也会带来一些挑战,例如,预热和关闭都会花费很长的时间。如果有很多脏页在缓冲池里,InnoDB关闭时可能会花费较长的时间,因为在关闭之前需要把脏页写回数据文件。也可以强制快速关闭,但是重启时就必须多做更多的恢复工作,也就是说无法同时加速关闭和重启两个动作。如果事先知道什么时候需要关闭InnoDB,可以在运行时修改innodb_max_dirty_pages_pct变量,将值改小,等待刷新线程清理缓冲池,然后在脏页数量较少时关闭。可以监控the Innodb_buffer_pool_pages_dirty状态变量或者使用来监控SHOW INNODB STATUS来观察脏页的刷新量。
更小的innodb_max_dirty_pages_pct变量值并不保证InnoDB将在缓冲池中保持更少的脏页。它只是控制InnoDB是否可以“偷懒(Lazy)”的阈值。InnoDB默认通过一个后台线程来刷新脏页,并且会合并写入,更髙效地顺序写出到磁盘。这个行为之所以被称为“偷懒(Lazy)”,是因为它使得InnoDB延迟了缓冲池中刷写脏页的操作,直到一些其他数据必须使用空间时才刷写。当脏页的百分比超过了这个阈值,InnoDB将快速地刷写脏页,尝试让脏页的数量更低。当事务日志没有足够的空间剩余时,InnoDB 也将进入“激烈刷写(Furious Flushing)”模式,这就是大日志可以提升性能的一个原因。
当有一个很大的缓冲池,重启后服务器也许需要花很长的时间(几个小时甚至几天)来预热缓冲池,尤其是磁盘很慢的时候。在这种情况下,可以利用Percona Server的功能来重新载入缓冲池的页,从而节省时间。这可以让预热时间减少到几分钟。MySQL5.6也提供了一个类似的功能。这个功能对复制尤其有好处,因为单线程复制导致备库需要额外的预热时间。
如果不能使用Percona Server的快速预热功能,也可以在重启后立刻进行全表扫描或者索引扫描,把索引载入缓冲池。这是比较粗暴的方式,但是有时候比什么都不做还是要好。可以使用init_file设置来实现这个功能。把SQL放到一个文件里,然后当MySQL启动的时候来执行。文件名必须在init_file选项中指定,文件中可以包含多条SQL命令,每一条单独一行(不允许使用注释)。
4.6 MyISAM键缓存(Key Caches)
MyISAM的键缓存也被称为键缓冲,默认只有一个键缓存,但也可以创建多个。不像InnoDB和其他一些存储引擎,MyISAM自身只缓存索引,不缓存数据(依赖操作系统缓存数据)。如果大部分是MyISAM表,就应该为键缓存分配比较多的内存。
最重要的配置项是key_buffer_size。任何没有分配给它的内存都可以被操作系统缓 存利用。MySQL5.0有一个规定的有效上限是4GB,不管系统是什么架构。MySQL5.1允许更大的值。可以査看正在使用的MySQL版本的官方手册来了解这个限制。
在决定键缓存需要分配多少内存之前,先去了解MyISAM索引实际上占用多少磁盘空间是很有帮助的。肯定不需要把键缓冲设置得比需要缓存的索引数据还大。査询INF0RMATI0N_SCHEMA表的INDEX_LENGTH字段,把它们的值相加,就可以得到索引存储占用的空间:
SELECT SUM(INDEX_LENGTH) FROM INFORMATION_SCHEMA.TABLES WHERE ENGINE='MYISAM';
如果是类UNIX系统,也可以使用下面的命令:
$ du -sch `find /path/to/mysql/data/directory/ -name "*.MYI"`
应该把键缓存设置得多大?不要超过索引的总大小,或者不超过为操作系统缓存保留总 内存的25%〜50%,以更小的为准。
默认情况下,MyISAM将所有索引都缓存在默认键缓存中,但也可以创建多个命名的键缓冲。这样就可以同时缓存超过4GB的内存。如果要创建名为key_buffer_1和key_buffer_2的键缓冲,每个大小为1GB,则可以在配置文件中添加如下配置项:
key_buffer_1.key_buffer_size = 1G
key_buffer_2.key_buffer_size = 1G
现在有了三个键缓冲:两个由这两行配置明确定义,还有一个是默认键缓冲。可以使用CACHE INDEX命令来将表映射到对应的缓冲区。使用下面的语句,让MySQL使用key_buffer_1缓冲区来缓存t1和t2表的索引:
mysql> CACHE INDEX t1, t2 IN key_buffer_1;
现在当MySQL从这些表的索引读取块时,将会在指定的缓冲区内缓存这些块。也可以把表的索引预载入到缓存中,通过init_file设置或者LOAD INDEX命令:
mysql> LOAD INDEX INTO CACHE t1, t2;
任何没明确指定映射到哪个键缓冲区的索引,在MySQL第一次需要访问.MYI文件的时候,都会被分配到默认缓冲区。 .
可以通过SHOW STATUS和SHOW VARIABLES命令的信息来监控键缓冲的使用情况。下面的公式可以计算缓冲区的使用率:
100 - ( (Key_blocks_unused * key_cache_block_size) * 100 / key_buffer_size )
如果服务器运行了很长一段时间后,还是没有使用完所有的键缓冲,就可以把缓冲区调小一点。
键缓冲命中率有什么意义?正如我们之前解释的那样,这个数字没什么用。例如,99% 和99.9%之间看起来差别很小,但实际上代表了10倍的差距。缓存命中率也是和应用相关的:有些应用可以在95%的命中率下工作良好,但是也有些应用可能是I/O密集型的,必须在99.9%的命中率下工作。甚至有可能在恰当大小的缓存设置下获得99.99%的命中率。
从经验上来说,每秒缓存未命中的次数要更有用。假定有一个独立的磁盘,每秒可以做100个随机读。每秒5次缓存未命中可能不会导致I/O繁忙,但是每秒80次缓存未命中则可能出现问题。可以使用下面的公式来计算这个值:
Key_reads / Uptime
通过间隔10〜100秒来计算这段时间内缓存未命中次数的增量值,可以获得当前性能的情况。下面的命令可以每10秒钟获取一次状态值的变化量:
$ mysqladmin extended-status -r -i 10 | grep Key_reads
记住,MyISAM使用操作系统缓存来缓存数据文件,通常数据文件比索引要大。因此,把更多的内存保留给操作系统缓存而不是键缓存是有意义的。即使你有足够的内存来缓存所有索引,并且键缓存命中率很低,当MySQL尝试读取数据文件时(不是索引文件),在操作系统层还是可能发生缓存未命中,这对MySQL完全透明,MySQL并不能感知到。因此,这种情况下可能会有大量数据文件缓存未命中,这和索引的键缓存未命中率是完全不相关的。
最后,即使没有任何MyISAM表,依然需要将key_buffer_size设置为较小的值,例如 32M。MySQL服务器有时会在内部使用MyISAM表,例如GROUP BY语句可能会使用MyISAM做临时表。
MySQL键缓存块大小(Key Block Size)
块大小也是很重要的(尤其是写密集型负载),因为它影响了MyISAM、操作系统缓存,以及文件系统之间的交互。如果缓存块太小了,可能会碰到写时读取(read-arouond write),就是操作系统在执行写操作之前必须先从磁盘上读取一些数据。下面说明一下这种情况是怎么发生的,假设操作系统的页大小是4KB (在x86架构上通常都是这样),并且索引块大小是1KB :
1.MyISAM请求从磁盘上读取1KB的块。
2.操作系统从磁盘上读取4KB的数据并缓存,然后发送需要的1KB数据给MyISAM。
3.操作系统丢弃缓存数据以给其他数据腾出缓存。
4.MyISAM修改1KB的索引块,然后请求操作系统把它写回磁盘。
5.操作系统从磁盘读取同一个4KB的数据,写入操作系统缓存,修改MyISAM改动的这1KB数据,然后把整个4KB的块写回磁盘。
在第5步中,当MyISAM请求操作系统去写4KB页的部分内容时,就发生了写时读取 (read-around write)。如果MyISAM的块大小跟操作系统的相匹配,在第5步的磁盘读就可以避免。
很遗憾,MySQL5.0以及更早的版本没有办法配置索引块大小。但是,在MySQL5.1以及更新版本中,可以设置MyISAM的索引块大小跟操作系统一样,以避免写时读取。myisam_block_size变量控制着索引块大小。也可以指定每个索引的块大小,在CREATE TABLE或者CREATE INDEX语句中使用KEY_BL0CK_SIZE选项即可,但是因为同一个表的所有索引都保存在同一个文件中,因此该表所有索引的块大小都需要大于或者等于操作系统的块大小,才能避免由于边界对齐导致的写时读取。(例如,若同一个表的两个索引,一个块大小是1KB,另一个是4KB。那么4KB的索引块边界很可能和操作系统的页边界是不对齐的,这样还是会发生写时读取。)
4.7 线程缓存
