Hibernate相当于对JDBC做了一层封装。
ORM:对象关系映射,更加方便的处理模型数据。一套标准的,简单的,易于被传递的,关于对象和关系的映射。
JDBC的缺点:
- 开发效率低
- 重复性工作多
- 代码冗余(pstmt的setXX方法,方法参数冗余的getXX()方法,如果POJO的属性很多,代码增加)
Hibernate
一个开源的对象关系映射框架
对JDBC进行了非常轻量级的对象封装
将JavaBean对象和数据库的表建立对应关系。
Hiberntate的优势
Hibernate是一个优秀的Java持久化层解决方案。
是当今主流的对象——关系映射工具。
Hibernate简化了JDBC繁琐的编码。
Hibernate将数据库的连接信息都存放在配置文件中。
持久化
将程序中数据在瞬时状态和持久状态间转换的机制。
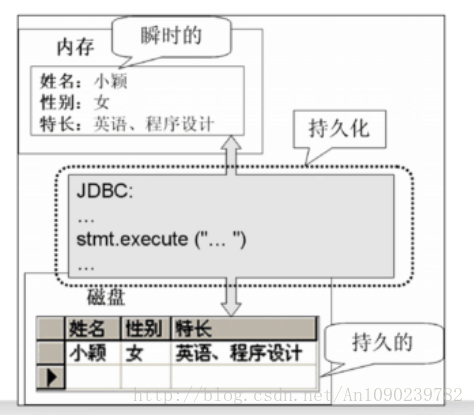
持久化层
JDBC就是一种持久化机制
将程序数据直接保存成文本文件也是持久化机制的一种实现。
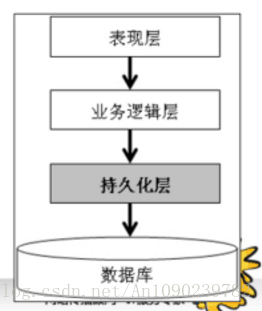
在分层结构中,DAO层(数据访问层)也被称为持久化层。
持久化完成的操作
将对象保存到关系型数据库中,
将关系型数据库中的数据读取出来以对象的形式封装。
ORM(对象关系映射)
ORM(Object Relational Mapping),对象关系映射。
- 编写程序的时候,以面向对象的方式处理数据。
- 保存数据的时候,却以关系型数据库的方式存储。
ORM解决方案包含下面四个部分:
- 在持久化对象上执行基本增、删、改、查操作的API。
- 用于对持久化对象或属性查询的一种语言或者API.
- 用于实体关系映射的工具。
- 能够与事务对象交互、执行检查、延迟加载以及其他优化功能。
使用Hibernate操作数据库
使用Hibernate操作数据库需要七个步骤
(1)读取并解析配置文件
Configuration conf = new Configuration().configure();
(2)读取并解析映射信息,创建SessionFactory
SessionFactory sf = conf.buildSessionFactory
(3)打开Session
Session session = sf.openSession();
(4)开始一个事物(增删改操作必须,查询操作可选)
Trabsaction tx = session.begin Transaction();
(5)数据库操作
session.save(user);
(6)提交事务
tran.commit();
(7)关闭Session
session.close();
增删改需要开启事物,查询不需要
添加操作:
/* User user = new User();
user.setName("aaa");
user.setPwd("123");
//5.数据库操作
session.save(user);*/
更新数据:
/* User user = new User();
user.setId(3);
user.setName("bbb");
user.setPwd("sss");
session.update(user);*/
删除操作:
/* User user = new User();
user.setId(3);
session.delete(user);*/
查询操作:
User user=(User)session.get(User.class, 2);
System.out.println(user);Hibernate的运行实例
首先,将Jar包导入,lib文件导入根目录下。
然后右键,Build Path 添加进系统虚拟机运行文件之中。

然后,在包com.jredui.entity下,新建一个实体类User;并创建hibernate映射文件(User.hbm.xml)。
– package对应实体类的包 –>
– 每一个实体类对应一个hibernate映射文件 –>
– Mybatis每一个Dao层文件对应一个映射文件 –>
Hibernate的配置文件:

Hibernate.cfg.xml配置文件配置数据库的连接信息等;
- 用于配置数据库连接;
- 运行时所需的各种属性;
- 默认文件名为”hibernate.cfg.xml”
创建Hibernate配置文件

Hibernate查询操作
Hibernate支持两种主要的查询方式
HQL(Hibernate Query Language,Hibernate查询语言)查询;
是一种面向对象的查询语言,其中没有表和字段的概念。,只有类,对象和属性的概念。
HQL是应用较为广泛的方式
Criteria查询
又称为“对象查询”,它用面向对象的方式将构造查询的过程做了封装。
为什么使用HQL?
使用HQL可以避免使用JDBC查询的一些弊端;
- 不需要再编写繁复的SQL语句,针对实体类机器属性进行查询
- 查询结果是直接存放在List中的对象,不需要再次封装。
- 独立于数据库,对不同的数据库根据Hibernate dialect属性的配置自动生成不同的SQL语句执行。

使用HQL需要四步
- 得到Session
- 编写HQL语句
- 创建Query对象(Query接口是HQL查询接口,它提供了各种的查询功能;)
- 执行查询,得到结果
设置别名(alias)
from Street as as === from Street s
s是Street的别名,通过as关键字指定,关键字as是可选的。
Hibernate的基本使用(HQL语句)
HQLTest.java
@Test
public void test() {
//1.编写HQL语句
String hql="from User";
//2.创建Query对象
Query query = session.createQuery(hql);
//3.执行查询,得到结果
List<User> list = query.list();
System.out.println(list);
}where子句、占位符
where子句
where子句指定限定条件:
(通过与SQL相同的比较操作符指定条件)
如:
- =、<>、<、>、>=、<=
- between and、not between and
- in、not in
- is、like
(通过and、or等逻辑连接符组合各个逻辑表达式)
-

占位符
? 占位符
- 使用?作占位符,可以先设定查询参数
- 通过setType()方法设置指定的参数
- 必须保证每个占位符都设置了参数值
- 必须依照?所设定顺序设定
- 下标从0开始,而不是使用PrepareStatement对象时的从1开始

命名参数、封装参数
命名参数
:name即命名参数
标识了一个名为“name”的查询参数
根据此参数进行参数值设定
不需要依照特定的顺序
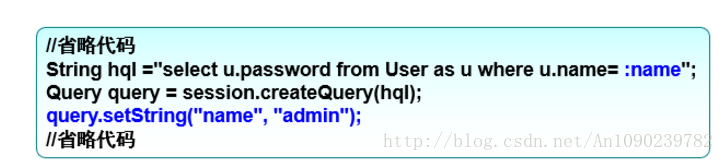
语法:
:参数名字
@Test
public void test2(){
//命名参数,语法 :参数名字
String hql="select u.name from User u where u.id=:id";
Query query = session.createQuery(hql);
query.setParameter("id", 2);
List<User> list=query.list();
System.out.println(list);
}封装参数
- 动态设置查询参数
- 将参数封装为一个bean
@Test
public void test3(){
//封装参数
String hql="select u.name from User u where 1=1";
User user = new User();
user.setId(1);
if(user.getId()>0){
hql+="and id=:id";
}
if(user.getName()!=null){
hql+="and name=:name";
}
Query query=session.createQuery(hql);
//传参
query.setProperties(user);
List<User> list = query.list();
System.out.println(list);
}聚合函数
count():统计函数
max()和min():最大值和最小值函数
avg()和sum():平均值和求和函数

排序:(默认升序:ASC 降序:DESC )
- order by子句实现对查询结果的排序
- 默认情况下按升序顺序排序
- 排序策略(asc升序、desc降序)

分组
- 通过group by子句实现
- 并使用having子句对group by返回的结果集进行筛选

分页、子查询
分页
Query对象提供了简便的分页方法
setFirstResult(int firstResult)方法
设置第一条记录的位置
setMaxResults(int maxResults)方法
设置最大返回的记录条数(pageSize)

子查询:
- ·子查询是SQL中非常重要的功能
- HQL同样支持此机制
- Hibernate子查询必须用圆括号包围且必须出现在where子句中