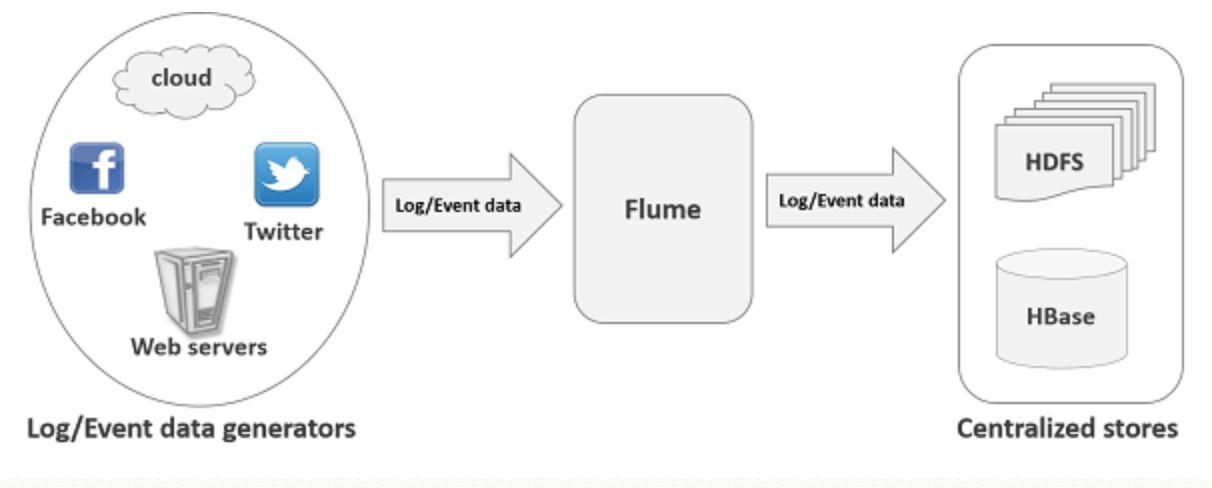
1、Flume概念
flume是分布式日志收集系统,将各个服务器的数据收集起来并发送到指定地方。
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。
2、Event的概念
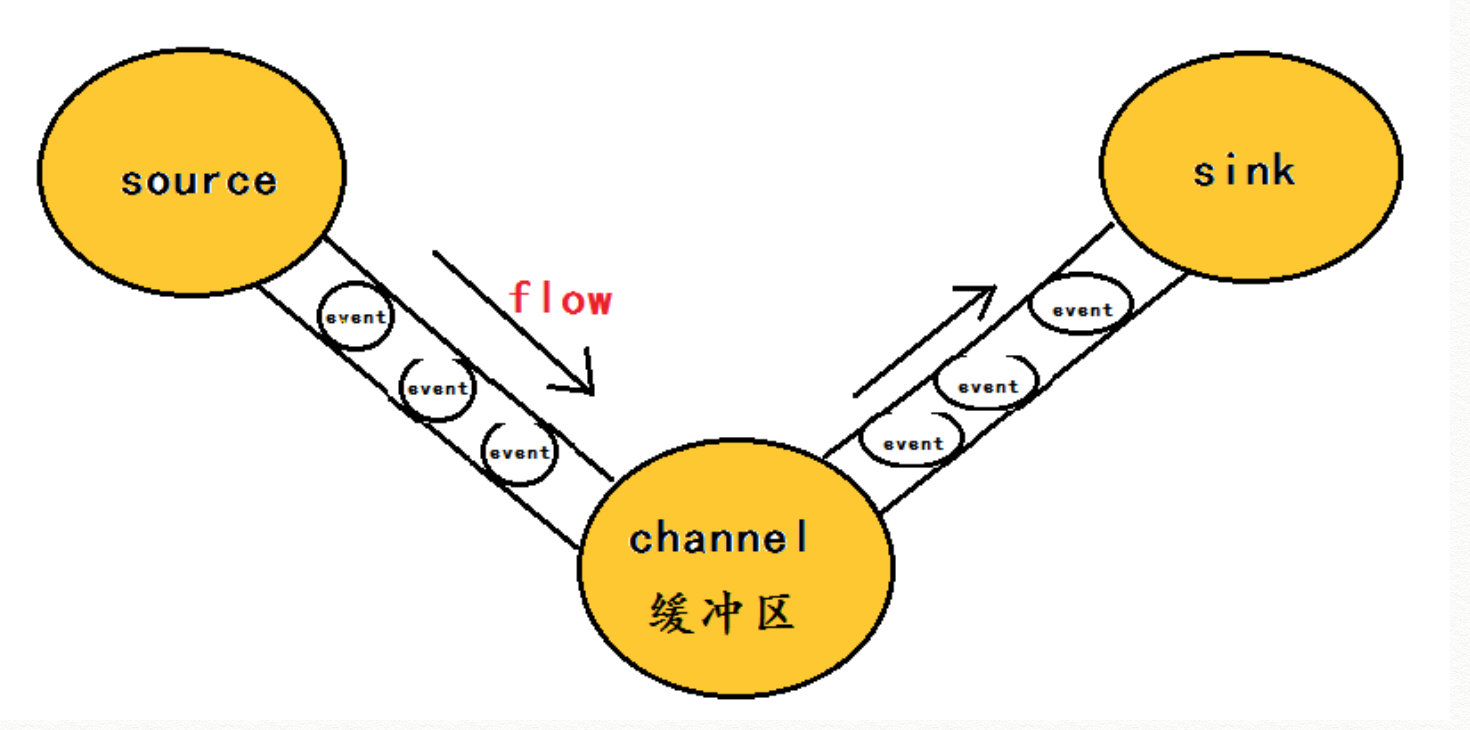
flume的核心:把数据从数据源source收集过来,再将收到的数据发送到指定的目的地sink。发送到sink之前,会先缓存到channel,待数据真正到达sink后,flume再删除自己缓存的数据。事务保证在event级别进行。
event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。
event本身是一个字节数组,可以携带headers信息。
3、flume架构
flume本身是一个agent,是一个java进程,运行在日志收集节点。
agent包含三个核心组件:source > channel > sink。
source:专门用于收集数据,支持console、RPC、text、tail、syslog、exec。
channel:对采集到的数据进行简单缓存,可以存放在内存、文件、jdbc等
sink:用于把数据发送到目的地,支持HDFS、console、text、RPC、syslogTCP
4、flume运行机制
flume支持多级flume,即sink可以将数据写入下一个agent的source,从而连成串,整体处理。flume还支持扇入(source可以接收多个输入)、扇出(sink可以将数据输出到多个目的地)。
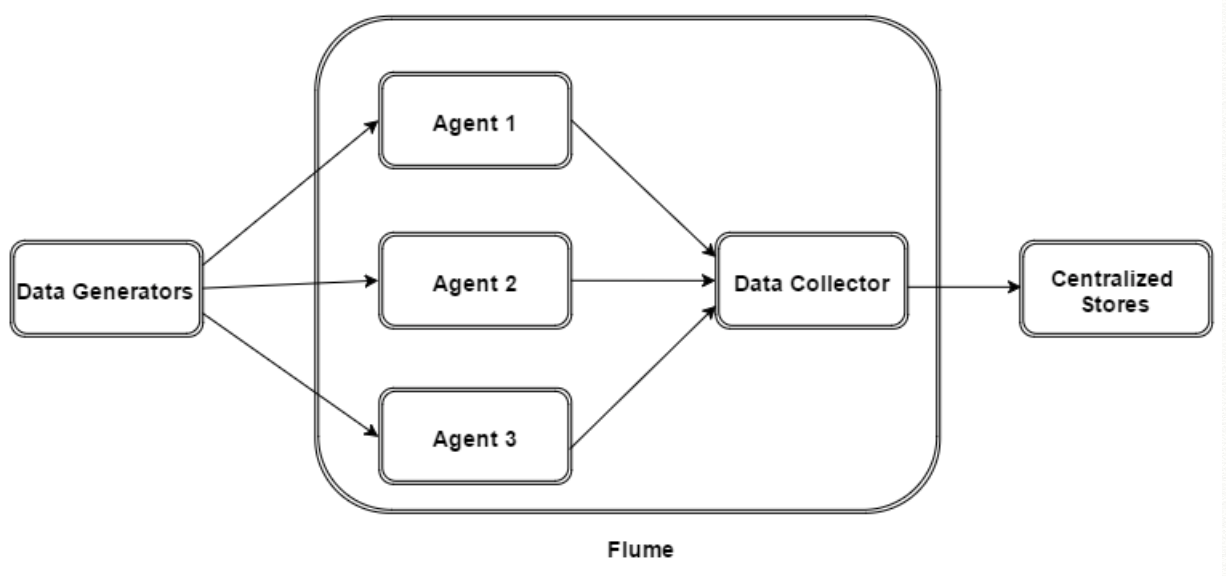
5、flume主要用于大数据处理的数据采集层,如日志采集。