线程缓存保存那些当前没有与连接关联但是准备为后面新的连接服务的线程。当一个新的连接创建时,如果缓存中有线程存在,MySQL从缓存中删除一个线程,并且把它分配给这个新的连接。当连接关闭时,如果线程缓存还有空间的话,MySQL又会把线程放回缓存。如果没有空间的话,MySQL会销毁这个线程。只要MySQL在缓存里还有空闲的线程,它就可以迅速地响应连接请求,因为这样就不用为每个连接创建新的线程。
thread_cache_size变量指定了MySQL可以保持在缓存中的线程数。一般不需要配置这个值,除非服务器会有很多连接请求。要检査线程缓存是否足够大,可以査看Threads_created状态变量。如果我们观察到很少有每秒创建的新线程数少于10个的时候,通常应该尝试保持线程缓存足够大,但是实际上经常也可能看到每秒少于1个新线程的情况。
一个好的办法是观察Threads_connected变量并且尝试设置thread_cache_size足够大以便能处理业务压力正常的波动。例如,若Threads_connected通常保持在100〜120,则可以设置缓存大小为20。如果它保持在500〜700, 200的线程缓存应该足够大了。可以这样认为:在700个连接的时候,可能没有线程在缓存中;在500个连接的时候,有200个缓存的线程准备为负载再次增加到700个连接时使用。
把线程缓存设置得非常大在大部分时候是没有必要的,但是设置得很小也不能节省太多内存,所以也没什么好处。每个在线程缓存中的线程或者休眠状态的线程,通常使用256KB左右的内存。相对于正在处理査询的线程来说,这个内存不算很大。通常应该保证线程缓存足够大,以避免Threads_created频繁增长。如果这个数字很大(例如,几千个线程),可能需要把thread_cache_size设置得稍微小一些,因为一些操作系统不能很好地处理庞大的线程数,即使其中大部分是休眠的。
4.8 表缓存(Table Cache)
表缓存和线程缓存的概念是相似的,但存储的对象代表的是表。每个在缓存中的对象包含相关表.frm文件的解析结果,加上一些其他数据。准确地说,在对象里的其他数据的内容依赖于表的存储引擎。例如,对MyISAM,是表的数据和索引的文件描述符。对于Merge表则可能是多个文件描述符,因为Merge表可以有很多的底层表。
表缓存可以重用资源。举个实际的例子,当一个査询请求访问一张MyISAM表,MySQL也许可以从缓存的对象中获取到文件描述符。尽管这样做可以避免打开一个文件描述符的开销,但这个开销其实并不大。打开和关闭文件描述符在本地存储是很快的,服务器可以轻松地完成每秒100万次的操作(尽管这跟网络存储不同)。对MyISAM表来说,表缓存的真正好处是,可以让服务器避免修改MyISAM文件头来标记表“正在使用中”。(“打开的表(Opened Table)”的概念,可能有点混乱。当不同的查询同时访问一张表,或者是一个单独的查询引用同一张表超过一次,比如子查询或者自关联,MySQL都会对一张表作为打开状态多次计数。MyISAM表的索引文件包含一个计数器,MyISAM表打开时递增,关闭时递减。这使得对于MyISAM表可以看到是不是关闭干净了:如果首次打开一个表,计数器不为零,说明表没有关闭干净。)
表缓存的设计是服务器和存储引擎之间分离不彻底的产物,属于历史问题。表缓存对InnoDB重要性就小多了,因为InnoDB不依赖它来做那么多的事(例如持有文件描述符,InnoDB有自己的表缓存版本)。尽管如此,InnoDB也能从缓存解析的.frm文件中获益。
在MySQL5.1版本中,表缓存分离成两部分:一个是打开表的缓存,一个是表定义缓存 (通过table_open_cache和table_definition_cache变量来配置)。其结果是,表定义(解析.frm文件的结果)从其他资源中分离出来了,例如表描述符。打开的表依然是每个线程、每个表用的,但是表定义是全局的,可以被所有连接有效地共享。通常可以把table_definition_cache设置得足够高,以缓存所有的表定义。除非有上万张表,否则这可能是最简单的方法。
如果Opened_tables状态变量很大或者在增长,可能是因为表缓存不够大,那么可以人为增加table_cache系统变量(或者是MySQL5.1中table_open_cache)。然而,当创建和删除临时表时,要注意这个计数器的增长,如果经常需要创建和删除临时表,那么该计数器就会不停地增长。
把表缓存设置得非常大的缺点是,当服务器有很多MyISAM表时,可能会导致关机时间较长,因为关机前索引块必须完成刷新,表都必须标记为不再打开。同样的原因,也可能使FLUSH TABLES WITH READ LOCK操作花费很长一段时间。更为严重的是,检査表缓存算法不是很有效,稍后会更详细地说明。
如果遇到MySQL无法打开更多文件的错误(可以使用perror工具来检査错误号代表的含义),那么可能需要增加MySQL允许打开文件的数量。这可以通过在my.cnf文件中设置open_files_limit服务器变量来实现。
线程和表缓存实际上用的内存并不多,相反却可以有效节约资源。虽然创建一个新线程或者打开一个新的表,相对于其他MySQL操作来说代价并不算高,但它们的开销是会累加的。所以缓存线程和表有时可以提升效率。
4.9 InnoDB 数据字典(Data Dictionary)
InnoDB有自己的表缓存,可以称为表定义缓存或者数据字典,在目前的MySQL版本中还不能对它进行配置。当InnoDB打开一张表,就增加了一个对应的对象到数据字典。每张表可能占用4KB或者更多的内存(尽管在MySQL 5.1中对空间的需求小了很多)。当表关闭的时候也不会从数据字典中移除它们。
因此,随着时间的推移,服务器可能出现内存泄露,导致数据字典中的元素不断地增长。但这不是真的内存泄露,只是没有对数据字典实现任何一种缓存过期策略。通常只有当有很多(数千或数万)张大表时才是个问题。如果这个问题有影响,可以使用Percona Server,有一个选项可以控制数据字典的大小,它会从数据字典中移除没有使用的表。MySQL5.6版本中也有个类似的功能。
另一个性能问题是第一次打开表时会计算统计信息,这需要很多I/O操作,所以代价很高。相比MyISAM,InnoDB没有将统计信息持久化,而是在每次打开表时重新计算,在打开之后,每隔一段过期时间或者遇到触发事件(改变表的内容或者査询INFORMATION_SCHEMA表,等等),也会重新计算统计信息。如果有很多表,服务器可能会花费数个小时来启动并完全预热,在这个时候服务器可能花费更多的时间在等待I/O操作,而不是做其他事。可以在Percona Server(在MySQL5.6中也可以,但是叫做innodb_analyze_is_persistent)中打开 innodb_use_sys_stats_table选项来持久化存储统计信息到磁盘,以解决这个问题。
即使在启动之后,InnoDB统计操作还可能对服务器和一些特定的査询产生冲击。可以关闭innodb_stats_on_metadata选项来避免耗时的表统计信息刷新。当例如IDE这样的工具执行INFORMATION_SCHEMA表的査询时,关闭这个选项后的表现是很不一样的(当然是快了不少)。
如果设置了InnoDB的innodb_file_per_table选项(后面会描述),InnoDB任意时刻可以保持打开.ibd文件的数量也是有其限制的。这由InnoDB存储引擎负责,而不是MySQL服务器管理,并且由innodb_open_files来控制。InnoDB打开文件和MyISAM的方式不一样,MyISAM用表缓存来持有打开表的文件描述符,而InnoDB在打开表和打开文件之间没有直接的关系。InnoDB为每个.ibd文件使用单个、全局的文件描述符。如果可以,最好把innodb_open_files的值设置得足够大以使服务器可以保持所有的.ibd文件同时打开。
5.配置MySQL的I/O行为
有一些配置项影响着MySQL怎样同步数据到磁盘以及如何做恢复操作。这些操作对性能的影响非常大,因为都涉及到昂贵的I/O操作。它们也表现了性能和数据安全之间的权衡。通常,保证数据立刻并且一致地写到磁盘是很昂贵的。如果能够冒一点磁盘写可能没有真正持久化到磁盘的风险,就可以增加并发性和减少I/O等待,但是必须决定可以容忍多大的风险。
5.1 InnoDB I/O 配置
InnoDB不仅允许控制怎么恢复,还允许控制怎么打开和刷新数据(文件),这会对恢复 和整体性能产生巨大的影响。尽管可以影响它的行为,InnoDB的恢复流程实际上是自动的,并且经常在InnoDB启动时运行。撇开恢复并假设InnoDB没有崩溃或者出错,InnoDB依然有很多需要配置的地方。它有一系列复杂的缓存和文件设计可以提升性能,以及保证ACID特性,并且每一部分都是可配置的,图8-1阐述了这些文件和缓存。
对于常见的应用,最重要的一小部分内容是InnoDB日志文件大小、InnoDB怎样刷新它 的日志缓冲,以及InnoDB怎样执行I/O。
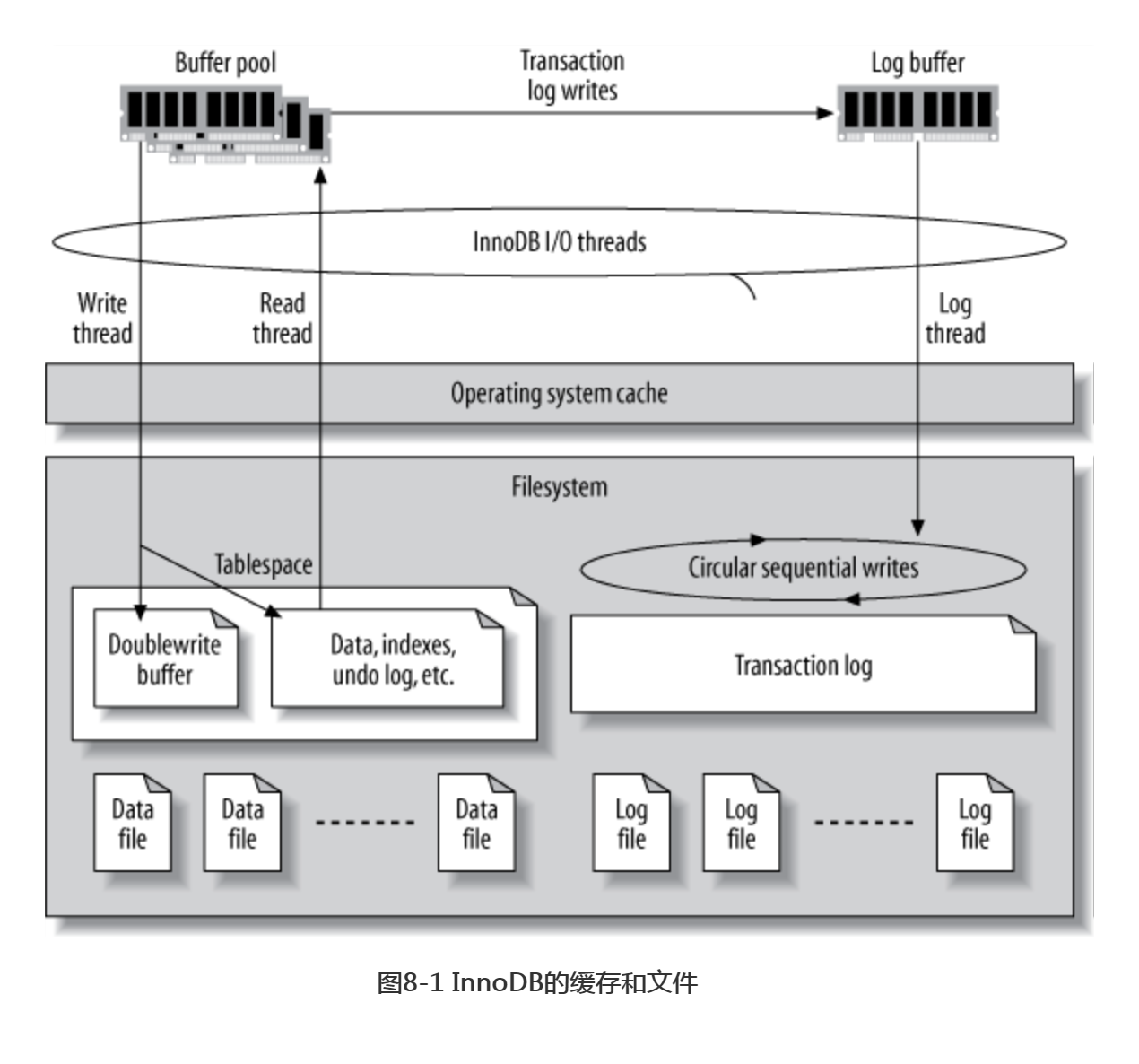
InnoDB事务日志
InnoDB使用日志来减少提交事务时的开销。因为日志中已经记录了事务,就无须在每个事务提交时把缓冲池的脏块刷新(flush)到磁盘中。事务修改的数据和索引通常会映射到表空间的随机位置,所以刷新这些变更到磁盘需要很多随机I/O。InnoDB假设使用的是常规磁盘(机械磁盘),随机I/O比顺序I/O要昂贵得多,因为一个I/O请求需要时间把磁头移到正确的位置,然后等待磁盘上读出需要的部分,再转到开始位置。
InnoDB用日志把随机I/O变成顺序I/O。一旦日志安全写到磁盘,事务就持久化了,即使变更还没写到数据文件。如果一些糟糕的事情发生了(例如断电了),InnoDB可以重放日志并且恢复已经提交的事务。
当然,InnoDB最后还是必须把变更写到数据文件,因为日志有固定的大小。InnoDB的日志是环形方式写的:当写到日志的尾部,会重新跳转到开头继续写,但不会覆盖还没应用到数据文件的日志记录,因为这样做会清掉已提交事务的唯一持久化记录。
InnoDB使用一个后台线程智能地刷新这些变更到数据文件。这个线程可以批量组合写入,使得数据写入更顺序,以提高效率。实际上,事务日志把数据文件的随机I/O转换为几乎顺序的日志文件和数据文件I/O。把刷新操作转移到后台使査询可以更快完成,并且缓和査询高峰时I/O系统的压力。
整体的日志文件大小受控于innodb_log_file_size和innodb_log_files_in_group两个参数,这对写性能非常重要。日志文件的总大小是每个文件的大小之和。默认情况下,只有两个5MB的文件,总共10MB。对髙性能工作来说这太小了。至少需要几百MB,或者甚至上GB的日志文件。
InnoDB使用多个文件作为一组循环日志。通常不需要修改默认的日志数量,只修改每个日志文件的大小即可。要修改日志文件大小,需要完全关闭MySQL,将旧的日志文件移到其他地方保存,重新配置参数,然后重启。一定要确保MySQL干净地关闭了,或者还有日志文件可以保证需要应用到数据文件的事务记录,否则数据库就无法恢复了!当重启服务器的时候,査看MySQL的错误日志。在重启成功之后,才可以删除旧的日志文件。
日志文件大小和日志缓存。要确定理想的日志文件大小,必须权衡正常数据变更的开销 和崩溃恢复需要的时间。如果日志太小,InnoDB将必须做更多的检査点,导致更多的日志写。在极个别情况下,写语句可能被拖累,在日志没有空间继续写入前,必须等待变更被应用到数据文件。另一方面,如果日志太大了,在崩溃恢复时InnoDB可能不得不做大量的工作。这可能极大地增加恢复时间,尽管这个处理在新的MySQL版本中已经改善很多。
数据大小和访问模式也将影响恢复时间。假设有一个1TB的数据和16GB的缓冲池,并且全部日志大小是128MB。如果缓冲池里有很多脏页(例如,页被修改了还没被刷写回数据文件),并且它们均匀地分布在1TB数据中,崩溃后恢复将需要相当长一段时间。InnoDB必须从头到尾扫描日志,仔细检査数据文件,如果需要还要应用变更到数据文件。这是很庞大的读写操作!另一方面,如果变更是局部性的——就是说,如果只有几百MB数据被频繁地变更—恢复可能就很快,即使数据和日志文件很大。恢复时间也依赖于普通修改操作的大小,这跟数据行的平均长度有关系。较短的行使得更多的修改可以放在同样的日志中,所以InnoDB可能必须在恢复时重放更多修改操作。
当InnoDB变更任何数据时,会写一条变更记录到内存日志缓冲区。在缓冲满的时候、事务提交的时候,或者每一秒钟,InnoDB都会刷写缓冲区的内容到磁盘日志文件——无论上述三个条件哪个先达到。如果有大事务,增加日志缓冲区(默认1MB)大小可以帮助减少I/O。变量innodb_log_buffer_size可以控制日志缓冲区的大小。
通常不需要把日志缓冲区设置得非常大。推荐的范围是1MB〜8MB,一般来说足够了,除非要写很多相当大的BLOB记录。相对于InnoDB的普通数据,日志条目是非常紧凑的。它们不是基于页的,所以不会浪费空间来一次存储整个页。InnoDB也使得日志条目尽可能地短。有时甚至会保存为函数号和C函数的参数!
较大的日志缓冲区在某些情况下也是有好处的:可以减少缓冲区中空间分配的争用。当 配置一台有大内存的服务器时,有时简单地分配32MB〜128MB的日志缓冲,因为花费这么点相对(整机)而言比较小的内存并没有什么不好,还可以帮助避免压力瓶颈。如果有问题,瓶颈一般会表现为日志缓冲Mutex的竞争。
可以通过检査SHOW INNODB STATUS的输出中LOG部分来监控InnoDB的日志和日志缓冲区的I/O性能,通过观察Innodb_os_log_written状态变量来査看InnoDB对日志文件写出了多少数据。一个好用的经验法则是,査看10〜100秒间隔的数字,然后记录峰值。可以用这个来判断日志缓冲是否设置得正好。例如,若看到峰值是每秒写100KB数据到日志,那么1MB的日志缓冲可能足够了。也可以使用这个衡量标准来决定日志文件设置多大会比较好。如果峰值是100KB/s,那么256M的日志文件足够存储至少2560秒的日志记录。这看起来足够了。作为一个经验法则,日志文件的全部大小,应该足够容纳服务器一个小时的活动内容。
InnoDB怎样刷新日志缓冲。当InnoDB把日志缓冲刷新到磁盘日志文件时,先会使用一 个Mutex锁住缓冲区,刷新到所需要的位置,然后移动剩下的条目到缓冲区的前面。当Mutex释放时,可能有超过一个事务已经准备好刷新其日志记录。InnoDB有一个Group Commit功能,可以在一个I/O操作内提交多个事务,但是在MySQL5.0中当打开二进制日志时这个功能就不能用了。
日志缓冲必须被刷新到持久化存储,以确保提交的事务完全被持久化了。如果和持久相比更在乎性能,可以修改innodb_flush_log_at_trx_commit变量来控制日志缓冲刷新的频繁程度。可能的设置如下:
0
把日志缓冲写到日志文件,并且每秒钟刷新一次,但是事务提交时不做任何事。
1
将日志缓冲写到日志文件,并且每次事务提交都刷新到持久化存储。这是默认的(并且是最安全的)设置,该设置能保证不会丢失任何已经提交的事务,除非磁盘或者操作系统是“伪”刷新。
2
每次提交时把日志缓冲写到日志文件,但是并不刷新。InnoDB每秒钟做一次刷新。0与2最重要的不同是(也是为什么2是更合适的设置),如果MySQL进程“挂了”,2不会丢失任何事务。如果整个服务器“挂了”或者断电了,则还是可能会丢失一些事务。
了解清楚“把日志缓冲写到日志文件”和“把日志刷新到持久化存储”之间的不同是很 重要的。在大部分操作系统中,把缓冲写到日志只是简单地把数据从InnoDB的内存缓冲转移到了操作系统的缓存,也是在内存里,并没有真的把数据写到了持久化存储。
因此,如果MySQL崩溃了或者电源断电了,设置0和2通常会导致最多一秒的数据丢失,因为数据可能只存在于操作系统的缓存。我们说“通常”,因为不论如何InnoDB会每秒尝试刷新日志文件到磁盘,但是在一些场景下也可能丢失超过1秒的事务,例如当刷新被推迟了。
与此相反,把日志刷新到持久化存储意味着InnoDB请求操作系统把数据刷出缓存,并且确认写到磁盘了。这是一个阻塞I/O的调用,直到数据被完全写回才会完成。因为写数据到磁盘比较慢,当innodb_flush_log_at_trx_commit被设置为1时,可能明显地降低InnoDB每秒可以提交的事务数。高速驱动器可能每秒只能执行一两百个磁盘事务,受限于磁盘旋转速度和寻道时间。
有时硬盘控制器或者操作系统假装做了刷新,其实只是把数据放到了另一个缓存,例如磁盘自己的缓存。这更快但是很危险,因为如果驱动器断电,数据依然可能丢失。这甚至比设置innodb_flush_log_at_trx_commit为不为1的值更糟糕,因为这可能导致数据损坏,不仅仅是丢失事务。
设置innodb_flush_log_at_trx_commit为不为1的值可能导致丢失事务。然而,如果不在意持久性(ACID中的D),那么设置为其他的值也是有用的。也许你只是想拥有InnoDB的其他一些功能,例如聚簇索引、防止数据损坏,以及行锁。但仅仅因为性能原因用InnoDB替换MyISAM的情况也并不少见。
高性能事务处理需要的最佳配置是把innodb_flush_log_at_trx_commit设置为1且把日志文件放到一个有电池保护的写缓存的RAID卷中。这兼顾了安全和速度。事实上,我们敢说任何希望能扛过高负荷工作负载的产品数据库服务器,都需要有这种类型的硬件。
Percona Server扩展了innodb_flush_log_at_trx_commit变量,使得它成为一个会话级变量,而不是一个全局变量。这允许有不同的性能和持久化要求的应用,可以使用同样的数据库,同时又避免了标准MySQL提供的一刀切的解决方案。
InnoDB怎样打开和刷新日志以及数据文件
使用innodb_flush_method选项可以配置InnoDB如何跟文件系统相互作用。从名字来看,会以为只能影响InnoDB怎么写数据,实际上还影响了InnoDB怎么读数据。Windows和非Windows的操作系统对这个选项的值是互斥的:async_unbuffered、unbuffered和normal只能在Windows下使用,并且Windows下不能使用其他的值。在Windows下默认值是unbuffered,其他操作系统都是fdatasync。(如果SHOW GLOBAL VARIABLES显示这个变量为空,意味着它被设置为默认值了。)
提示:改变InnoDB执行I/O操作的方式可以显著地影响性能,所以请确认你明白了在做什么后再去做改动!
