官方文档:
https://www.oracle.com/technetwork/cn/java/javase/8-whats-new-2157071-zhs.html
https://blog.csdn.net/zwlove5280/article/details/77576216
http://www.cnblogs.com/onetwo/p/8526374.html
一、java语言的新特性
1、lambda
其实Lambda表达式的本质只是一个"语法糖",由编译器推断并帮你转换包装为常规的代码,因此你可以使用更少的代码来实现同样的功能
lambda表达式允许你通过表达式来代替功能接口。 lambda表达式就和方法一样,它提供了一个正常的参数列表和一个使用这些参数的主体(body,可以是一个表达式或一个代码块)
Lambda表达式的语法
基本语法:
(parameters) -> expression
或
(parameters) ->{ statements; }
举个例子
// 1. 不需要参数,返回值为 5 () -> 5 // 2. 接收一个参数(数字类型),返回其2倍的值 x -> 2 * x // 3. 接受2个参数(数字),并返回他们的差值 (x, y) -> x – y // 4. 接收2个int型整数,返回他们的和 (int x, int y) -> x + y // 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void) (String s) -> System.out.print(s)
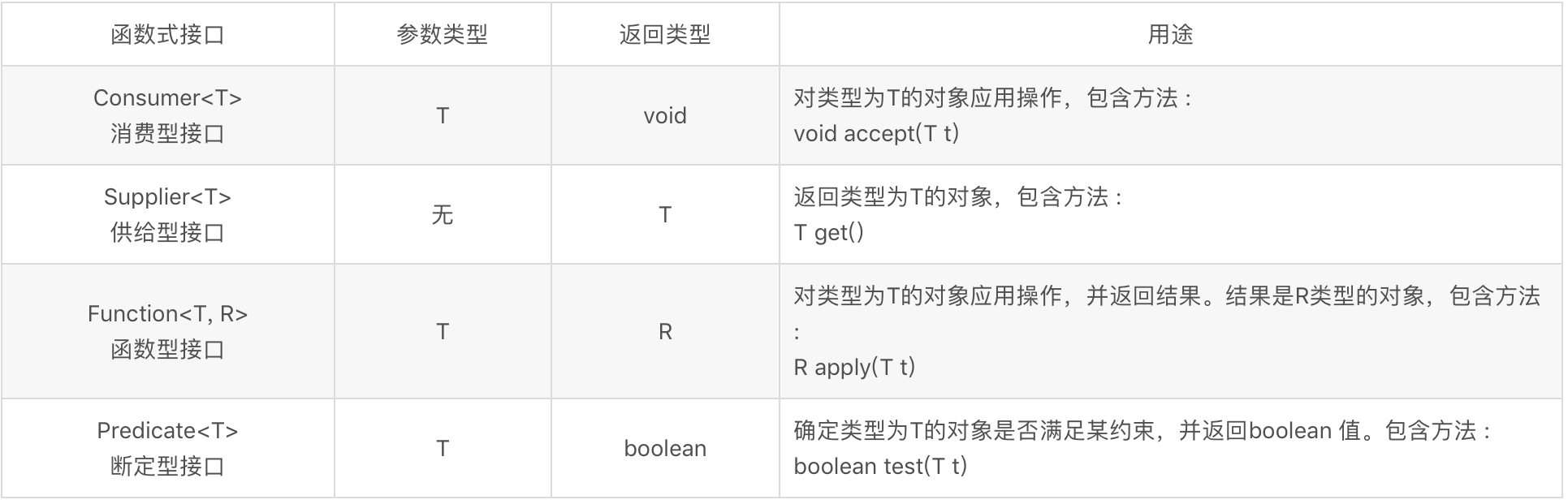
函数式接口
函数式接口是只有一个方法的接口,用作lambda表达式的类型。可以使用注解 @FunctionalInterface 说明这个接口是一个函数式接口
举个例子
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface <code>Runnable</code> is used
* to create a thread, starting the thread causes the object's
* <code>run</code> method to be called in that separately executing
* thread.
