传送门
https://blog.csdn.net/jackfrued/article/details/79717727
在此基础上实践和改编某些点
1. 并发编程
- 实现让程序同时执行多个任务也就是常说的“并发编程”
- 使用Python实现并发编程主要有3种方式:多进程、多线程、多进程+多线程。
- 进程间通信必须通过进程间通信机制(IPC,Inter-Process Communication)来实现数据共享,具体的方式包括管道、信号、套接字、共享内存区等。
2. Python的多进程
Unix和Linux操作系统上提供了fork()系统调用来创建进程,调用fork()函数的是父进程,创建出的是子进程,子进程是父进程的一个拷贝,但是子进程拥有自己的PID。fork()函数非常特殊它会返回两次,父进程中可以通过fork()函数的返回值得到子进程的PID,而子进程中的返回值永远都是0。Python的os模块提供了fork()函数。由于Windows系统没有fork()调用,因此要实现跨平台的多进程编程,可以使用multiprocessing模块的Process类来创建子进程,而且该模块还提供了更高级的封装,例如批量启动进程的进程池(Pool)、用于进程间通信的队列(Queue)和管道(Pipe)等。
2.1 模拟下载文件 - 单进程单线程
from random import randint
from time import time, sleep
def download_task(filename):
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
download_task('文件A.pdf')
download_task('文件B')
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
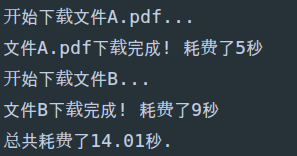
没有效率,一个文件下载完,另一个文件才下载
2.2 模拟下载文件 - 把下载任务分别放到两个进程中(多进程)
from multiprocessing import Process
from os import getpid
from random import randint
from time import time, sleep
def download_task(filename):
print('启动下载进程,进程号[%d].' % getpid())
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
p1 = Process(target=download_task, args=('文件A.pdf', ))
p1.start()
p2 = Process(target=download_task, args=('文件B.avi', ))
p2.start()
# 主程序主线程等待子进程p1, p2完成再继续执行
p1.join()
p2.join()
end = time()
print('总共耗费了%.2f秒.' % (end - start))
if __name__ == '__main__':
main()
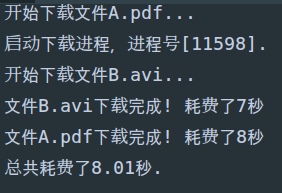
另外,也可以使用subprocess模块中的类和函数来创建和启动子进程,然后通过管道来和子进程通信。
2.3 数Ping,Pong问题
启动两个进程,一个输出Ping,一个输出Pong,两个进程输出的Ping和Pong加起来一共10个。
from multiprocessing import Process
from time import sleep
counter = 0
def sub_task(string):
global counter
while counter < 10:
print(string, end='', flush=True)
counter += 1
sleep(0.01)
def main():
Process(target=sub_task, args=('Ping', )).start()
Process(target=sub_task, args=('Pong', )).start()
if __name__ == '__main__':
main()
问题: 但是输出Ping和Pong各十个。因为当我们在程序中创建进程的时候,子进程复制了父进程及其所有的数据结构,每个子进程有自己独立的内存空间,这也就意味着两个子进程中各有一个counter变量。
2.4 解决数Ping,Pong问题
解决这个问题比较简单的办法是使用multiprocessing模块中的Queue类,它是可以被多个进程共享的队列,底层是通过管道和信号量(semaphore)机制来实现的
from multiprocessing import Process, Queue
from time import sleep
# 主进程主线程的全局变量counter
counter = 0
que = Queue(10)
que.put(counter)
def sub_task(string):
# Python没有do while写法,但是可以用while, break写法代替
while True:
counter = que.get()
if counter == 10:
break
print(string, end='
', flush=True)
counter += 1
que.put(counter)
sleep(0.01)
def main():
# 子进程1
Process(target=sub_task, args=('Ping', )).start()
# 子进程2
Process(target=sub_task, args=('Pong', )).start()
if __name__ == '__main__':
main()
3. Python的多线程
在Python早期的版本中就引入了thread模块(现在名为_thread)来实现多线程编程,然而该模块过于底层,而且很多功能都没有提供,因此目前的多线程开发我们推荐使用threading模块,该模块对多线程编程提供了更好的面向对象的封装。
3.1 模拟下载文件 - 多线程
from random import randint
from threading import Thread
from time import time, sleep
def download(filename):
print('开始下载%s...' % filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('%s下载完成! 耗费了%d秒' % (filename, time_to_download))
def main():
start = time()
t1 = Thread(target=download, args=('文件A.pdf',))
t1.start()
t2 = Thread(target=download, args=('文件B.avi',))
t2.start()
t1.join()
t2.join()
end = time()
print('总共耗费了%.3f秒' % (end - start))
if __name__ == '__main__':
main()

3.2 自定义线程
也可以通过继承Thread类的方式来创建自定义的线程类,然后再创建线程对象并启动线程。
from threading import Thread
from random import randint
from time import time, sleep
### 继承Thread, 自定义线程
class DownloadTask(Thread):
def __init__(self, filename):
super().__init__()
self._filename = filename
def run(self):
print('开始下载%s...' % self._filename)
time_to_download = randint(5, 10)
sleep(time_to_download)
print('{filename}下载完成! 耗费了{second}秒'.format(filename=self._filename,
second=time_to_download))
def main():
start = time()
t1 = DownloadTask('文件A')
t2 = DownloadTask('文件B')
t1.start()
t2.start()
t1.join()
t2.join()
end = time()
print('总共耗费了{:.2f}秒'.format((end - start)))
if __name__ == '__main__':
main()
3.3 100个人向account转1块 - 没有保护临界资源
from time import sleep
from threading import Thread
class Account(object):
def __init__(self):
self._balance = 0
def deposit(self, money):
# 计算存款后的余额
new_balance = self._balance + money
# 模拟受理存款业务需要0.01秒的时间
sleep(0.01)
# 修改账户余额
self._balance = new_balance
@property
def balance(self):
return self._balance
class AddMoneyThread(Thread):
def __init__(self, account, money):
super().__init__()
self._account = account
self._money = money
def run(self):
self._account.deposit(self._money)
def main():
account = Account()
threads = []
# 创建100个存款的线程向同一个账户中存钱
for _ in range(100):
t = AddMoneyThread(account, 1)
threads.append(t)
t.start()
# 等所有存款的线程都执行完毕
for t in threads:
t.join()
print('账户余额为: ¥%d元' % account.balance)
if __name__ == '__main__':
main()
结果远小于100, 因为没有对account的balance这个临界资源保护;多个线程同时向账户中存钱时,会一起执行到new_balance = self._balance + money这行代码,多个线程得到的账户余额都是初始状态下的0,所以都是0上面做了+1的操作,因此得到了错误的结果。
3.4 100个人向account转1块 - 加锁保护临界资源
from time import sleep
from threading import Thread, Lock
class Account(object):
def __init__(self):
self._balance = 0
self._lock = Lock()
def deposit(self, money):
# 先获取锁才能执行后续的代码
self._lock.acquire()
try:
new_balance = self._balance + money
sleep(0.01)
self._balance = new_balance
finally:
# 在finally中执行释放锁的操作保证正常异常锁都能释放
self._lock.release()
@property
def balance(self):
return self._balance
class AddMoneyThread(Thread):
def __init__(self, account, money):
super().__init__()
self._account = account
self._money = money
def run(self):
# 线程要完成的任务
self._account.deposit(self._money)
def main():
account = Account()
# 用列表保存线程,用于遍历去join
threads = []
for _ in range(100):
t = AddMoneyThread(account, 1)
threads.append(t)
t.start()
# 等待所有线程完成,主线程才继续执行下去
for t in threads:
t.join()
print('账户余额为: ¥%d元' % account.balance)
if __name__ == '__main__':
main()

比较遗憾的一件事情是Python的多线程并不能发挥CPU的多核特性,这一点只要启动几个执行死循环的线程就可以得到证实了。之所以如此,是因为Python的解释器有一个“全局解释器锁”(GIL)的东西,任何线程执行前必须先获得GIL锁,然后每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行,这是一个历史遗留问题,但是即便如此,就如我们之前举的例子,使用多线程在提升执行效率和改善用户体验方面仍然是有积极意义的。
4. 单线程+异步I/O
现代操作系统对I/O操作的改进中最为重要的就是支持异步I/O。如果充分利用操作系统提供的异步I/O支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型。Nginx就是支持异步I/O的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。用Node.js开发的服务器端程序也使用了这种工作模式,这也是当下实现多任务编程的一种趋势。
在Python语言中,单线程+异步I/O的编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。协程最大的优势就是极高的执行效率,因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销。协程的第二个优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不用加锁,只需要判断状态就好了,所以执行效率比多线程高很多。如果想要充分利用CPU的多核特性,最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
5. 应用案例
5.1 例子1:将耗时间的任务放到线程中以获得更好的用户体验。
如下所示的界面中,有“下载”和“关于”两个按钮,用休眠的方式模拟点击“下载”按钮会联网下载文件需要耗费10秒的时间,如果不使用“多线程”,我们会发现,当点击“下载”按钮后整个程序的其他部分都被这个耗时间的任务阻塞而无法执行了,这显然是非常糟糕的用户体验,代码如下所示。
import time
import tkinter
import tkinter.messagebox
def download():
# 模拟下载任务需要花费2秒钟时间
time.sleep(2)
tkinter.messagebox.showinfo('提示', '下载完成!')
