一、使用Docker-compose实现Tomcat+Nginx负载均衡
- 反向代理原理,这是在知乎上找的一个答案,比较容易理解。反向代理为何叫反向代理?
- 接下来内容部分参考博客Docker-Compose部署nginx代理Tomcat集群和Nginx服务器之负载均衡策略
- 这是文件的结构
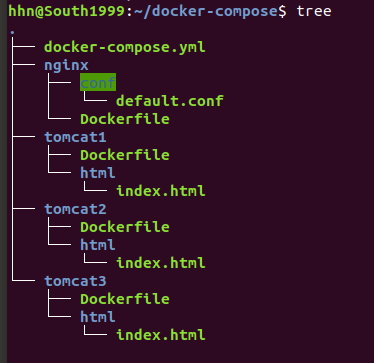
nginx
#Dockerfile
FROM nginx:latest
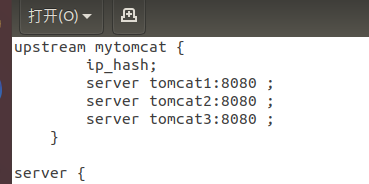
#default.conf
upstream mytomcat {
ip_hash;
server tomcat1:8080 ;
server tomcat2:8080 ;
server tomcat3:8080 ;
}
server {
listen 4396;
server_name localhost;
location / {
index index.jsp index.html;
proxy_pass http://mytomcat;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /var/www/html;
}
}
tomcat(三个只有html内容不同)
#Dockerfile
FROM tomcat:latest
#index.html
Welcome to tomcat-1 server.
yml文件
version: "3"
services:
nginx:
build: ./nginx
ports:
- "80:4396"
links:
- tomcat1:tomcat1
- tomcat2:tomcat2
- tomcat3:tomcat3
volumes:
- ./nginx/conf/default.conf:/etc/nginx/conf.d/default.conf
depends_on:
- tomcat1
- tomcat2
- tomcat3
tomcat1:
build: ./tomcat1
hostname: tomcat1
volumes:
- ./tomcat1/html:/usr/local/tomcat/webapps/ROOT
tomcat2:
build: ./tomcat2
hostname: tomcat2
volumes:
- ./tomcat2/html:/usr/local/tomcat/webapps/ROOT
tomcat3:
build: ./tomcat3
hostname: tomcat3
volumes:
- ./tomcat3/html:/usr/local/tomcat/webapps/ROOT
- 接下来编写一个简单的python程序去测试。
import requests
url = 'http://localhost'
for i in range(20):
res = requests.get(url)
print(res.text)
-
默认的方式就是轮询,如图为测试结果,按着顺序的1,2,3.

-
接下来,我给三个服务器赋予不同的权值,default.conf文件修改如下,结果如图,tomcat3出现12次,tomcat2出现6次,tomcat1出现2次,是符合我们设置的权值,而且这个概率应该是一个伪概率,如果十次访问为一轮的话可以发现第一轮和第二轮顺序和次数完全相同。


-
最后试一下ip_hash方式,但是这个不容易测试。

二、使用Docker-compose部署javaweb运行环境
-
javaweb就选择同学推荐的SpringBoot,方法参考了已经成功的同学的博客。
-
参考博客
-
首先准备好所需要的全部镜像。