* <p>
* The general contract of the method <code>run</code> is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
new Thread(() -> System.out.println("java8 start !")).start();
举个例子
懒惰求值:
int x=2; Supplier<Integer> supplier = ()->x+3; int result=supplier.get();
2、接口的默认方法和静态方法
Java 8使用两个新概念扩展了接口的含义:默认方法和静态方法。默认方法使得接口有点类似traits,不过要实现的目标不一样。默认方法使得开发者可以在 不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的类也同时实现这个新加的方法。
默认方法和抽象方法之间的区别在于抽象方法需要实现,而默认方法不需要。接口提供的默认方法会被接口的实现类继承或者覆写。
举个例子:
private interface Defaulable {
// Interfaces now allow default methods, the implementer may or
// may not implement (override) them.
default String notRequired() {
return "Default implementation";
}
}
private static class DefaultableImpl implements Defaulable {
}
private static class OverridableImpl implements Defaulable {
@Override
public String notRequired() {
return "Overridden implementation";
}
}
Java 8带来的另一个有趣的特性是在接口中可以定义静态方法
举个例子:
private interface DefaulableFactory {
// Interfaces now allow static methods
static Defaulable create( Supplier< Defaulable > supplier ) {
return supplier.get();
}
}
由于JVM上的默认方法的实现在字节码层面提供了支持,因此效率非常高。默认方法允许在不打破现有继承体系的基础上改进接口。该特性在官方库中的应用是:给java.util.Collection接口添加新方法,如stream()、parallelStream()、forEach()和removeIf()等等。尽管默认方法有这么多好处,但在实际开发中应该谨慎使用:在复杂的继承体系中,默认方法可能引起歧义和编译错误。
3、方法引用
方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法。方法引用提供了一种引用而不执行方法的方式,它需要由兼容的函数式接口构成的目标类型上下文。计算时,方法引用会创建函数式接口的一个实例。
当Lambda表达式中只是执行一个方法调用时,不用Lambda表达式,直接通过方法引用的形式可读性更高一些。方法引用是一种更简洁易懂的Lambda表达式。
注意方法引用是一个Lambda表达式,其中方法引用的操作符是双冒号"::"。
举个例子:
Arrays.sort(stringsArray,(s1,s2)->s1.compareToIgnoreCase(s2));
方法引用:
Arrays.sort(stringsArray, String::compareToIgnoreCase);
4、重复注解
自从Java 5中引入注解以来,这个特性开始变得非常流行,并在各个框架和项目中被广泛使用。不过,注解有一个很大的限制是:在同一个地方不能多次使用同一个注解。Java 8打破了这个限制,引入了重复注解的概念,允许在同一个地方多次使用同一个注解。
在Java 8中使用@Repeatable注解定义重复注解,实际上,这并不是语言层面的改进,而是编译器做的一个trick,底层的技术仍然相同。
举个例子:
public class RepeatingAnnotations {
@Target( ElementType.TYPE )
@Retention( RetentionPolicy.RUNTIME )
public @interface Filters {
Filter[] value();
}
@Target( ElementType.TYPE )
@Retention( RetentionPolicy.RUNTIME )
@Repeatable( Filters.class )
public @interface Filter {
String value();
};
@Filter( "filter1" )
@Filter( "filter2" )
public interface Filterable {
}
public static void main(String[] args) {
for( Filter filter: Filterable.class.getAnnotationsByType( Filter.class ) ) {
System.out.println( filter.value() );
}
}
}
另外,反射API提供了一个新的方法:getAnnotationsByType(),可以返回某个类型的重复注解,例如Filterable.class.getAnnoation(Filters.class)将返回两个Filter实例,输出到控制台的内容如下所示:
filter1
filter2
5、更好的类型推断
Java 8编译器在类型推断方面有很大的提升,在很多场景下编译器可以推导出某个参数的数据类型,从而使得代码更为简洁。
举个例子:
public class Value< T > {