这是个有点难以理解的选项,因为它既影响日志文件,也影响数据文件,而且有时候对不同类型的文件的处理也不一样。如果有一个选项来配置日志,另一个选项来配置数据文件,这样最好了,但实际上它们混合在同一个配置项中。
下面是一些可能的值:
fdatasync
这在非Windows系统上是默认值:InnoDB用fsync()来刷新数据和日志文件。InnoDB通常用fsync()代替fdatasync(),即使这个值似乎表达的是相反的意思。fdatasync()跟fsync()相似,但是只刷新文件的数据,而不包括元数据(最后修改时间,等等)。因此,fsync()会导致更多的I/O。然而InnoDB的开发者都很保守,他们发现某些场景下fdatasync()会导致数据损坏。InnoDB决定了哪些方法可以更安全地使用,有一些是编译时设置的,也有一些是运行时设置的。它使用尽可能最快的安全方法。
使用fsync()的缺点是操作系统至少会在自己的缓存中缓冲一些数据。理论上,这种双重缓冲是浪费的,因为InnoDB管理自己的缓冲比操作系统能做的更加智能。然而,最后的影响跟操作系统和文件系统非常相关。如果能让文件系统做更智能的I/O调度和批量操作,双重缓冲可能并不是坏事。有的文件系统和操作系统可以积累写操作后合并执行,通过对I/O重新排序来提升效率,或者并发写入多个设备。它们也可能做预读优化,例如,若连续请求了几个顺序的块,它会通知硬盘预读下一个块。
有时这些优化有帮助,有时没有。如果你好奇你的系统中的fsync()会做哪些具体的事,可以阅读系统的帮助手册,看下fsync(2)。
innodb_file_per_table选项会导致每个文件独立地做fsync(),这意味着写多个表不能合并到一个I/O操作。这可能导致InnoDB执行更多的fsync()操作。
0_DIRECT
InnoDB对数据文件使用0_DIRECT标记或directio()函数,这依赖于操作系统。这个设置并不影响日志文件并且不是在所有的类UNIX系统上都有效。但至少GNU/Linux、FreeBSD,以及Solaris(5.0以后的新版本)是支持的。不像0_DSYNC标记,它同时会影响读和写。
这个设置依然使用fsync()来刷新文件到磁盘,但是会通知操作系统不要缓存数据,也不要用预读。这个选项完全关闭了操作系统缓存,并且使所有的读和写都直接通过存储设备,避免了双重缓冲。
在大部分系统上,这个实现用fcntl()调用来设置文件描述符的0_DIRECT标记,所以可以阅读fcntl(2)的手册页来了解系统上这个函数的细节。在Solaris系统,这个选项用directio()。
如果RAID卡支持预读,这个设置不会关闭RAID卡的预读。这个设置只能关闭操作系统和文件系统的预读。
如果使用0_DIRECT选项,通常需要带有写缓存的RAID卡,并且设置为Write-Back策略,因为这是典型的唯一能保持好性能的方法。当InnoDB和实际存储设备之间没有缓冲时使用0_DIRECT,例如当RAID卡没有写缓存时,可能导致严重的性能下降。现在有了多个写线程,这个问题稍微小一点(并且MySQL5.5提供了原生异步I/0),但是通常还是有问题。
这个选项可能导致服务器预热时间变长,特别是操作系统的缓存很大的时候。也可能导致小容量的缓冲池(例如,默认大小的缓冲池)比缓冲I/O(Buffered IO)方式操作要慢的多。这是因为操作系统不会通过保持更多数据在自己的缓存中来“帮助”(提升性能)。如果需要的数据不在缓冲池,InnoDB将不得不直接从磁盘读取。
这个选项不会对innodb_file_per_table产生任何额外的损失。相反,如果不用innodb_file_per_table,当使用0_DIRECT时,可能由于一些顺序I/O而遭受性能损失。这种情况的发生是因为一些文件系统(包括Linux所有的文件ext系统)每个inode有一个Mutex。当在这些文件系统上使用0_DIRECT时,确实需要打开innodb_file_per_table。
ALL_0_DIRECT
这个选项在Percona Server和MariaDB中可用。它使得服务器在打开日志文件时,也能使用标准MySQL中打开数据文件的方式(0_DIRECT)。
0_DSYNC
这个选项使日志文件调用open()函数时设置0_SYNC标记。它使得所有的写同步——换个说法,只有数据写到磁盘后写操作才返回。这个选项不影响数据文件。
0_SYNC标记和0_DIRECT标记的不同之处在于0_SYNC没有禁用操作系统层的缓存。因此,它没有避免双重缓冲,并且它没有使写操作直接操作到磁盘。用了0_SYNC标记,在缓存中写数据,然后发送到磁盘。
使用0_SYNC标记做同步写操作,听起来可能跟fsync()做的事情非常相似,但是它们两个的实现无论在操作系统层还是在硬件层都非常不同。用了0_SYNC标记后,操作系统可能把“使用同步I/O”标记下传给硬件层,告诉设备不要使用缓存。另一方面,fsync()告诉操作系统把修改过的缓冲数据刷写到设备上,如果设备支持,紧接着会传递一个指令给设备刷新它自己的缓存,所以,毫无疑问,数据肯定记录在了物理媒介上。另一个不同是,用了0_SYNC的话,每个write()或pwrite()操作都会在函数完成之前把数据同步到磁盘,完成前函数调用是阻塞的。相对来看,不用0_SYNC标记的写入调用fsync()允许写操作积累在缓存(使得每个写更快),然后一次性刷新所有的数据。
再一次吐槽下这个名称,这个选项设置0_SYNC标记,不是0_DSYNC标记,因为InnoDB开发者发现了0_DSYNC的Bug。0_SYNC和0_DSYNC类似于fysnc()和fdatasync():0_SYNC同时同步数据和元数据,但是0_DSYNC只同步数据。
async_unbuffered
这是Windows下的默认值。这个选项让InnoDB对大部分写使用没有缓冲的I/O;例外是当innodb_flush_log_at_trx_commit设置为2的时候,对日志文件使用缓冲I/O。
这个选项使得InnoDB在Windows2000、XP,以及更新版本中对数据读写都使用操作系统的原生异步(重叠的)I/O。在更老的Windows版本中,InnoDB使用自己用多线程模拟的异步I/O。
unbuffered
只对Windows有效。这个选项与async_unbuffered类似,但是不使用原生异步I/O。
normal
只对Windows有效。这个选项让InnoDB不要使用原生异步I/O或者无缓冲I/O。
Nosync和littlesync
只为开发使用。这两个选项在文档中没有并且对生产环境来说不安全,不应该使用这个。
如果这些看起来像是一堆不带建议的说明,那么下面是一些建议:如果使用类UNIX操 作系统并且RAID控制器带有电池保护的写缓存,我们建议使用0_DIRECT。如果不是这样,默认值或者0_DIRECT都可能是最好的选择,具体要看应用类型。
InnoDB表空间
InnoDB把数据保存在表空间内,本质上是一个由一个或多个磁盘文件组成的虚拟文件系统。InnoDB用表空间实现很多功能,并不只是存储表和索引。它还保存了回滚日志(旧版本行)、插入缓冲(Insert Buffer)、双写缓冲(Doublewrite Buffer,后面的章节里就会描述),以及其他内部数据结构。
配置表空间。通过innodb_data_file_path配置项可以定制表空间文件。这些文件都放在innodb_data_home_dir指定的目录下。这是一个例子:
innodb_data_home_dir = /var/lib/mysql/
innodb_data_file_path = ibdata1:1G;ibdata2:1G;ibdata3:1G
这里在三个文件中创建了 3GB的表空间。有时人们并不清楚可以使用多个文件分散驱动器的负载,像这样:
innodb_data_file_path = /disk1/ibdata1:1G;/disk2/ibdata2:1G;...
在这个例子中,表空间文件确实放在代表不同驱动器的不同目录中,InnoDB把这些文件首尾相连组合起来。因此,通常这种方式并不能获得太多收益。InnoDB先填满第一个文件,当第一个文件满了再用第二个,如此循环;负载并没有真的按照希望的髙性能方式分布。用RAID控制器是分布负载更聪明的方式。
为了允许表空间在超过了分配的空间时还能增长,可以像这样配置最后一个文件自动扩展:
...ibdata3:1G:autoextend
默认的行为是创建单个10MB的自动扩展文件。如果让文件可以自动扩展,那么最好给表空间大小设置一个上限,别让它扩展得太大,因为一旦扩展了,就不能收缩回来。例如,下面的例子限制了自动扩展文件最多到2GB:
...ibdata3:1G:autoextend:max:2G
管理一个单独的表空间可能有点麻烦,尤其是如果它是自动扩展的,并且希望回收空间时(因为这个原因,我们建议关闭自动扩展功能,至少设置一个合理的空间范围)。回收空间唯一的方式是导出数据,关闭MySQL,删除所有文件,修改配置,重启,让InnoDB创建新的数据文件,然后导入数据。InnoDB这种表空间管理方式很让人头疼——不能简单地删除文件或者改变大小。如果表空间损坏了,InnoDB会拒绝启动。对日志文件也一样的严格。如果像MyISAM—样随便移动文件,千万要谨慎!
innodb_file_per_table选项让InnoDB为每张表使用一个文件,MySQL4.1和之后的版本都支持。它在数据字典存储为“表名.ibd”的数据。这使得删除一张表时回收空间简单多了,并且可以容易地分散表到不同的磁盘上。然而,把数据放到多个文件,总体来说可能导致更多的空间浪费,因为把单个InnoDB表空间的内部碎片浪费分布到了多个.idb文件。对于非常小的表,这个问题更大,因为InnoDB的页大小是16 KB。即使表只有1KB的数据,仍然需要至少16KB的磁盘空间。
即使打开innodb_file_per_table选项,依然需要为回滚日志和其他系统数据创建共享表空间。没有把所有数据存在其中是明智的做法,但最好还是关闭它的自动增长,因为无法在不重新导入全部数据的情况下给共享表空间瘦身。
一些人喜欢使用innodb_file_per_table,只是因为特别容易管理,并可以看到每个表的文件。例如,可以通过査看文件的大小来确认表的大小,这比用SHOW TABLE STATUS来看快多了,这个命令需要执行很多复杂的工作来判断给一个表分配了多少页面。
设置innodb_file_per_table也有不好的一面:更差的DROP TABLE性能。这可能足以导致显而易见的服务器端阻塞。因为有如下两个原因:
- 删除表需要从文件系统层去掉(删除)文件,这可能在某些文件系统(ext3)上会很慢。可以通过欺骗文件系统来缩短这个过程:把文件链接到一个0字节的文件,然后手动删除这个文件,而不用等待MySQL来做。
- 当打开这个选项,每张表都在InnoDB中使用自己的表空间。结果是,移除表空间实际上需要InnoDB锁定和扫描缓冲池,查找属于这个表空间的页面,在一个有庞大的缓冲池的服务器上做这个操作是非常慢的。如果打算删除很多InnoDB表(包括临时表)并且用了innodb_file_per_table,可能会从PerconaServer包含的一个修复中获益,它可以让服务器慢慢地清理掉属于被删除表的页面。只需要设置innodb_lazy_drop_table这个选项。
什么是最终的建议?我们建议使用innodb_file_per_table并且给共享表空间设置大小范围,这样可以过得舒服点(不用处理那些空间回收的事)。如果遇到任何头痛的场景,就像上面说的,考虑用下Percona的那个修复。
提醒一下,事实上没有必要把InnoDB文件放在传统的文件系统上。像许多的传统数据库服务器一样,InnoDB提供使用裸设备的选项——例如,一个没有格式化的分区——作为它的存储。然而,今天的文件系统已经可以存放足够大的文件,所以已经没有必要使用这个选项。使用裸设备可能提升几个百分点的性能,但是我们不认为这点小提升足以抵消这样做带来的坏处,我们不能直接用文件管理数据。当把数据存在一个裸设备分区时,不能使用mv、cp或其他任何工具来操作它。最终,这点小的性能收益显然不值得。
行的旧版本和表空间 在一个写压力大的环境下,InnoDB的表空间可能增长得非常大。如果事务保持打开状态很久(即使它们没有做任何事),并且使用默认的REPEATABLE READ事务隔离级别,InnoDB将不能删除旧的行版本,因为没提交的事务依然需要看到它们。InnoDB把旧版本存在共享表空间,所以如果有更多的数据在更新,共享表空间会持续增长。有时这个问题并非是没提交的事务的原因,也可能是工作负载的问题:清理过程只有一个线程处理,直到最近的MySQL版本才改进,这可能导致清理线程处理速度跟不上旧版本行数增加的速度。
无论发生何种情况,SHOW INNODB STATUS的数据都可以帮助定位问题。査看历史链表的长度会显示了回滚日志的大小,以页为单位。
分析TRANSACTIONS部分的第一行和第二行可以证实这个观点,这部分展示了当前事务号以及清理线程完成到了哪个点。如果这个差距很大,可能有大量的没有清理的事务。
这有个例子:
------------ TRANSACTIONS ------------ Trx id counter 0 80157601 Purge done for trx’s n:o <0 80154573 undo n:o <0 0
事务标识是一个64比特的数字,由两个32比特的数字(在更新版本的InnoDB中这是个十六进制的数字)组成,所以需要做一点数学计算来计算差距。在这个例子中就很简单了,因为最髙位是0 :那么有80 157 601 - 80 154 573 = 3028个“潜在的”没有被清理的事务(innotop可以做这个计算)。我们说“潜在的”,是因为这跟有很多没有清理的行是有很大区别的。只有改变了数据的事务才会创建旧版本的行,但是有很多事务并没有修改数据(相反的,一个事务也可能修改很多行)。
如果有个很大的回滚日志并且表空间因此增长很快,可以强制MySQL减速来使InnoDB的清理线程可以跟得上。这听起来不怎么样,但是没办法。否则,InnoDB将保持数据写入,填充磁盘直到最后磁盘空间爆满,或者表空间大于定义的上限。
为了控制写入速度,可以设置innodb_max_purge_lag变量为一个大于0的值。这个值表示InnoDB开始延迟后面的语句更新数据之前,可以等待被清除的最大的事务数量。你必须知道工作负载以决定一个合理的值。例如,事务平均影响1KB的行,并且可以容许表空间里有100MB的未清理行,那么可以设置这个值为100 000。
牢记,没有清理的行版本会对所有的査询产生影响,因为它们事实上使得表和索引更大了。如果清理线程确实跟不上,性能可能显著的下降。设置innodb_max_purge_lag变量也会降低性能,但是它的伤害较少。(请注意,这种实现思路是一个存在很多争议的话题,请看MySQL的bug60776来获得更多细节信息。)
在更新版本的MySQL中,甚至在更早版本的Percona Server和MariaDB,清理过程已经显著地提升了性能,并且从其他内部工作任务中分离出来。甚至可以创建多个专用的清理线程来更快地做这个后台工作。如果可以利用这些特性,会比限制服务器的服务能力要好得多。
双写缓冲(Doublewrite Buffer)
InnoDB用双写缓冲来避免页没写完整所导致的数据损坏。当一个磁盘写操作不能完整地完成时,不完整的页写入就可能发生,16KB的页可能只有一部分被写到磁盘上。有多种多样的原因(崩溃、Bug,等等)可能导致页没有写完整。双写缓冲在这种情况发生时可以保证数据完整性。
双写缓冲是表空间一个特殊的保留区域,在一些连续的块中足够保存100个页。本质上 是一个最近写回的页面的备份拷贝。当InnoDB从缓冲池刷新页面到磁盘时,首先把它们写(或者刷新)到双写缓冲,然后再把它们写到其所属的数据区域中。这可以保证每个页面的写入都是原子并且持久化的。
这意味着每个页都要写两遍?是的,但是因为InnoDB写页面到双写缓冲是顺序的,并且只调用一次fsync()刷新到磁盘,所以实际上对性能的冲击是比较小的——通常只有几个百分点,肯定没有一半那么多,尽管这个开销在SSD上更明显,下一章会讨论这个问题。更重要的是,这个策略允许日志文件更加高效。因为双写缓冲给了InnoDB一个非常牢固的保证,数据页不会损坏,InnoDB日志记录没必要包含整个页,它们更像是页面的二进制变化量。
如果有一个不完整的页写到了双写缓冲,原始的页依然会在磁盘上它的真实位置。当InnoDB恢复时,它将用原始页面替换掉双写缓冲中的损坏页面。然而,如果双写缓冲成功写入,但写到页的真实位置失败了,InnoDB在恢复时将使用双写缓冲中的拷贝来替换。InnoDB知道什么时候页面损坏了,因为每个页面在末尾都有校验值(Checksum)。校验值是最后写到页面的东西,所以如果页面的内容跟校验值不匹配,说明这个页面是损坏的。因此,在恢复的时候,InnoDB只需要读取双写缓冲中每个页面并且验证校验值。如果一个页面的校验值不对,就从它的原始位置读取这个页面。
有些场景下,双写缓冲确实没必要——例如,你也许想在备库上禁止双写缓冲。此外一些文件系统(例如ZFS)做了同样的事,所以没必要再让InnoDB做一遍。可以通过设置innodb_doublewrite为0来关闭双写缓冲。在PerconaServer中,可以配置双写缓冲存到独立的文件中,所以可以把这部分工作压力分离出来放在单独的盘上。
其他的I/O配置项
sync_binlog选项控制MySQL怎么刷新二进制日志到磁盘。默认值是0,意味着MySQL并不刷新,由操作系统自己决定什么时候刷新缓存到持久化设备。如果这个值比0大,它指定了两次刷新到磁盘的动作之间间隔多少次二进制日志写操作(如果autocommit被设置了,每个独立的语句都是一次写,否则就是一个事务一次写)。把它设置为0和1 以外的值是很罕见的。
如果没有设置sync_binlog为1,那么崩溃以后可能导致二进制日志没有同步事务数据。这可以轻易地导致复制中断,并且使得及时恢复变得不可能。无论如何,可以把这个值设置为1来获得安全的保障。这样就会要求MySQL同步把二进制日志和事务日志这两个文件刷新到两个不同的位置。这可能需要磁盘寻道,相对来说是个很慢的操作。
像InnoDB日志文件一样,把二进制日志放到一个带有电池保护的写缓存的RAID卷,可以极大地提升性能。事实上,写和刷新二进制日志缓存其实比InnoDB事务日志要昂贵多了,因为不像InnoDB事务日志,每次写二进制日志都会增加它们的大小。这需要每次写入文件系统都更新元信息。所以,设置sync_binlog=1可能比innodb_flush_log_at_trx_commit=1对性能的损害要大得多,尤其是网络文件系统,例如NFS。
一个跟性能无关的提示,关于二进制日志:如果希望使用expire_logs_days选项来自动清理旧的二进制日志,就不要用rm命令去删。服务器会感到困惑并且拒绝自动删除它们,并且PURGE MASTER LOGS也将停止工作。解决的办法是,如果发现了这种情况,就手动重新同步“主机名-bin.index”文件,可以用磁盘上现有日志文件的列表来更新。
其它章节更深入地涉及RAID,但是值得在这里重复一下,把带有电池保护写缓存的高质量RAID控制器设置为使用写回(Writeback)策略,可以支持每秒数千的写入,并且依然会保证写到持久化存储。数据写到了带有电池的高速缓存,所以即使系统断电它也能存在。但电源恢复时,RAID控制器会在磁盘被设置为可用前,把数据从缓存中写到磁盘。因此,一个带有电池保护写缓存的RAID控制器可以显著地提升性能,这是非常值得的投资。当然,SSD存储是另一个选择。
5.2 MyISAM的I/O配置
让我们从分析MyISAM怎么为索引操作I/O开始。MyISAM通常每次写操作之后就把索引变更刷新磁盘。如你打算在一张表上做很多修改,那么毫无疑问,批量操作会更快一些。
一种办法是用LOCK TABLES延迟写入,直到解锁这些表。这是个提升性能的很有价值的技巧,因为它使得你精确控制哪些写被延迟,以及什么时候把它们刷到磁盘。可以精确延迟那些希望延迟的语句。
通过设置delay_key_write变量,也可以延迟索引的写入。如果这么做,修改的键缓冲 块直到表被关闭才会刷新。可能的配置如下:(表可能因为多种原因被关闭。例如,服务器因为表缓存没有空间了就会关闭表,或者有人执行了FLUSH TABLES。)
OFF
MyISAM每次写操作后刷新键缓冲(键缓存,Key Buffer)中的脏块到磁盘,除非表被LOCK TABLES锁定了。
ON
打开延迟键写入,但是只对用DELAY_KEY_WRITE选项创建的表有效。
ALL
所有的MyISAM表都会使用延迟键写入。
延迟键写入在某些场景下可能很有帮助,但是通常不会带来很大的性能提升。当键缓冲的读命中很好但写命中不好时,数据又比较小,这可能很有用。当然也有一小部分缺点:
- 如果服务器缓存并且块没有被刷到磁盘,索引可能会损坏。
- 如果很多写被延迟了,MySQL可能需要花费更长时间去关闭表,因为必须等待缓冲刷新到磁盘。在MySQL5.0这可能引起很长的表缓存锁。
- 由于上面提到的原因,FLUSH TABLES可能需要很长时间。如果为了做逻辑卷(LVM)快照或者其他备份操作,而执行FLUSH TABLES WITH READ LOCK,那可能增加操作的时间。
- 键缓冲中没有刷回去的脏块可能占用空间,导致从磁盘上读取的新块没有空间存放。因此,查询语句可能需要等待MyISAM释放一些键缓存的空间。
另外,除了配置MyISAM的索引I/O还可以配置MyISAM怎样尝试从损坏中恢复。myisam_recover选项控制MyISAM怎样寻找和修复错误。需要在配置文件或者命令行中设置这个选项。可以通过下面的SQL语句查看选项的值,但是不能修改(这不是个印刷错误——系统里变量名跟命令的变量名有差异):
mysql> SHOW VARIABLES LIKE 'myisam_recover_options';
打开这个选项通知MySQL在表打开时,检査是否损坏,并且在找到问题的时候进行修复。可以设置的值如下:
DEFAULT(或者不设置)
使MySQL尝试修复任何被标记为崩溃或者没有标记为完全关闭的表。默认值不要求在恢复时执行.其他动作。跟大多数变量不同,这里DEFAULT值不是重置变量的值为编译值;它本质上意味着“没有设置”。
BACKUP
让MySQL将数据文件的备份写到.BAK文件,以便随后进行检査。
FORCE
即使.MYD文件中丢失的数据可能超过一行,也让恢复继续。
QUICK
除非有删除块,否则跳过恢复。块中有已经删除的行也依然会占用空间,但是可以被后面的INSERT语句重用。这可能比较有用,因为MyISAM大表的恢复可能花费相当长的时间。
可以使用多个设置,用逗号分隔。例如“BACKUP,FORCE”会强制恢复并且创建备份。
建议打开这个选项,尤其是只有一些小的MyISAM表时。服务器运行着一些损坏的MyISAM表是很危险的,因为它们有时可以导致更多数据损坏,甚至服务器崩溃。然而,如果有很大的表,原子恢复是不切实际的:它导致服务器打开所有的MyISAM表时都会检查和修复,这是低效的做法。在这段时间,MySQL会阻止连接做任何工作。如果有一大堆的MyISAM表,比较好的主意还是启动后用CHECK TABLES和REPAIR TABLES命令来做,这样对服务器影响比较少。不管哪种方式,检查和修复表都是很重要的。
打开数据文件的内存映射(MMAP)访问是另一个有用的MyISAM选项。内存映射使得MyISAM直接通过操作系统的页面缓存访问.MYD文件,避免系统调用的开销。在MySQL 5.1和更新的版本中,可以通过myisam_use_mmap选项打开内存映射。更老版本的MySQL只能对压缩的MyISAM表使用内存映射。
6.配置MySQL并发
当MySQL承受高并发压力时,可能会遇到不曾遇到过的瓶颈。这个章节阐述了当这些问题出现的时候,怎样去发现它们,以及在MyISAM和InnoDB遇到这样的压力时怎样获得尽可能最好的性能。
6.1 InnoDB并发配置
InnoDB是为高性能设计的,在最近几年它的提升非常明显,但依然不完美。InnoDB架构在有限的内存、单CPU、单磁盘的系统中仍然暴露出一些根本性问题。在高并发场景下,InnoDB的某些方面的性能可能会降低,唯一的办法是限制并发。
如果在InnoDB并发方面有问题,解决方案通常是升级服务器。相比当前的版本,像MySQL5.0和早期的MySQL5.1这样的旧版本,在高并发下完全是个悲剧。所有的东西都在全局Mutex(例如,缓冲池Mutex)上排队,导致服务器几乎陷入停顿。如果升级到某个更新版本的MySQL,在大部分场景都不再需要限制并发。
如果需要这么做,这里会介绍它是怎么工作的。InnoDB有自己的“线程调度器”控制线程怎么进入内核访问数据,以及它们在内核中一次可以做哪些事。最基本的限制并发的方式是使用innodb_thread_concurrency变量,它会限制一次性可以有多少线程进入内核,0表示不限制。如果在旧的MySQL版本里有InnoDB并发问题,这个变量是最重要的配置之一。
在任何架构和业务压力下,给这个变量设置个“靠谱”的值都很重要,理论上,下面的公式可以给出一个这样的值:
并发值=CPU数量*磁盘数量*2
但是在实践中,使用更小的值会更好一点。必须做实验来找出适合系统的最好的值。
如果已经进入内核的线程超过了允许的数量,新的线程就无法再进入内核。InnoDB使用两段处理来尝试让线程尽可能高效地进入内核。两段策略减少了因操作系统调度引起的上下文切换。线程第一次休眠innodb_thread_sleep_delay微秒,然后再重试。如果它依然不能进入内核,则放入一个等待线程队列,让操作系统来处理。
第一阶段默认的休眠时间是10 000微秒。当CPU有大量的线程处在“进入队列前的休眠”状态,因而没有被充分利用时,改变这个值在高并发环境里可能会有帮助。如果有大量的小査询,默认值可能也太大了,因为这增加了10毫秒的査询延时。
一旦线程进入内核,它会有一定数量的“票据(Tickets)”,可以让它“免费”返回内核,不需再做并发检査。这限制了一个线程回到其他等待线程之前可以做多少事。innodb_concurrency_tickets选项控制票据的数量。它很少需要修改,除非有很多运行时间极长的査询。票据是按査询授权的,不是按事务。一且査询完成,它没用完的票据就销毁了。
除了缓冲池和其他结构的瓶颈,还有另一个提交阶段的并发瓶颈,这个时候I/O非常密集,因为需要做刷新操作。innodb_commit_concurrency变量控制有多少个线程可以在同一时间提交。如果innodb_thread_concurrency配置得很低也有大量的线程冲突,那么配置这个选项可能会有帮助。
最后,有一个新的解决方案值得考虑:使用线程池(Thread Pool)来限制并发。原始的线程池实现已经随着MySQL6.0的代码树一起被废弃了,并且有严重缺陷。但是MariaDB已经重新实现了,并且Oracle最近放出了一个商业插件可以为MySQL5.5提供线程池功能。对这些东西我们都没有足够的经验来指导你怎么做,你也许会更加困惑,因为我们会指出这两种实现似乎都不满足Facebook,它在自己内部私有的MySQL分支中有一个叫做“准入控制”的特殊功能。
在以后的mysql版本会优化这些问题。
6.2 MyISAM并发配置
在某些条件下,MyISAM也允许并发插入和读取,这使得可以“调度”某些操作以尽可能少地产生阻塞。
在讲述MyISAM的并发设置之前,理解MyISAM是怎样删除和插入行的,是非常重要的。删除操作不会重新整理整个表,它们只是把行标记为删除,在表中留下“空洞”。MyISAM倾向于在可能的时候填满这些空洞,在插入行时重新利用这些空间。如果没有空洞了,它就把新行插入表的末尾。
尽管MyISAM是表级锁,它依然可以一边读取,一边并发追加新行。这种情况下只能读取到査询开始时的所有数据,新插入的数据是不可见的。这样可以避免不一致读。
然而,若表中间的某些数据变动了的话,还是难以提供一致读。MVCC是解决这个问题最流行的方法:一旦修改者创建了新版本,它就让读取者读数据的旧版本。可是,MyISAM并不像InnoDB那样支持MVCC,所以除非插入操作在表的末尾,否则不能支持并发插入。
通过设置concurrent_insert这个变量,可以配置MyISAM打开并发插入,可以配置为如下值:
0
MyISAM不允许并发插入,所有插入都会对表加互斥锁。
1
这是默认值。只要表中没有空洞,MyISAM就允许并发插入。
2
这个值在MySQL5.0以及更新版本中有效。它强制并发插入到表的末尾,即使表中有空洞。如果没有线程从表中读取数据,MySQL将把新行放在空洞里。使用这个设置通常会使表更加碎片化。
如果合并操作可以更加高效,也可以配置MySQL对一些操作进行延迟。举个实例,可以通过delay_key_write变量延迟写索引,正如这一章前面我们提到的。这牵涉到熟悉的权衡:立即写索引(安全但是昂贵),或者等待但是祈求在写发生前别断电(更快,但是遇到崩溃时可能引起巨大的索引损坏,因为索引文件已经过期了)。
也可以让INSERT、REPLACE、DELETE、以及UPDATE语句的优先级比SELECT语句更低,设置low_priority_updates选项就可以了。这相当于把L0W_PRIORITY修饰符应用到全局UPDATE语句。当使用MyISAM时,这是个非常重要的选项,这让SELECT语句可以获得相当好的并发度,否则一小部分获取高优先级写锁的语句就可能导致SELECT无法获取资源。
最后,尽管InnoDB的扩展性问题更经常被提及,但是MyISAM—样也有长时间获取Mutex的问题。在MySQL4.0和更早版本里,有一个全局的Mutex保护所有的键缓存I/O,在多处理器和多磁盘环境下很容易引起扩展性问题。MySQL4.1的键缓存代码做了改进,就不再有这些问题了,但是它依然对每个键缓冲区持有一个Mutex。当一个线程从键缓冲中复制键数据块到本地磁盘时会有竞争,从磁盘上读取时就没这个问题。磁盘瓶颈没了,但是当你在键缓冲里访问数据时,另一个瓶颈出现了。有时可以围绕这个问题把键缓冲分成多个区,但是这条路不总是行得通。例如,只涉及一个独立索引的时候,这问题就没有办法解决。于是,在多处理器的机器上SELECT査询并发可能相对单CPU的机器显著下降,即使当时只有这些SELECT查询在执行。
MariaDB提供分开的(分区的)键缓冲,如果经常遇到这个问题,也许可以带来帮助。
7.基于工作负载的配置
配置服务器的一个目标是把它定制得符合特定的工作负载。这需要精通所有类型的服务器活动的数量、类型,以及频率——不仅仅是査询语句,也包括其他的活动,例如连接服务器以及刷新表。
第一件应该做的事情是熟悉你的服务器,如果还没做就赶紧。了解什么样的査询跑在上面。用例如innotop这样的工具来监控它,用pt-query-digest来创建査询报告。这不仅帮助你全面地了解服务器正在做什么,还可以知道査询花费大量时间做了哪些事。
当服务器在满载情况下运行时,请尝试记录所有的査询语句,因为这是最好的方式来查看哪种类型的查询语句占用资源最多。同时,创建processlist快照,通过state或者command字段来聚合它们(innotop可以实现)。例如,是否大量地在复制数据到临时表,或者排序数据?如果有,也许需要优化査询语句,以及查看临时表和排序缓冲配置项。
7.1 优化BLOB和TEXT的场景
BLOB和TEXT列对MySQL来说是特殊类型的场景(我们把所有BLOB和TEXT都简单称为BLOB类型,因为它们属于相同类型的数据)。BLOB值有几个限制使得服务器分它的处理跟其他类型不一样。一个最重要的注意事项是,服务器不能在内存临时表中存储BLOB值,因此,如果一个查询涉及BLOB值,又需要使用临时表——不管它多小——它都会立即在磁盘上创建临时表。这样效率很低,尤其是对小而快的査询。临时表可能是查询中最大的开销。
有两种办法来减轻这个不利的情况:通过SUBSTRING()函数把值转换为VARCHAR,或者让临时表更快一些。
让临时表运行更快的最好方式是,把它们放在基于内存的文件系统(GNU/Linux上是tmpfs)。这会降低一些开销,尽管这依然比内存表慢许多。因为操作系统会避免把数据写到磁盘,所以内存文件系统可以帮助提升性能。一般的文件系统也会在内存中缓存,但是操作系统会每隔几秒就刷新一次。tmpfs文件系统从来不会刷新,它就是为低开销和简单起见而设计的。例如,没必要为这个文件系统预备任何恢复方案。这使得它更快。