def show_about():
tkinter.messagebox.showinfo('关于', 'Nothing here')
def main():
top = tkinter.Tk()
top.title('单线程')
top.geometry('500x500')
top.wm_attributes('-topmost', True)
panel = tkinter.Frame(top)
button1 = tkinter.Button(panel, text='下载', command=download)
button1.pack(side='left')
button2 = tkinter.Button(panel, text='关于', command=show_about)
button2.pack(side='right')
panel.pack(side='bottom')
tkinter.mainloop()
if __name__ == '__main__':
main()
这里只有一个线程(主线程)。如果点击”下载“,下载任务会在主线程中执行,主线程其他代码无法执行,所以会造成阻塞现象。解决办法:把下载任务放在后台(另外一个线程)。让主线程执行其他任务(run the main loop,监听事件)。当事件发生,另起一个线程处理事情。
import time
import tkinter
import tkinter.messagebox
from threading import Thread
def main():
class DownloadTaskHandler(Thread):
def run(self):
time.sleep(2)
tkinter.messagebox.showinfo('提示', '下载完成!')
# 启用下载按钮
button1.config(state=tkinter.NORMAL)
def download():
# 禁用下载按钮
button1.config(state=tkinter.DISABLED)
# 通过daemon参数将线程设置为守护线程(主程序退出就不再保留执行)
# 在线程中处理耗时间的下载任务
DownloadTaskHandler(daemon=True).start()
def show_about():
tkinter.messagebox.showinfo('关于', 'Nothing here')
top = tkinter.Tk()
top.title('单线程')
top.geometry('500x500')
top.wm_attributes('-topmost', 1)
panel = tkinter.Frame(top)
button1 = tkinter.Button(panel, text='下载', command=download)
button1.pack(side='left')
button2 = tkinter.Button(panel, text='关于', command=show_about)
button2.pack(side='right')
panel.pack(side='bottom')
tkinter.mainloop()
if __name__ == '__main__':
main()
5.2 上面多线程例子的总结
如果使用多线程将耗时间的任务放到一个独立的线程中执行,这样就不会因为执行耗时间的任务而阻塞了主线程。虽然CPython中有GIL,在同一时刻内,把多线程限制在单核上面(有一个现象:在windows或linux平台上,创建多线程,每个cpu都会被使用,而且总cpu的使用率在50%,应该是由于系统调度),因为GIL是锁了Python解释器,只有获得GIL锁,CPU才能运行指令。虽说如此,多线程能提高用户体验(处理某个任务时表现为不阻塞,实际上CPU还是在一个时刻调度一个线程)。
5.3 使用多进程对复杂任务进行“分而治之”。
来完成1~100000000求和的计算密集型任务
from time import time
def main():
total = 0
number_list = [x for x in range(1, 100000001)]
start = time()
for number in number_list:
total += number
print(total)
end = time()
print('Execution time: %.3fs' % (end - start))
if __name__ == '__main__':
main()
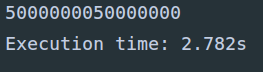
将这个任务分解到8个进程中去执行的时候,我们暂时也不考虑列表切片操作花费的时间,只是把做运算和合并运算结果的时间统计出来
from multiprocessing import Process, Queue
from random import randint
from time import time
def task_handler(curr_list, result_queue):
total = 0
for number in curr_list:
total += number
result_queue.put(total)
def main():
processes = []
number_list = [x for x in range(1, 100000001)]
result_queue = Queue()
index = 0
# 启动8个进程将数据切片后进行运算
for _ in range(8):
p = Process(target=task_handler,
args=(number_list[index:index + 12500000], result_queue))
index += 12500000
processes.append(p)
p.start()
# 开始记录所有进程执行完成花费的时间
start = time()
for p in processes:
p.join()
# 合并执行结果
total = 0
while not result_queue.empty():
total += result_queue.get()
print(total)
end = time()
print('Execution time: ', (end - start), 's', sep='')
if __name__ == '__main__':
main()

再强调一次只是比较了运算的时间,不考虑列表创建及切片操作花费的时间),使用多进程后由于获得了更多的CPU执行时间以及更好的利用了CPU的多核特性,明显的减少了程序的执行时间,而且计算量越大效果越明显(多进程能解决计算密集型问题)。当然,如果愿意还可以将多个进程部署在不同的计算机上,做成分布式进程,具体的做法就是通过multiprocessing.managers模块中提供的管理器将Queue对象通过网络共享出来(注册到网络上让其他计算机可以访问)