需求:
利用一个手写数字“先验数据”集,使用knn算法来实现对手写数字的自动识别;
先验数据(训练数据)集:
♦数据维度比较大,样本数比较多。
♦ 数据集包括数字0-9的手写体。
♦每个数字大约有200个样本。
♦每个样本保持在一个txt文件中。
♦手写体图像本身的大小是32x32的二值图,转换到txt文件保存后,内容也是32x32个数字,0或者1,如下:

数据集压缩包解压后有两个目录:(将这两个目录文件夹拷贝的项目路径下E:/KNNCase/digits/)
♦目录trainingDigits存放的是大约2000个训练数据
♦目录testDigits存放大约900个测试数据。
模型分析:
1、手写体因为每个人,甚至每次写的字都不会完全精确一致,所以,识别手写体的关键是“相似度”
2、既然是要求样本之间的相似度,那么,首先需要将样本进行抽象,将每个样本变成一系列特征数据(即特征向量)
3、手写体在直观上就是一个个的图片,而图片是由上述图示中的像素点来描述的,样本的相似度其实就是像素的位置和颜色之间的组合的相似度
4、因此,将图片的像素按照固定顺序读取到一个个的向量中,即可很好地表示手写体样本
5、抽象出了样本向量,及相似度计算模型,即可应用KNN来实现
python实现:
新建一个KNN.py脚本文件,文件里面包含四个函数:
1) 一个用来生成将每个样本的txt文件转换为对应的一个向量,
2) 一个用来加载整个数据集,
3) 一个实现kNN分类算法。
4) 最后就是实现加载、测试的函数。
1 #!/usr/bin/python 2 # coding=utf-8 3 ######################################### 4 # kNN: k Nearest Neighbors 5 6 # 参数: inX: vector to compare to existing dataset (1xN) 7 # dataSet: size m data set of known vectors (NxM) 8 # labels: data set labels (1xM vector) 9 # k: number of neighbors to use for comparison 10 11 # 输出: 多数类 12 ######################################### 13 14 from numpy import * 15 import operator 16 import os 17 18 19 # KNN分类核心方法 20 def kNNClassify(newInput, dataSet, labels, k): 21 numSamples = dataSet.shape[0] # shape[0]代表行数 22 23 # # step 1: 计算欧式距离 24 # tile(A, reps): 将A重复reps次来构造一个矩阵 25 # the following copy numSamples rows for dataSet 26 diff = tile(newInput, (numSamples, 1)) - dataSet # Subtract element-wise 27 squaredDiff = diff ** 2 # squared for the subtract 28 squaredDist = sum(squaredDiff, axis = 1) # sum is performed by row 29 distance = squaredDist ** 0.5 30 31 # # step 2: 对距离排序 32 # argsort()返回排序后的索引 33 sortedDistIndices = argsort(distance) 34 35 classCount = {} # 定义一个空的字典 36 for i in xrange(k): 37 # # step 3: 选择k个最小距离 38 voteLabel = labels[sortedDistIndices[i]] 39 40 # # step 4: 计算类别的出现次数 41 # when the key voteLabel is not in dictionary classCount, get() 42 # will return 0 43 classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 44 45 # # step 5: 返回出现次数最多的类别作为分类结果 46 maxCount = 0 47 for key, value in classCount.items(): 48 if value > maxCount: 49 maxCount = value 50 maxIndex = key 51 52 return maxIndex 53 54 # 将图片转换为向量 55 def img2vector(filename): 56 rows = 32 57 cols = 32 58 imgVector = zeros((1, rows * cols)) 59 fileIn = open(filename) 60 for row in xrange(rows): 61 lineStr = fileIn.readline() 62 for col in xrange(cols): 63 imgVector[0, row * 32 + col] = int(lineStr[col]) 64 65 return imgVector 66 67 # 加载数据集 68 def loadDataSet(): 69 # # step 1: 读取训练数据集 70 print "---Getting training set..." 71 dataSetDir = 'E:/KNNCase/digits/' 72 trainingFileList = os.listdir(dataSetDir + 'trainingDigits') # 加载测试数据 73 numSamples = len(trainingFileList) 74 75 train_x = zeros((numSamples, 1024)) 76 train_y = [] 77 for i in xrange(numSamples): 78 filename = trainingFileList[i] 79 80 # get train_x 81 train_x[i, :] = img2vector(dataSetDir + 'trainingDigits/%s' % filename) 82 83 # get label from file name such as "1_18.txt" 84 label = int(filename.split('_')[0]) # return 1 85 train_y.append(label) 86 87 # # step 2:读取测试数据集 88 print "---Getting testing set..." 89 testingFileList = os.listdir(dataSetDir + 'testDigits') # load the testing set 90 numSamples = len(testingFileList) 91 test_x = zeros((numSamples, 1024)) 92 test_y = [] 93 for i in xrange(numSamples): 94 filename = testingFileList[i] 95 96 # get train_x 97 test_x[i, :] = img2vector(dataSetDir + 'testDigits/%s' % filename) 98 99 # get label from file name such as "1_18.txt" 100 label = int(filename.split('_')[0]) # return 1 101 test_y.append(label) 102 103 return train_x, train_y, test_x, test_y 104 105 # 手写识别主流程 106 def testHandWritingClass(): 107 # # step 1: 加载数据 108 print "step 1: load data..." 109 train_x, train_y, test_x, test_y = loadDataSet() 110 111 # # step 2: 模型训练. 112 print "step 2: training..." 113 pass 114 115 # # step 3: 测试 116 print "step 3: testing..." 117 numTestSamples = test_x.shape[0] 118 matchCount = 0 119 for i in xrange(numTestSamples): 120 predict = kNNClassify(test_x[i], train_x, train_y, 3) 121 if predict == test_y[i]: 122 matchCount += 1 123 accuracy = float(matchCount) / numTestSamples 124 125 # # step 4: 输出结果 126 print "step 4: show the result..." 127 print 'The classify accuracy is: %.2f%%' % (accuracy * 100)
KNNTest.py
#!/usr/bin/python # coding=utf-8 import KNN KNN.testHandWritingClass()
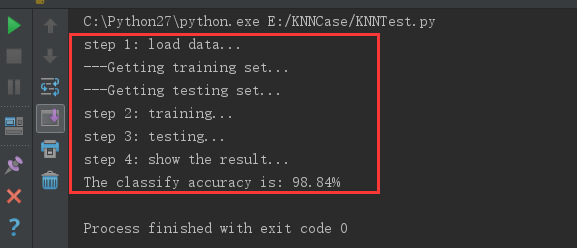
测试结果: