Java集合框架之HashSet浅析
一、HashSet综述:
1.1HashSet简介
-
位于java.util包下的HashSet是Java集合框架的重要成员,它在jdk1.8中定义如下:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
-
HashSet依赖的数据结构是哈希表
-
插入到HashSet中的对象不保证与插入的顺序保持一致。对象的插入是根据它的hashcode
-
HashSet也实现了Searlizable和Cloneable两个接口
-
HashSet 是一个没有重复元素的集合。实现了Set接口,由哈希表(实际上是一个HashMap实例)支持。它不保证set 的迭代顺序(也即不保证元素的顺序);特别是它不保证该顺序恒久不变。它是由HashMap实现的,其次HashSet允许使用 null 元素。
-
HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
- Set s = Collections.synchronizedSet(new HashSet(...));
- HashSet通过iterator()返回的迭代器是fail-fast的。
1.2HashSet数据结构
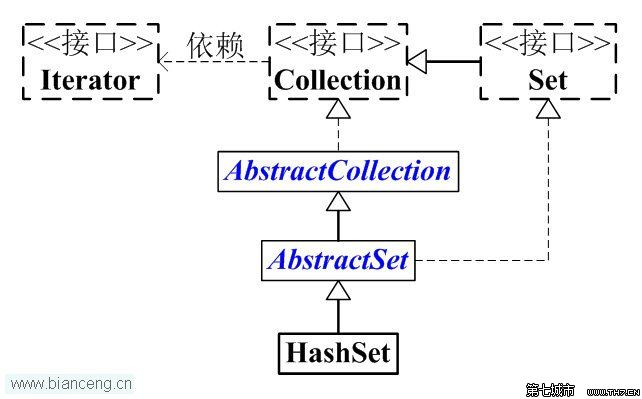
1.3HashSet实现原理:
-
我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
-
当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象
-
如果没有哈希值相同的对象就直接存入集合
-
如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
-
将自定义类的对象存入HashSet去重复
-
类中必须重写hashCode()和equals()方法
-
hashCode(): 属性相同的对象返回值必须相同,属性不同的返回值尽量不同(提高效率)
-
equals(): 属性相同返回true,属性不同返回false,返回false的时候存储
-
- HashSet内部是如何工作的?
- 所有Set接口的类内部都是由Map做支撑的。HashSet用HashMap对它的内部对象进行排序。你一定好奇输入一个值到HashMap,我们需要的是一个键值对,但是我们传给HashSet的是一个值。
- 那么HashMap是如何排序的?
- 实际上我们插入到HashSet中的值在map对象中起的是键的作用,因为它的值Java用了一个常量。所以在键值对中所有的键的值都是一样的。
- HashSet是基于HashMap实现的,默认构造函数是构建一个初始容量为16,负载因子为0.75 的HashMap。封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。
- 当我们试图把某个类的对象当成 HashMap的 key,或试图将这个类的对象放入 HashSet 中保存时,重写该类的equals(Object obj)方法和 hashCode() 方法很重要,而且这两个方法的返回值必须保持一致:当该类的两个对象的hashCode() 返回值相同时,它们通过 equals() 方法比较也应该返回 true。通常来说,所有参与计算 hashCode() 返回值的关键属性,都应该用于作为 equals() 比较的标准。
1.4初始化大小与装载因子:
-
初始化尺寸就是当创建哈希表(HashSet内部用哈希表的数据结构)的时候桶(buckets)的数量。如果当前的尺寸已经满了,那么桶的数量会自动增长。
-
装载因子衡量的是在HashSet自动增长之前允许有多满。当哈希表中实体的数量已经超出装载因子与当前容量的积,那么哈希表就会再次进行哈希(也就是内部数据结构重建),这样哈希表大致有两倍桶的数量。
表中已经存储的元素的数量
装载因子 = -----------------------------------------
哈希表的大小
例如:如果内部容量为16,装载因子为0.75,那么当表中有12个元素的时候,桶的数量就会自动增长。
1.5性能影响:
装载因子和初始化容量是影响HashSet操作的两个主要因素。装载因子为0.75的时候可以提供关于时间和空间复杂度方面更有效的性能。如果我们加大这个装载因子,那么内存的上限就会减小(因为它减少了内部重建的操作),但是将影响哈希表中的add与查询的操作。为了减少再哈希操作,我们应该选择一个合适的初始化大小。如果初始化容量大于实体的最大数量除以装载因子,那么就不会有再哈希的动作发生了
1.6小结:
-
说白了,HashSet就是限制了功能的HashMap,所以了解HashMap的实现原理,这个HashSet自然就通
-
对于HashSet中保存的对象,主要要正确重写equals方法和hashCode方法,以保证放入Set对象的唯一性
-
虽说时Set是对于重复的元素不放入,倒不如直接说是底层的Map直接把原值替代了(这个Set的put方法的返回值真有意思)
-
HashSet没有提供get()方法,愿意是同HashMap一样,Set内部是无序的,只能通过迭代的方式获得
二、HashSet方法摘要:
|
构造方法摘要 | |
|---|---|
|
构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。 |
|
|
构造一个包含指定 collection 中的元素的新 set。 |
|
|
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。 |
|
|
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。 |
|
|
方法摘要 | |
|---|---|
|
|
如果此 set 中尚未包含指定元素,则添加指定元素。 |
|
|
从此 set 中移除所有元素。 |
|
|
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。 |
|
|
如果此 set 包含指定元素,则返回 true。 |
|
|
如果此 set 不包含任何元素,则返回 true。 |
|
|
返回对此 set 中元素进行迭代的迭代器。 |
|
|
如果指定元素存在于此 set 中,则将其移除。 |
|
|
返回此 set 中的元素的数量(set 的容量)。 |
参考文章:
https://www.jianshu.com/p/a9c997d4c6d8
http://www.jb51.net/article/113439.htm
http://blog.csdn.net/sinat_36246371/article/details/53366104