public static< T > T defaultValue() {
return null;
}
public T getOrDefault( T value, T defaultValue ) {
return ( value != null ) ? value : defaultValue;
}
}
public class TypeInference {
public static void main(String[] args) {
final Value< String > value = new Value<>();
value.getOrDefault( "22", Value.defaultValue() );
}
}
参数Value.defaultValue()的类型由编译器推导得出,不需要显式指明。在Java 7中这段代码会有编译错误,除非使用Value.<String>defaultValue()。
6、拓宽注解的应用场景
Java 8拓宽了注解的应用场景。现在,注解几乎可以使用在任何元素上:局部变量、接口类型、超类和接口实现类,甚至可以用在函数的异常定义上。
ElementType.TYPE_USER和ElementType.TYPE_PARAMETER是Java 8新增的两个注解,用于描述注解的使用场景。Java 语言也做了对应的改变,以识别这些新增的注解。
二、java编译器的新特性
为了在运行时获得Java程序中方法的参数名称,老一辈的Java程序员必须使用不同方法,例如Paranamer liberary。Java 8终于将这个特性规范化,在语言层面(使用反射API和Parameter.getName()方法)和字节码层面(使用新的javac编译器以及-parameters参数)提供支持。
public class ParameterNames {
public static void main(String[] args) throws Exception {
Method method = ParameterNames.class.getMethod( "main", String[].class );
for( final Parameter parameter: method.getParameters() ) {
System.out.println( "Parameter: " + parameter.getName() );
}
}
}
在Java 8中这个特性是默认关闭的,因此如果不带-parameters参数编译上述代码并运行,则会输出如下结果:
Parameter: arg0
如果带-parameters参数,则会输出如下结果(正确的结果)
Parameter: args
如果你使用Maven进行项目管理,则可以在maven-compiler-plugin编译器的配置项中配置-parameters参数:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<compilerArgument>-parameters</compilerArgument>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
三、java官方库的新特性
3.1 Optional
Java应用中最常见的bug就是空值异常。在Java 8之前,Google Guava引入了Optionals类来解决NullPointerException,从而避免源码被各种null检查污染,以便开发者写出更加整洁的代码。Java 8也将Optional加入了官方库。
Optional仅仅是一个容易:存放T类型的值或者null。它提供了一些有用的接口来避免显式的null检查,可以参考Java 8官方文档了解更多细节。
3.2 streams
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
1) Streams和collections的不同之处
- Stream没有存储。即不是一个存储结构,而是通过管道操作从Array,IO channel等转换而来。
- Stream本质上是泛函。Streams上的操作不会修改源数据,比如filter操作只是将符合要求的数据放在一个新的Stream,而不是真的删除源数据。
- Laziness-seeking,懒查询。
- 大小不受限制,collections 有大小限制,streams没有。比如,limit或者findfirst等Short-circuiting操作会在有限的时间内完成无限的大小的streams操作。
- 不可逆的,streams中的元素只能被操作一次。就像流水一样,一去不复返。如果你希望在源数据中获取一个新的Stream,必须在源数据上重新开始。
2) Stream的操作和管道
Stream操作是管道操作,操作分为中间操作和结束操作两种。整个管道操作的流程为数据源->中间操作->结束操作。
中间操作
比如:Stream.filter、Stream.map,可以有0个或者多个中间操作。中间操作返回的仍然是stream,这些操作经常是“懒惰的”。比如filter操作,并非真的对源数据进行过滤,而是重新创建一个Stream。而且当多个中间操作时,不是真的每次都去遍历源数据,而是在结束操作时,才会去遍历源数据,从而执行这些中间操作。在遍历中,操作的懒惰性表现在,并不是每次都是遍历所有的数据,比如“找出长度大于1000的第一个String”,找到之后就会返回。
中间操作又分为无状态和有状态两种。比如map和filter是无状态操作,也就是各元素间的操作是无关的,可单独进行。而distinct和sorted 是有状态操作,在操作时需要用到前元素,也就是元素之间的处理是相关的。
有状态的操作必须全部执行完毕的时候才能装入结果中。
结束操作
比如Sream.foreach、Stream.reduce,Stream.collect,结束操作是必须的。结束操作的目的是将Stream转换为想要的结果或者结构。当结束操作之后,当前管道结束,不可以再重复使用。如果你仍然想操作源数据,那你必须创建一个新的Stream.
3)stream特性
lazy
Stream 是惰性的(lazy),就如同 RxJava 中的 lazy Observable 一样。
Stream<Integer> integerStream = Stream.of(1, 2, 3);
Stream<Integer> filterStream = integerStream.filter(integer -> {
Log.d(TAG, "integer = " + integer);
return integer > 1;
});
如果运行这段代码,不会有任何 Log 出现,那么 Stream.filter() 有什么作用呢? Stream.filter() 就如同设计模式中的装饰模式一样,它只是对 Stream 进行装饰,这里的装饰指的就是过滤。
像 Steam.filter() 把一个 Stream 转化为另外一个 Stream 的方法,我称之为 过渡操作符(intermediate operations)。
而如果想要 Stream 运作起来,需要 Steam 中的 终止操作符( terminal operation ),例如 Stream.count();
Stream<Integer> integerStream = Stream.of(1, 2, 3);
Stream<Integer> filterStream = integerStream.filter(integer -> {
Log.d(TAG, "integer = " + integer);
return integer > 1;
});
long count = filterStream.count();
运行这段代码就可以看到 Log 的出现
一次性
Stream 只能在操作符( Stream 的方法)上执行一次,例如
Stream<Integer> integerStream = Stream.of(1, 2, 3);
integerStream.map(integer -> "s");
integerStream.filter(integer -> integer > 1);
虽然 map 和 filter 都是过渡操作符,但是运行程序后,会报错
java.lang.IllegalStateException: stream has already been operated upon or closed
所以一个流只能执行一次操作
流的有序性
Stream 如同 RxJava 的 Observable 一样,发射的元素都是有序的
List<Integer> collect = Stream.of(1, 2, 3, 4, 5)
.map(integer -> {
Log.d(TAG, "step1: " + integer);
return integer;
})
.map(integer -> {
Log.d(TAG, "step2: " + integer);
return integer;
})
.collect(Collectors.toList());
因为有 及早求值方法 Stream.collect(),所以可以看到 Log 信息
D/david: step1: 1 D/david: step2: 1 D/david: step1: 2 D/david: step2: 2 D/david: step1: 3 D/david: step2: 3 D/david: step1: 4 D/david: step2: 4 D/david: step1: 5 D/david: step2: 5
可关闭性
Stream 有一个 close() 方法,并且实现了 AutoCloaseable 接口。但是几乎所有的 Stream 都不需要在使用后关闭。一般来说,只有 Stream 来源于 IO 管道的,需要手动关闭。
顺序执行和并行执行
Stream 可以顺序执行,也可以并行执行。
Stream 也可以由创建的方式来决定顺序执行还是并行执行。例如,list.stream() 创建一个顺序执行的 Stream,而 list.parallelStream() 创建一个并行执行的 Stream。 然而执行的方式是可以通过 Stream.parallel() 和 Stream.sequential() 来改变的。
既然可以改变流的执行方法,自然也可以查询流的执行方式,Stream.isParallel() 方法查询是否并行的流。
4)创建 Stream
Stream.of()
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
Stream.of() 以类型为 T 的可变长数组 values 作为参数,创建 Stream 对象,例如
Stream<Integer> integerStream = Stream.of(1, 2, 3);
Stream.generate()
Stream.generate(Supplier s) 生成一个无线的流
Stream<Integer> integerStream = Stream.generate(new Supplier<Integer>() {
int i = 0;
@Override
public Integer get() {
return i++;
}
});
如果我们用一个 Stream 的 终止操作符 就可以看到无限个元素,例如用 Stream.forEach()
Stream.generate(new Supplier<Integer>() {
int i = 0;
@Override
public Integer get() {
return i++;
}
}).forEach(integer -> Log.d(TAG, "integer = " + integer));
运行后,就可以看到茫茫多的 Log 信息。
在实际中可能只需要这个无限流中的前10,那么可以用 Stream.limite(10) 来限制流中元素的个数
Stream.generate(new Supplier<Integer>() {
int i = 0;
@Override
public Integer get() {
return i++;
}
}).limit(10).forEach(integer -> Log.d(TAG, "integer = " + integer));
再运行代码,就只能看到前10个元素了。
Stream.iterate()
Stream.iterate() 方法用代码比较好解释,这个方法生成的流的关键代码是 Iterator 中的 next() 方法
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) {
// ...
final Iterator<T> iterator = new Iterator<T>() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
// 生成 Stream 中的元素
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
// 用 iterator 创建 Stream
// ...
}
Stream.iterate() 产生的 Stream 的第一个元素是 seed, 后续的元素是 f(seed), f(f(seed)), f(f(f(seed))) … , 例如
Stream.iterate(1, integer -> ++integer)
.limit(3)
.forEach(integer -> Log.d(TAG, "integer = " + integer));
产生的结果就是1,2,3 ,也就是对应的 1 , f(1), f(f(1))。
Stream.Builder.build()
以 Builder 模式创建 Stream
Stream.Builder<String> builder = Stream.builder();
builder.add("hello");
builder.accept("world");
Stream<String> stream = builder.build();
stream.forEach(s -> Log.d(TAG, "s = " + s));
add() 和 accept() 从实现上是等效的,只不过 add() 是 default 方法
Stream.concat()
Stream.concat(Stream< ? extends T > a, Stream< ? extends T > b),把 Stream b 连接到 Stream a 之后,a 和 b 中元素的顺序不变
Stream.empty()
创建一个空的 Stream,目前我还不知道这个到底怎么用。
集合创建Stream
List<Integer> list = Arrays.asList(1, 2, 3); Stream<Integer> stream = list.stream();
collection接口的定义如下
/**
* @author Josh Bloch
* @author Neal Gafter
* @see Set
* @see List
* @see Map
* @see SortedSet
* @see SortedMap
* @see HashSet
* @see TreeSet
* @see ArrayList
* @see LinkedList
* @see Vector
* @see Collections
* @see Arrays
* @see AbstractCollection
* @since 1.2
*/
public interface Collection<E> extends Iterable<E> {
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
数组创建Stream
int[] ints = new int[]{1, 3, 4};
IntStream stream1 = Arrays.stream(ints);
IntStream.range(lower, upper) 创建一个由下限到上限(不含)之间的元素组成的 IntStream
IntStream.rangeClosed(lower, upper) 创建一个由下限到上限(含)之间的元素组成的 IntStream
BufferedReader.lines() 创建一个有来自 BufferedReader 的行组成的流
BitSet.stream() 创建一个由 BitSet 中的设置位的索引组成的 IntStream
Stream.chars() 创建一个与 String 中的字符对应的 IntStream
5)使用Stream
结束流操作
forEach(Consumer<T> action) 将提供的操作应用于流的每个元素
ImmutableList.of("aa", "abb","abc","bb","cc").stream()
.forEach(s->System.out.println(s));
toArray() 使用流的元素创建一个数组
Object[] array=ImmutableList.of("aa", "abb","abc","bb","cc").stream()
.toArray();
reduce(...) 将流的元素聚合为一个汇总值
String res= ImmutableList.of("a", "b","c","d","e").stream()
.reduce("",(result,item)->result+item); //abcde
collect(...) 将流的元素聚合到一个汇总结果容器中
List res= ImmutableList.of("a", "b","c","d","e").stream()
.collect(Collectors.toList());
min(Comparator<T>) 通过比较符返回流的最小元素
Optional res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.min((s1, s2) -> s1.compareTo(s2));
System.out.println(res.get()); //a
max(Comparator<T>) 通过比较符返回流的最大元素
Optional res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.max((s1, s2) -> s1.compareTo(s2));
System.out.println(res.get()); //e
count() 返回流的大小
long res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.count();
allMatch(Predicate<T>) 是不是Stream中的所有元素都满足给定的匹配条件
boolean res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.allMatch(s->s.contains("a")); // false
anyMatch(Predicate<T>) Stream中是否存在任何一个元素满足匹配条件
boolean res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.anyMatch(s->s.contains("a")); //true
noneMatch(Predicate<T>) 是不是Stream中的所有元素都不满足给定的匹配条件
boolean res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.noneMatch(s->s.contains("a")); //false
findFirst 返回Stream中的第一个元素,如果Stream为空,返回空Optional
Optional res = ImmutableList.of("a", "b", "c", "d", "e").stream()
.findFirst();
中间流操作
distinct() 去重
long res = ImmutableList.of("a", "b", "a", "d", "e").stream()
.distinct().count(); //4
filter(Predicate<T>) 与预期匹配的流的元素
long res = ImmutableList.of("aa", "ab", "abc", "d", "be").stream()
.filter(s->s.contains("a")).count(); //3
map(Function<T, U>) 将提供的函数应用于流的元素的结果
List res = ImmutableList.of("aa", "ab", "abc", "d", "be").stream()
.map(s->s.toUpperCase()).collect(Collectors.toList());//[AA, AB, ABC, D, BE]
flatMap(Function<T, Stream<U>> 将提供的流处理函数应用于流元素后获得的流元素
List<String> res = ImmutableList.of("hello,world").stream()
.flatMap(s -> Arrays.stream(s.split(","))).collect(Collectors.toList());//["hello","world"]
map与flatMap的区别
List<String> words = new ArrayList<String>();
words.add("your");
words.add("name");
public static Stream<Character> characterStream(String s){
List<Character> result = new ArrayList<>();
for (char c : s.toCharArray())
result.add(c);
return result.stream();
}
Stream<Stream<Character>> result = words.map(w -> characterStream(w));
Stream<Character> letters = words.flatMap(w -> characterStream(w));
sorted 排序
List<String> res = ImmutableList.of("he", "aa", "cc").stream()
.sorted().collect(Collectors.toList());
limit(long) 截断至所提供长度的流元素
List<String> res = ImmutableList.of("he", "aa", "cc").stream()
.limit(2).collect(Collectors.toList());
skip(long) 丢弃了前 N 个元素的流元素
List<String> res = ImmutableList.of("he", "aa", "cc").stream()
.skip(1).collect(Collectors.toList());
5)并行Stream
并行流就是把一个内容分成多个数据块,并用不同的线程分成多个数据块,并用不同的线程分别处理每个数据块的流。
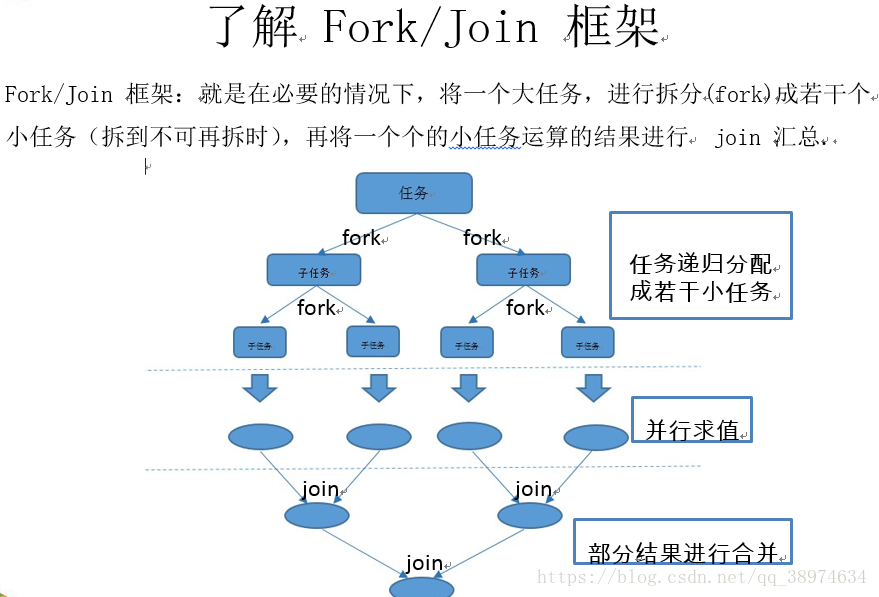
JAVA8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。Stream API 可以声明性地通过parallel() 与sequential() 在并行流与顺序流之间进行切换。其实JAVA8底层是使用JAVA7新加入的Fork/Join框架:
Fork/Join框架与传统线程池的区别:
采用“工作窃取”模式(work-stealing):当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上.在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态.而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行.那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行.这种方式减少了线程的等待时间,提高了性能.