服务器设置里控制临时表文件放在哪的是tmpdir。建议监控文件系统使用率以保证有足够的空间存放临时表。如果需要,可以指定多个临时表存放位置,MySQL将会轮询使用。
如果BLOB列非常大,并且用的是InnoDB,也许可以调大InnoDB日志缓冲大小。在这一章前面有更多关于这方面的内容。
对于很长的变长列(例如,BLOB、TEXT,以及长字符列),InnoDB存储一个768字节的前缀在行内。如果列的值比前缀长,InnoDB会在行外分配扩展存储空间来存剩下的部分。它会分配一个完整的16KB的页,像其他所有的InnoDB页面一样,每个列都有自己的页面(不同的列不会共享扩展存储空间)。InnoDB—次只为一个列分配一个页的扩展存储空间,直到使用了超过32个页以后,就会一次性分配64个页面。
注意,我们说过InnoDB可能会分配扩展存储空间。如果总的行长(包括大字段的完整长度)比InnoDB的最大行长限制要短(比8KB小一些),InnoDB将不会分配扩展存储空间,即使大字段(Long column)的长度超过了前缀长度。
最后,当InnoDB更新存储在扩展存储空间中的大字段时,将不会在原来的位置更新。而是会在扩展存储空间中写一个新值到一个新的位置,并且不会删除旧的值。
所有这一切都有以下后果:
- 大字段在InnoDB里可能浪费大量空间。例如,若存储字段值只是比行的要求多了一个字节,也会使用整个页面来存储剩下的字节,浪费了页面的大部分空间。同样的,如果有一个值只是稍微超过了32个页的大小,实际上就需要使用96个页面。
- 扩展存储禁用了自适应哈希,因为需要完整地比较列的整个长度,才能发现是不是正确的数据(哈希帮助InnoDB非常快速地找到“猜测的位置”,但是必须检査“猜测的位置”是不是正确)。因为自适应哈希是完全的内存结构,并且直接指向Buffer Pool中访问“最”频繁的页面,但对于扩展存储空间却无法使用自适应哈希。
- 太长的值可能使得在査询中作为WHERE条件不能使用索引,因而执行很慢。在应用WHERE条件之前,MySQL需要把所有的列读出来,所以可能导致MySQL要求InnoDB读取很多扩展存储,然后检査WHERE条件,丢弃所有不需要的数据。査询不需要的列绝不是好主意,在这种特殊的场景下尤其需要避免这样做。如果发现查询正遇到这个限制带来的问题,可以尝试通过覆盖索引来解决部分问题。
- 如果一张表里有很多大字段,最好是把它们组合起来单独存到一个列里面,比如说用XML文档格式存储。这让所有的大字段共享一个扩展存储空间,这比每个字段用自己的页要好。
- 有时候可以把大字段用C0MPRESS()压缩后再存为BLOB,或者在发送到MySQL前在应用程序中进行压缩,这可以获得显著的空间优势和性能收益。
7.2 优化排序(Filesorts)
MySQL有两种排序算法。如果査询中所有需要的列和ORDER BY的列总大小超过max_length_for_sort_data字节,则采用two-pass算法。或者当任何需要的列——即使没有被ORDER BY使用的列——是BLOB或者TEXT,也会采用这个算法。(可以用SUBSTRING()把这些列转换一下,就可以用single-pass算法了。)
MySQL有两个变量可以控制排序怎样执行。通过修改max_length_for_sort_data变量的值,可以影响MySQL选择哪种排序算法。因为single-pass算法为每行需要排序的数据创建一个固定大小的缓冲,对于VARCHAR列,在和max_length_for_sort_data比较时,使用的是其定义的最大长度,而不是所存储数据的实际长度。这也是为什么我们建议只选择必要的列的一个原因。
当MySQL必须排序BLOB或TEXT字段时,它只会使用前缀,然后忽略剩下部分的值。这是因为缓冲只能分配固定大小的结构体来保存要排序的值,然后从扩展存储空间中复制前缀到这个结构体中。使用max_sort_length变量可以指定这个前缀有多大。
可惜,MySQL无法査看它用了哪个算法。如果增加了max_length_for_sort_data变量的值,磁盘使用率上升了,CPU使用率下降了,并且Sort_merge_passes状态变量相对于修改之前开始很快地上升,也许是强制让很多的排序使用了single-pass算法。
8.完成基本配置
我们已经完成了服务器内核的旅程——希望你喜欢这个旅程!现在回到示例配置,并且看下怎样修改剩下的配置。
已经讨论了怎样设置一般的选项,例如数据目录、InnoDB和MyISAM缓存、日志,还有其他的一些。重温剩下的那些:
tmp_table_size和max_heap_table_size
这两个设置控制使用Memory引擎的内存临时表能使用多大的内存。如果隐式内存临时表的大小超过这两个设置的值,将会被转换为磁盘MyISAM表,所以它的大小可以继续增长。(隐式临时表是一种并非由自己创建,而是服务器创建,用于保存执行中的査询的中间结果的表。)
应该简单地把这两个变量设为同样的值。我们的示例配置文件中选择了32M。这可能不够,但是要谨防这个变量太大了。临时表最好呆在内存里,但是如果它们被撑得很大,实际上还是让它们使用磁盘比较好,否则可能会让服务器内存溢出。
假设査询语句没有创建庞大的临时表(通常可以通过合理的索引和査询设计来避免),那把这些变量设大一点,免得需要把内存临时表转换为磁盘临时表。这个过程可以在SHOW PROCESSLIST中看到。
可以査看服务器的SHOW STATUS计数器在某段时间内的变化,以此来査看创建临时表的频率以及是否是磁盘临时表。你不能判断一张(临时)表是先创建为内存表然后被转换为了磁盘表,还是一开始就创建的磁盘表(可能因为有BLOB字段),但是至少可以看到创建磁盘临时表有多频繁。仔细检査Created_tmp_disk_tables和Created_tmp_tables变量。
max_connections
这个设置的作用就像一个紧急刹车,以保证服务器不会因应用程序激增的连接而不堪重负。如果应用程序有问题,或者服务器遇到如连接延迟的问题,会创建很多新连接。但是如果不能执行査询,那打开一个连接没有好处,所以被“太多的连接”的错误拒绝是一种快速而代价小的失败方式。
把max_connections设置得足够髙,以容纳正常可能达到的负载,并且要足够安全,能保证允许你登录和管理服务器。例如,若认为正常情况将有300或者更多连接,则可以设置为500或者更多。如果不知道将会有多少连接,500也不是一个不合理的起点。默认值是100,对大部分应用来说这都不够。
要时时小心可能遇到连接限制的突然袭击。例如,若重新启动应用服务器,可能没有把它的连接关闭干净,同时MySQL可能没有意识到它们已经被关闭了。当应用服务器重新开始运转,并试图打开到数据库的连接,就可能由于挂起的连接还没有超时,而使新连接被拒绝。
观察Max_used_connections状态变量随着时间的变化。这个是高水位标记,可以告诉你服务器连接是不是在某个时间点有个尖峰。如果这个值达到了max_connections,说明客户端至少被拒绝了一次,并且当它重现的时候,应该使用来抓取服务器的活动状态。
thread_cache_size
设置这个变量,可以通过观察服务器一段时间的活动,来计算一个有理有据的值。观察Threads_connected状态变量并且找到它在一般情况下的最大值和最小值。你也许希望把线程缓存设置得足够大,以在高峰和低谷时都足够,甚至可能更大方一些,因为就算设置得有点太大了,一般也不是大问题。你也许可以设置为波动范围两到三倍的大小。例如,若Threads_connected状态从150变化到175,可以设置线程缓存为75。但是也不用设置得非常大,因为保持大量等待连接的空闲线程并没有什么真正的用处。250的上限是个不错的估算值(或者256,如果你喜欢2的次方。)
也可以观察Threads_created状态随着时间的变化。如果这个值很大或者一直增长,这是另一个线索,告诉你可能需要调大thread_cache_size变量。査看Threads_cached来看有多少线程已经在缓存中了。
一个相关的状态变量是Slow_launch_threads。这个状态如果是个很大的值,那么意味着某些情况延迟了连接分配新线程。这也是个线索,可能服务器有些问题了,但是不能明确地指出是哪出问题了。一般来说,可能是系统过载了,导致操作系统不能为新创建的线程调度CPU。这不是说你就需要增加线程缓存的大小了。你应该诊断这个问题并且修复它,而不是用缓存来掩盖问题,因为这还可能导致其他问题。
table_cache_size
这个缓存(或者在MySQL5.1中被分成两个缓存区)应该被设置得足够大,以避免总是需要重新打开和重新解析表的定义。你可以通过观察open_tables的值及其在一段时间的变化来检査该变量。如果你看到opened_tables每秒变化很大,那么table_cache值可能不够大。隐式临时表也可能导致打开表的数量不断增长,即使表缓存并没有用满,所以这可能也没什么问题。
该问题的线索应该是Opened_tables不断地增长,即使Open_tables并不跟table_cache_size—样大。
虽然表缓存很有用,也不应该把这个变量设置得太大。表缓存可能在两种情况下适得其反。
首先,MySQL没有一个很有效的方法来检査缓存,所以如果真的太大了,可能效率会下降。在大部分情况下,不应该把它设置得大于10 000,或者是10 240,如果喜欢使用2的N次方的话。
第二个原因是有些类型的工作负载是不能缓存的。如果工作负载不是可缓存的,不管把缓存设置得多大,任何访问都无法在缓存命中,忘记缓存吧,把它设置为0!这可以避免情况变得更糟糕,缓存不命中比昂贵的缓存检査后再不命中还是要好的。什么类型的工作负载不是可缓存的?如果有几万或几十万张表,并且它们都很均匀地被使用,就不可能把它们全缓存了,最好把这个变量设得小一点。当系统上有数量非常多的并行应用而其中没有一个是非常忙碌的,有时候这是适当的。
这个值从max_connections的10倍开始设置是比较有道理的,但是再次说明,在大部分场景下最好保持在10000以下甚至更低。
还有其他一些类型的设置可能经常会包含在配置文件中,包括二进制日志以及复制设置。二进制日志对恢复到某个时间点,以及复制是非常有用的,另外复制还有一些它自己的设置。会在其它章节中覆盖复制和备份的重要设置。
9.安全和稳定的设置
基本配置设置到位后,可能希望启用一些使服务器更安全和更可靠的设置。它们中的一些会影响性能,因为保证安全性和可靠性往往要付出一些代价。有些人意识到了:他们能阻止愚蠢的错误发生,比如把无意义的数据插入服务器,以及一些变动在日常操作中没有啥区别,只是在很边缘的情况防止糟糕的事情发生。
让我们首先来看看收集的一些对一般服务器都有用的配置项:
expire_logs_days
如果启用了二进制日志,应该打开这个选项,可以让服务器在指定的天数之后清理旧的二进制日志。如果不启用,最终服务器的空间会被耗尽,导致服务器卡住或崩溃。我们建议把这个选项设置得足够从两个备份之前恢复(在最近的备份失败的情况下)。即使每天都做备份,还是建议留下7〜14天的二进制日志。从我们的经验来看,当遇到一些不常见的问题时,你会感谢有这一两个星期的二进制日志。例如重搭一个备机再次尝试赶上主库。应该保持足够多的二进制日志,遇到这些情况时可以给自己一些呼吸的空间。
max_allowed_packet
这个设置防止服务器发送太大的包,也会控制多大的包可以被接收。默认值可能太小了,但设置得太大也可能有危险。如果设置得太小,有时复制上会出问题,通常表现为备库不能接收主库发过来的复制数据。你也许需要增加这个设置到16MB或者更大。这些文档里没有,但这个选项也控制在一个用户定义的变量的最大值,所以如果需要非常大的变量,要小心—如果超过这个变量的大小,它们可能被截断或者设置为NULL。
max_connect_errors
如果有时网络短暂抽风了,或者应用配置出现错误,或者有另外的问题,如权限,在短暂的时间内不断地尝试连接,客户端可能被列入黑名单,然后将无法连接,直到再次刷新主机缓存。这个选项的默认设置太小了,很容易导致问题。你也许希望增加这个值,实际上,如果知道服务器可以充分抵御蛮力攻击,可以把这个值设得非常大,以有效地禁用主机黑名单。
skip_name_resolve
这个选项禁用了另一个网络相关和鉴权认证相关的陷阱:DNS査找。DNS是MySQL连接过程中的一个薄弱环节。当连接服务器时,默认情况下,它试图确定连接和使用的主机的主机名,作为身份验证凭据的一部分。(就是说,你的凭据是用户名,主机名、以及密码——并不只是用户名和密码)但是验证主机来源,服务器需要执行DNS的正向和反向査找。要是DNS有问题就悲剧了,在某些时间点这是必然的事。当发生这样的情况时,所有事都会堆积起来,最终导致连接超时。为了避免这种情况,我们强烈建议设置这个选项,在验证时关闭DNS査找。然而,如果这么做,需要把基于主机名的授权改为用IP地址、通配符,或者特定主机名“localhost”,因为基于主机名的账号会被禁用。
sql_mode
这个设置可以接受多种多样的值来改变服务器行为。我们不建议只是为了好玩而改变这个值;最好在大多数情况下让MySQL像MySQL,不要尝试让它的行为像其他数据库服务器。(许多客户端和图形界面工具,除了MySQL还有它们自己的SQL方言,例如,若修改它用更符合ANSI的SQL,有些操作会没法做。)然而,有些选项值是很有用的,有些在具体情况可能是值得考虑的。建议査看文档中下面这些选项,并且考虑使用它们:STRICT_TRANS_TABLES、ERROR_FOR_DIVISION_BY_ZERO、N0_AUTO_CREATE_USER、NO_AUTO_VALUE_ON_ZERO、NO_ENGINE_SUBSTITUTION、N0_ZER0_DATE、N0_ZER0_IN_DATE和ONLY_FULL_GROUP_BY。
然而,要意识到对已经存在的应用修改这些设置值可不是个好主意,因为这么做可能让服务器跟应用预期不兼容。人们不经意间写的査询中应用的列不在GROUP BY中,或者用聚合函数,这种情况非常常见,例如,若想打开ONLY_FULL_GROUP_BY选项,最好首先在开发或未上线服务器上做一下测试,一旦要在生产环境部署则必须确认所有地方都可以工作。
sysdate_is_now
这是另一个可能导致与应用预期向后不兼容的选项。但如果不是明确需要SYSDATE()函数的非确定性行为(非确定性行为可能会导致复制中断或者使得基于时间点的备份恢复结果不可信),那么你可能希望打开该选项以确保SYSDATE()函数有确定的行为。
下面的选项可以控制复制行为,并且对防止备库出问题非常有帮助:
read_only
这个选项禁止没有特权的用户在备库做变更,只接受从主库传输过来的变更,不接受从应用来的变更。我们强烈建议把备库设置为只读模式。
skip_slave_start
这个选项阻止MySQL试图自动启动复制。因为在不安全的崩溃或其他问题后,启动复制是不安全的,所以需要禁用自动启动,用户需要手动检査服务器,并确定它是安全的之后再开始复制。
slave_net_timeout
这个选项控制备库发现跟主库的连接已经失败并且需要重连之前等待的时间。默认值是一个小时,太长了。设置为一分钟或更短。
sync_master_info、sync_relay_log、sync_relay_log_info
这些选项,在MySQL5.5以及更新版本中可用,解决了复制中备库长期存在的问题:不把它们的状态文件同步到磁盘,所以服务器崩溃后可能需要人来猜测复制的位置实际上在主库是哪个位置,并且可能在中继日志(Relay Log)里有损坏。这些选项使得备库崩溃后,更容易从崩溃中恢复。这些选项默认是不打开的,因为它们会导致备库额外的fsync()操作,可能会降低性能。如果有很好的硬件,我们建议打开这些选项,如果复制中出现fsync()造成的延时问题,就应该关闭它们。
Percona Server中有一种侵入性更小的方式来做这些工作,即打开innodb_overwrite_relay_log_info选项。这可以让InnoDB在事务日志中存储复制的位置,这是完全事务化的,并且不需要任何额外的fsync()操作。在崩溃恢复期间,InnoDB会检査复制的元信息文件,如果文件过期了就更新为正确的位置。
10.高级InnoDB设置
InnoDB历史:首先是内建(built-in)的版本,然后有了两个有效版本,现在更新的版本再次变成了一个。更新的InnoDB代码有更多的功能和非常好的扩展性。如果正在使用MySQL5.1,应该明确地配置MySQL忽略旧版本的InnoDB而使用新版的。这将极大地提升服务器性能。需要打开ignore_builtin_innodb选项,然后配置plugin_load选项把InnoDB作为插件打开。建议参考InnoDB文档中对应平台上的扩展语法。
对于新版本的InnoDB,有一些新的选项可以用。如果启用,它们中有些对服务器性能相当重要,也有一些安全性和稳定性的选项,如下所示。
innodb
这个看似平淡无奇的选项实际上非常重要,如果把这个值设置为FORCE,只有在InnoDB可以启动时,服务器才会启动。如果使用InnoDB作为默认存储引擎,这一定是你期望的结果。你应该不会希望在InnoDB失败(例如因为错误的配置而导致的不可启动)的情况下启动服务器,因为写的不好的应用可能之后会连接到服务器,导致一些无法预知的损失和混乱。最好是整个服务器都失败,强制你必须査看错误日志,而不是以为服务器正常启动了。
innodb_autoinc_lock_mode
这个选项控制InnoDB如何生成自增主键值,某些情况下,例如高并发插入时,自增主键可能是个瓶颈。如果有很多事务等待自增锁(可以在SHOW ENGINE INNODB STATUS里看到),应该审视这个变量的设置。手册上已经详细解释了该选项的行为,在此我们就不再重复了。
innodb_buffer_pool_instances
这个选项在MySQL5.5和更新的版本中出现,可以把缓冲池切分为多段,这可能是在髙负载的多核机器上提升MySQL可扩展性最重要的一个方式了。多个缓冲池分散了工作压力,所以一些全局Mutex竞争就没有那么大了。
目前尚不清楚什么情况下应该选择多个缓冲池实例。我们运行过八个实例的基准,但是直到MySQL5.5已经广泛部署了很长一段时间,我们依然不明白多个缓冲池实例的一些微妙之处。
我们不是暗示MySQL5.5没有在生产环境广泛部署。只是对我们已经帮助解决过的大部分互斥锁相互争用的极端场景的用户来说,升级可能需要很多个月的时间来计划、验证,并执行。这些用户有时运行着髙度定制化的MySQL版本,使得更加倍谨慎地对待升级。当越来越多的这类用户升级到MySQL5.5,并以他们独特的方式进行压力验证,我们可能会学到关于多缓冲池的一些我们没见过的有趣的事情。也许直到那时,我们才可以说运行八个缓冲池实例是非常有益的。
值得注意的是Percona Server用了不同的方法来解决InnoDB互斥锁争用问题。相对于把缓冲池分成多个--个在许多像InnoDB的系统下经过检验无可否认的方法-我们选择把一些全局Mutex拆分为更细、更专用的Mutex。我们的测试显示最好的方式是结合这两种方法,在Percona Server 5.5版本中已经可用了:多缓冲区和更细粒度的锁。
innodb_io_capacity
InnoDB曾经在代码里写死了假设服务器运行在每秒100个I/O操作的单硬盘上。默认值很糟糕。现在可以告诉InnoDB服务器有多大的I/O能力。InnoDB有时需要把这个设置得相当高(在像PCI-ESSD这样极快的存储设备上需要设置为上万)才能稳定地刷新脏页,原因解释起来相当复杂。
innodb_read_io_threads和innodb_write_io_threads
这些选项控制有多少后台线程可以被I/O操作使用。最近版本的MySQL里,默认值是4个读线程和4个写线程,对大部分服务器这都足够了,尤其是MySQL5.5里面可以用操作系统原生的异步I/O以后。如果有很多硬盘并且工作负载并发很大,可以发现这些线程很难跟上,这种情况下可以增加线程数,或者可以简单地把这个选项的值设置为可以提供I/O能力的磁盘数量(即使后胃是一个RAID控制器)。
innodb_strict_mode
这个设置让MySQL在某些条件下把警告改成抛错,尤其是无效的或者可能有风险的CREATE TABLE选项。如果打开这个设置,就必然会检査所有CREATE TABLE选项,因为它不会让你创建一些用起来比较爽(但是有隐患)的表。有时这有点悲观,过于严格了。当尝试恢复备份时可能就不希望打开这个选项了。
innodb_old_blocks_time
InnoDB有个两段缓冲池LRU(最近最少使用)链表,设计目的是防止换出长期使用很多次的页面。像mysqldump产生的这种一次性的(大)査询,通常会读取页面到缓冲池的LRU列表,从中读取需要的行,然后移动到下一页。理论上,两段LRU链表将阻止此页取代很长一段时间内都需要用到的页面被放入“年轻(Young)”子链表,并且只在它已被浏览过多次后将其移动到“年老(Old)”子链表。但是InnoDB默认没有配置为防止这种情况,因为页内有很多行,所以从页面读取的行的多次访问,会导致它立即被转移到“年老(Old)”子链表,对那些需要长时间缓存的页面带来换出的压力。
这个变量指定一个页面从LRU链表的“年轻”部分转移到“年老”部分之前必须经过的毫秒数。默认情况下它设置为0,将它设为诸如1000毫秒(一秒)这样的小一点的值,在我们的基准测试中已被证明非常有效。
11.总结
在阅读完这一章节之后,应该有了一个比默认设置好得多的服务器配置。服务器应该更快更稳定了,并且除非运行出现了罕见的状况,都应该没有必要再去做优化配置的工作了。
复习一下,建议从参考示例配置文件开始,设置符合服务器和工作负载的基本选项,增加安全性和完整性所需的选项,并且,如果合适的话,在MySQL5.5中配置新版的InnoDB Plugin才有的配置项。这就是关于优化服务器配置所需要做的全部的事情。
如果使用的是InnoDB,最重要的选项是下面这两个:
- innodb_buffer_pool_size
- innodb_log_file_size
恭喜你——解决了真实存在的配置问题中的绝大部分!如果使用我们的在线配置工具http://tools.percona.com,对这些问题和其他配置选项的使用,会得到很好的建议。
我们也提出了很多关于不要做什么的建议。其中最重要的是不要“调优”服务器;不要使用比率、公式或“调优脚本”作为设置配置变量的基础;不要信任来自互联网上的不明身份的人的意见;不要为了看起来很糟糕的事情去不断地刷SHOW STATUS。如果有些设置其实是错误的,在剖析服务器性能时也会展现出来。
有几个重要的设置没有在本章讨论,主要是因为它们是为特定类型的硬件和工作负载服务的。暂不讨论这些设置,因为我们相信,任何关于怎样设置的意见,都需要与内部流程的解释工作一起来做。这给我们带来了下一章,它会告诉你如何优化MySQL的硬件和操作系统,反之亦然。