-
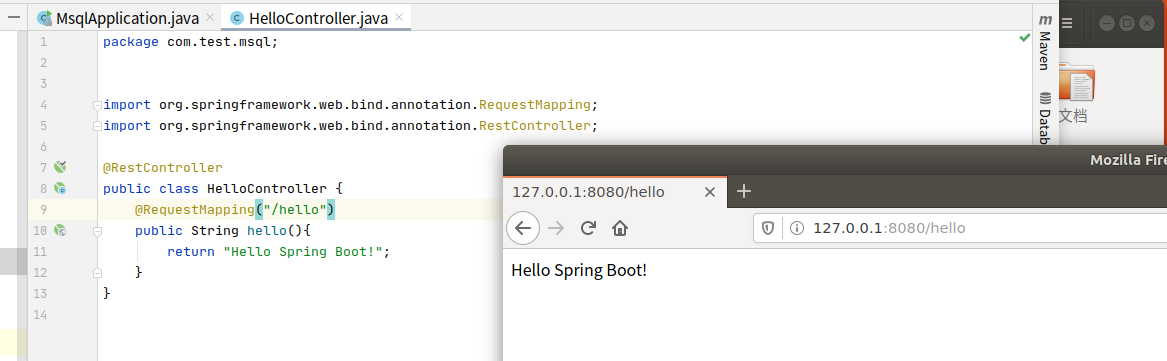
安装IDEA,测试SpringBoot,如图表示可用。
-
文件所有文件结构
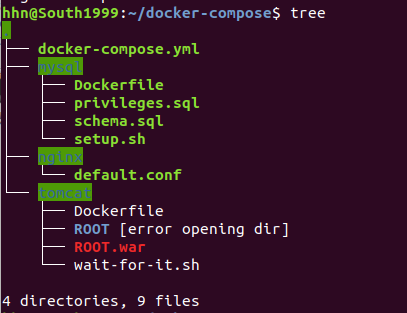
mysql配置
//Dockerfile
#基础镜像
FROM mysql:5.7
#将所需文件放到容器中
COPY setup.sh /mysql/setup.sh
COPY schema.sql /mysql/schema.sql
COPY privileges.sql /mysql/privileges.sql
#设置容器启动时执行的命令
CMD ["sh", "/mysql/setup.sh"]
//privileges.sql 权限配置,确保可以访问到数据库
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
flush privileges;
//schema.sql 创建一个数据库,表,并且插入一条数据
-- 创建数据库
create database `docker_mysql` default character set utf8 collate utf8_general_ci;
use docker_mysql;
-- 建表
DROP TABLE IF EXISTS user;
CREATE TABLE user (
`id` int NOT NULL,
`name` varchar(40) DEFAULT NULL,
`major` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- 插入数据
INSERT INTO user (`id`, `name`, `major`)
VALUES
(111700312,'Haonan Hu','computer science');
//setup.sh 启动脚本,负责执行数据库语句
#!/bin/bash
set -e
#查看mysql服务的状态,方便调试,这条语句可以删除
echo `service mysql status`
//setup.sh
echo '1.启动mysql....'
#启动mysql
service mysql start
sleep 3
echo `service mysql status`
echo '2.开始导入数据....'
#导入数据
mysql < /mysql/schema.sql
echo '3.导入数据完毕....'
sleep 3
mysql < /mysql/privileges.sql
echo `service mysql status`
#sleep 3
echo `service mysql status`
echo `mysql容器启动完毕,且数据导入成功`
tail -f /dev/null
tomcat配置
//Dockerfile wait-for-it.sh是参考同学的做法,这个可以到github上找到
FROM tomcat
COPY ./wait-for-it.sh /usr/local/tomcat/bin/
RUN chmod +x /usr/local/tomcat/bin/wait-for-it.sh
CMD ["wait-for-it.sh", "cdb:3306", "--", "catalina.sh", "run"]
yml文件
version: '3'
services:
#tomcat setting
tomcat1:
container_name: web_tomcat1
build: ./tomcat
#volumes path|host path:container path
volumes:
- ./tomcat:/usr/local/tomcat/webapps
#connect to another container
links:
- mysql
depends_on:
- mysql
restart: always
tomcat2:
container_name: web_tomcat2
build: ./tomcat
#volumes path|host path:container path
volumes:
- ./tomcat:/usr/local/tomcat/webapps
#connect to another container
links:
- mysql
depends_on:
- mysql
restart: always
tomcat3:
container_name: web_tomcat3
build: ./tomcat
#volumes path|host path:container path
volumes:
- ./tomcat:/usr/local/tomcat/webapps
#connect to another container
links:
- mysql
depends_on:
- mysql
restart: always
#mysql setting
mysql:
container_name: web_mysql
build: ./mysql
ports:
- "3306:3306"
environment:
#Initialize the root password
MYSQL_ROOT_PASSWORD: 123456
#nginx setting
nginx:
container_name: web_nginx
image: nginx:latest
ports:
- 80:4396
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf
restart: always
depends_on:
- tomcat1
- tomcat2
- tomcat3
JavaWeb主要内容
package com.test.mysql;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
import javax.servlet.http.HttpServletRequest;
@Controller
@RequestMapping(path = "/do")
public class MysqlController {
@Autowired
UserRepository userRepository;
@PostMapping(path = "/insert")
public @ResponseBody
String AddUser(@RequestParam Integer id,@RequestParam String name, @RequestParam String major) {
User stu = new User();
stu.setName(name);
stu.setMajor(major);
stu.setId(id);
stu = userRepository.save(stu);
return "保存成功. 用户的id是 " + stu.getId();
}
@PostMapping(path = "/update")
public @ResponseBody
String UpdateUser(@RequestParam Integer id, @RequestParam String name, @RequestParam String major) {