3.3 Date/Time API(JSR 310)
Java 8引入了新的Date-Time API(JSR 310)来改进时间、日期的处理。时间和日期的管理一直是最令Java开发者痛苦的问题。java.util.Date和后来的java.util.Calendar一直没有解决这个问题(甚至令开发者更加迷茫)。
因为上面这些原因,诞生了第三方库Joda-Time,可以替代Java的时间管理API。Java 8中新的时间和日期管理API深受Joda-Time影响,并吸收了很多Joda-Time的精华。新的java.time包包含了所有关于日期、时间、时区、Instant(跟日期类似但是精确到纳秒)、duration(持续时间)和时钟操作的类。新设计的API认真考虑了这些类的不变性(从java.util.Calendar吸取的教训),如果某个实例需要修改,则返回一个新的对象。
3.4 Nashorn JavaScript引擎
Java 8提供了新的Nashorn JavaScript引擎,使得我们可以在JVM上开发和运行JS应用。Nashorn JavaScript引擎是javax.script.ScriptEngine的另一个实现版本,这类Script引擎遵循相同的规则,允许Java和JavaScript交互使用
举个例子:
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName( "JavaScript" );
System.out.println( engine.getClass().getName() );
System.out.println( "Result:" + engine.eval( "function f() { return 1; }; f() + 1;" ) );
输出结果:
Result: 2
3.5 Base64
新的Base64API也支持URL和MINE的编码解码。
(Base64.getUrlEncoder() / Base64.getUrlDecoder(), Base64.getMimeEncoder() / Base64.getMimeDecoder())。
BASE64不是用来加密的,是BASE64编码后的字符串,全部都是由标准键盘上面的常规字符组成,这样编码后的字符串在网关之间传递不会产生UNICODE字符串不能识别或者丢失的现象。你再仔细研究下EMAIL就会发现其实EMAIL就是用base64编码过后再发送的。然后接收的时候再还原。
3.6 并行数组
Java8版本新增了很多新的方法,用于支持并行数组处理。最重要的方法是parallelSort(),可以显著加快多核机器上的数组排序
举个例子:
long[] arrayOfLong = new long [ 20000 ];
Arrays.parallelSetAll( arrayOfLong,
index -> ThreadLocalRandom.current().nextInt( 1000000 ) );
Arrays.stream( arrayOfLong ).limit( 10 ).forEach(
i -> System.out.print( i + " " ) );
System.out.println();
3.7 并发行
基于新增的lambda表达式和steam特性,为Java 8中为java.util.concurrent.ConcurrentHashMap类添加了新的方法来支持聚焦操作;另外,也为java.util.concurrentForkJoinPool类添加了新的方法来支持通用线程池操作(更多内容可以参考我们的并发编程课程)。
Java 8还添加了新的java.util.concurrent.locks.StampedLock类,用于支持基于容量的锁——该锁有三个模型用于支持读写操作(可以把这个锁当做是java.util.concurrent.locks.ReadWriteLock的替代者)。
在java.util.concurrent.atomic包中也新增了不少工具类,列举如下:
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
四、新的java工具
五、JVM新特性
使用Metaspace(JEP 122)代替持久代(PermGen space)。在JVM参数方面,使用-XX:MetaSpaceSize和-XX:MaxMetaspaceSize代替原来的-XX:PermSize和-XX:MaxPermSize。