User stu = userRepository.findById(id).orElse(null);
if (stu != null) {
stu.setName(name);
stu.setMajor(major);
userRepository.save(stu);
return "更新成功";
} else {
return "用户不存在";
}
}
@PostMapping(path = "/delete")
public @ResponseBody
String DeleteUser(@RequestParam Integer id) {
if (userRepository.findById(id).orElse(null) != null) {
userRepository.deleteById(id);
return "指定用户已被删除";
} else {
return "用户不存在";
}
}
@GetMapping(path = "/select")
public @ResponseBody
Iterable<User> SelectAllUsers() {
return userRepository.findAll();
}
@GetMapping(path = "/server")
public @ResponseBody
String getPort(HttpServletRequest request) {
return "本次服务器地址 " + request.getLocalAddr();
}
}
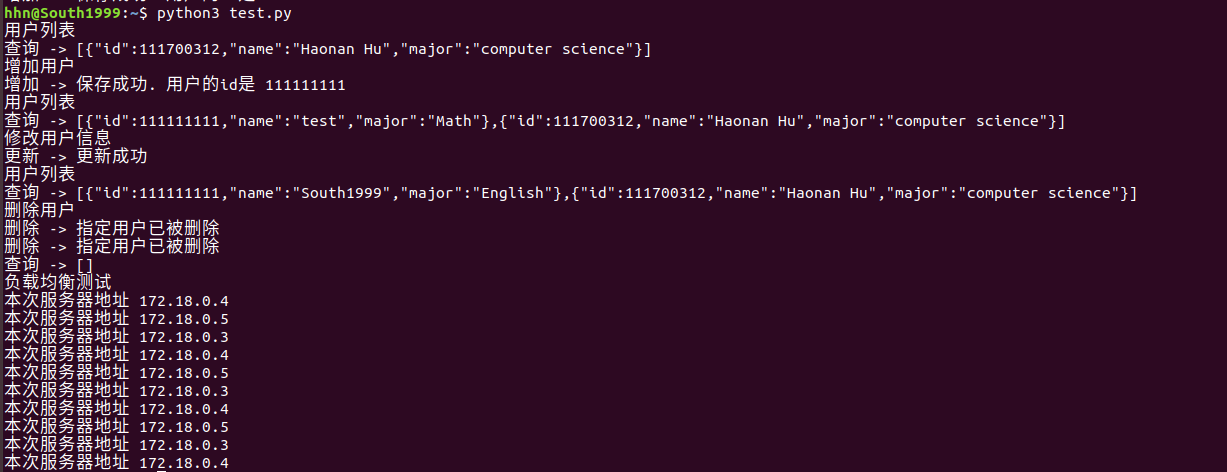
- 在编写测试程序之前,我先做了个小测试,如图,访问成功,证明实验成功了,之后可编写测试程序

python测试程序
import requests
#初始数据库已经创建,并且表也已经创建,并且插入了一项我的数据。
print("用户列表")
#查询所有用户
url = "http://localhost/do/select"
res = requests.get(url)
print("查询 -> " + res.text)
print("增加用户")
#增加用户
url = "http://localhost/do/insert"
data = {"id":111111111,"name":"test", "major":"Math"}
res = requests.post(url=url,data=data)
print("增加 -> " + res.text)
print("用户列表")
#查询所有用户
url = "http://localhost/do/select"
res = requests.get(url)
print("查询 -> " + res.text)
print("修改用户信息")
#修改用户信息
url = "http://localhost/do/update"
data = {"id":111111111, "name":"South1999", "major":"English"}
res = requests.post(url=url,data=data)
print("更新 -> " + res.text)
print("用户列表")
#查询所有用户
url = "http://localhost/do/select"
res = requests.get(url)
print("查询 -> " + res.text)
print("删除用户")
# 删除用户
url = "http://localhost/do/delete"
data = {"id":111111111}
res = requests.post(url=url,data=data)
print("删除 -> " + res.text)
url = "http://localhost/do/delete"
data = {"id":111700312}
res = requests.post(url=url,data=data)
print("删除 -> " + res.text)
#查询所有用户
url = "http://localhost/do/select"
res = requests.get(url)
print("查询 -> " + res.text)
print("负载均衡测试")
# 负载均衡测试
url = 'http://localhost/do/server'
for i in range(0,10):
res = requests.get(url)
print(res.text)
- 测试结果,基本的数据库操作增删改查都进行了测试,最后是负载均衡测试,策略就是默认的轮询
三、使用Docker搭建大数据集群环境
- 首先准备好需要的ubuntu镜像
- 使用Dockerfile创建一个自定义的镜像,这步主要是把源直接换了,在容器内下载速度会更快。
//Dockerfile
FROM ubuntu
COPY ./sources.list /etc/apt/sources.list
//sources.list
# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
- 然后运行容器
sudo docker run -it -v /home/hadoop/build:/root/build --name ubuntu ubuntu

- 接下来安装一些工具,方便之后使用
apt-get update
apt-get install vim
apt-get install ssh
- 开启sshd服务并且设置为自动开启
/etc/init.d/ssh start
vim ~/.bashrc #在文件内末尾加入上一行内容
- 设置sshd免密登录,如果没有.ssh文件夹就用命令ssh localhost登录一次就有这个文件夹了。
cd ~/.ssh
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
- 由于版本问题,安装jdk8而不是默认的。
apt-get install openjdk-8-jdk
- 配置一下JAVA的环境
vim ~/.bashrc #把下面两行加入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
export PATH=$PATH:$JAVA_HOME/bin
- 使配置生效
source ~/.bashrc
- 保存好镜像文件,如图可以看到已经保存好ubuntu-4.3
sudo docker ps #查看容器id
sudo docker commit [容器id] 镜像名字
- 接下来准备安装hadoop(推荐清华源)hadoop-3.2.1下载地址,把下载好的包放在挂载的目录中。
docker run -it -v /home/hadoop/build:/root/build --name ubuntu-4.3 ubuntu-4.3
- 解压hadoop的安装包并且去验证
cd /root/build
tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local
cd /usr/local/hadoop-3.2.1
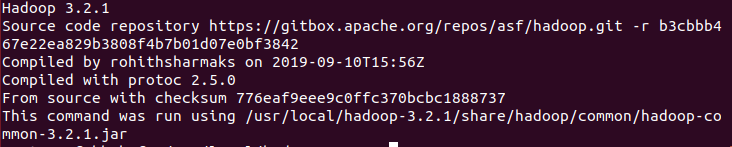
./bin/hadoop version
-
如图表示安装成功,会显示出版本号
-
接下来开始配置集群
cd /usr/local/hadoop-3.2.1/etc/hadoop
vim hadoop-env.sh #把下面一行代码加入文件
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
- 修改core-site.xml文件内容
vim core-site.xml #直接覆盖添加下面内容,小贴士,输入:%d可直接清空内容,然后再把修改好的内容直接粘贴就可以
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- 修改hdfs-site.xml文件内容
vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/datanode_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
- 修改mapred-site.xml文件内容
vim mapred-site.xml
<?xml version="1.0" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl" ?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.2.1</value>
</property>
</configuration>
- 修改yarn-site.xml
vim yarn-site.xml
<?xml version="1.0" ?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
-
做完上面的步骤后,我们还是向之前一样存个档,这个就是我们刚才完成的镜像

-
现在开启三个终端,每个终端运行一个容器
# 第一个终端
sudo docker run -it -h master --name master ubuntu/hadoopinstalled
# 第二个终端
sudo docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled
# 第三个终端
sudo docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled
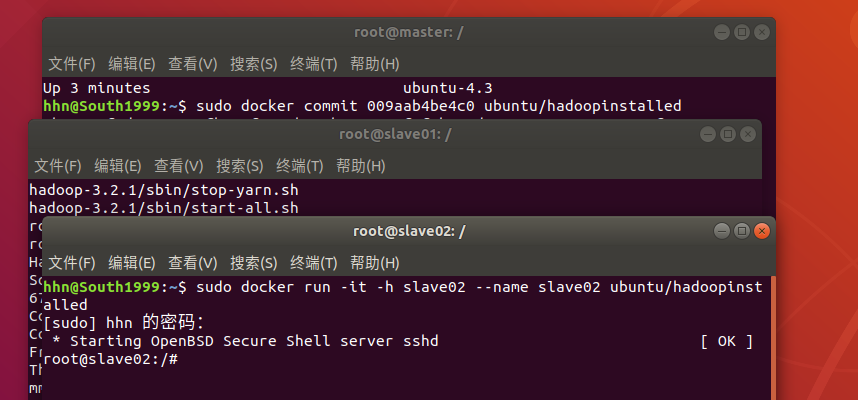
- 修改容器ip地址,并分别配置对方信息,每个都要配置
vim /etc/hosts #加入下列内容,这个根据自己的容器ip改,每个人不是都一样
172.17.0.2 master
172.17.0.3 slave01
172.17.0.4 slave02
- 修改works配置文件,这个和给出的资料不一样,资料可能版本比较老,在大数据的实验课做过这个。

vim /usr/local/hadoop-3.2.1/etc/hadoop/workers
#见下面的复制进去
slave01
slave02
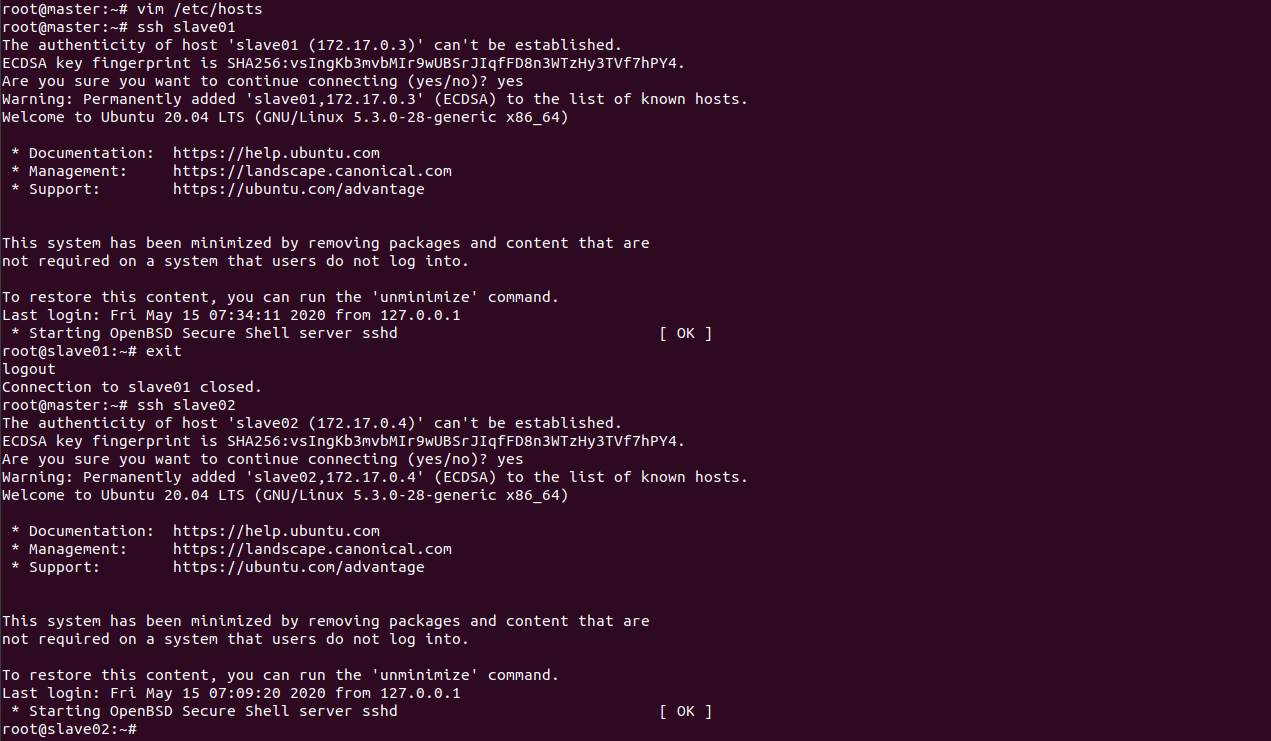
- 在master中,执行以下命令,报错请见---使用root配置的hadoop并启动会出现报错
cd /usr/local/hadoop-3.2.1
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
-
这一步不知道什么问题,我一直开启不了namenode,显示端口9000拒绝访问,重新构建容器了三四次都不行,遂放弃。之后换回了之前做大数据实验的虚拟机再次尝试,用hadoop-3.1.3版本配置成功了。这个可能是虚拟机的问题吧。如图分别是master和slave节点的开启服务状态
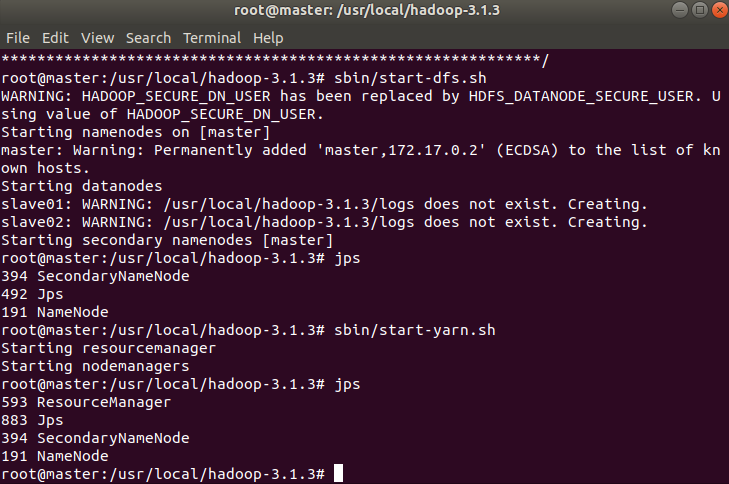
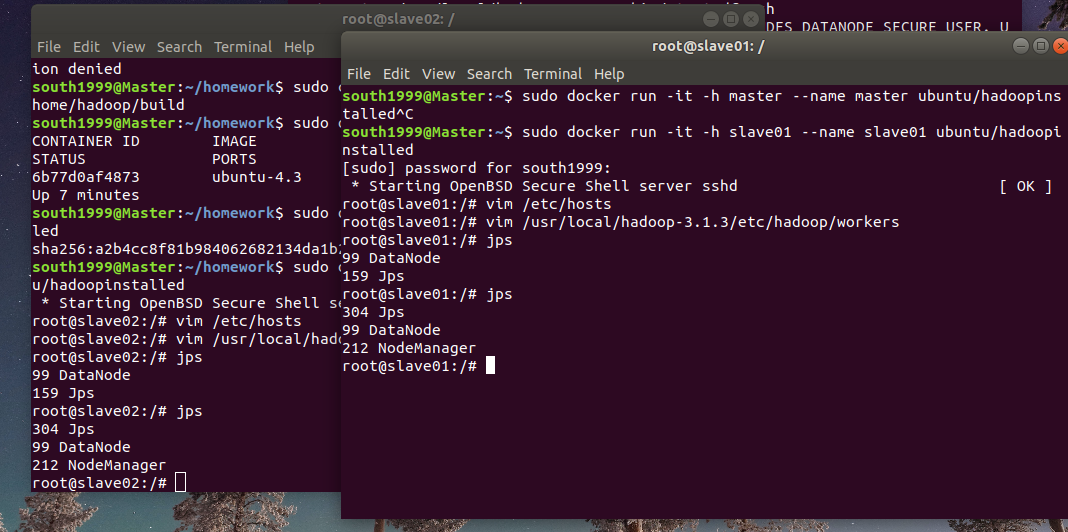
-
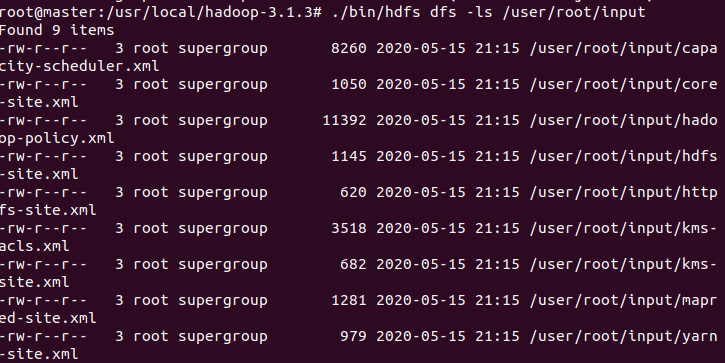
接下来我们将hadoop内的一些文件放入hdfs上的input文件夹,如图是input文件夹里的文件
./bin/hdfs dfs -mkdir -p /user/root/input
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/root/input
./bin/hdfs dfs -ls /user/root/input
- 执行指定的用程序,这个在大数据实验也做过,查找文件内符合正则表达式的字符串,最后Bytes Written不为0代表有输出。
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'
./bin/hdfs dfs -cat output/*

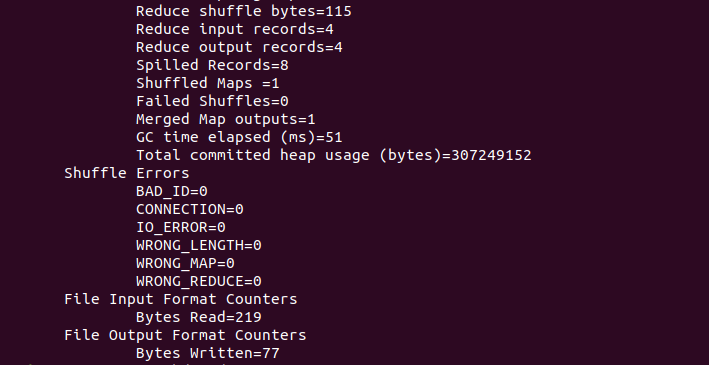
- 最终输出

问题&解决方法
-
Q:在负载均衡策略中选择权重方式时,无法连接了。
- A:写权重时比如weight=1,不能有多余的空格,比如说不能写成weight = 1,这在一般的编程里是行得通的,但是在nginx的配置里不能这样子写。
-
Q:运行dfs-start.sh报错怎么办?
- A:使用root配置的hadoop并启动会出现报错,直接在虚拟机中运行倒好像不需要这样配置。
-
Q:最后运行jar包中的程序时,运行失败或者死机怎么办?
- A:多给虚拟机一些内存,虚拟机内少开程序。我给了2G一直卡死在运行,3G就可以跑了。或者在配置文件有相关设置。
-
Q:为什么master主机访问slave被拒绝?
- A:配置hosts的时候每个人的ip都不一定一样,所以要根据自己的配。我第一次见就是直接配成参考博客中的

- A:配置hosts的时候每个人的ip都不一定一样,所以要根据自己的配。我第一次见就是直接配成参考博客中的
-
Q:IDEA中maven插件报错
- A:找到错误的地方,也就是红线,对应上面Lifecycle中的内容,单击右键,点Run Maven Build即可,如图clean是已经更新好的。IDEA功能确实强,很方便使用。
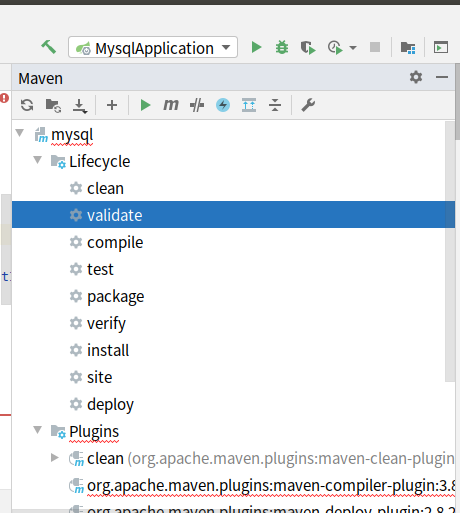
- A:找到错误的地方,也就是红线,对应上面Lifecycle中的内容,单击右键,点Run Maven Build即可,如图clean是已经更新好的。IDEA功能确实强,很方便使用。
-
第一次配置的容器无法创建namenode,日志中找不出明显错误, dfsadmin -report如下,但是找不到合适的解决方法,换台虚拟机竟然可以做了,还未找出原因。
- report: Call From master/172.17.0.2 to master:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
-
建议每做一部分就用虚拟机的快照功能去保存一下,如果做错了方便恢复到自己需要的步骤,而不需要重新再来,以下是我的快照,用起来很方便。但是快照也很占空间,一个快照都有好几个G。

时间
完成实验+写博客约18小时。
小结
- 本次实验难度提升了好几个档次,做完之后整个人都升华了,好多地方明明我和教程输入的一样,但是教程能出结果,我显示错误,但是重新做一遍或者换一台虚拟机又能做成了,难顶。难归难,本次实验学到的东西也是最多的,把之前所有的知识涵盖到了,而且又学了反向代理、JavaWeb部署、hadoop简单使用,这次也学到了IDEA的基本用法,功能确实很强大。还需要继续努力学习呀。