原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12254786.html
NA handling methods

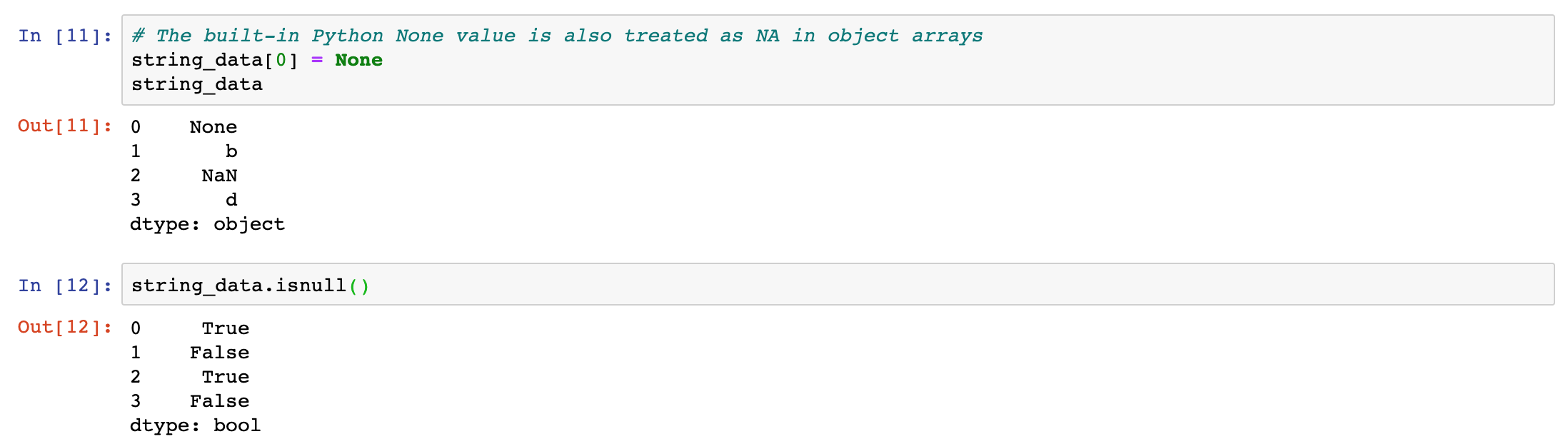
isnull, not null

The built-in Python None value is also treated as NA in object arrays
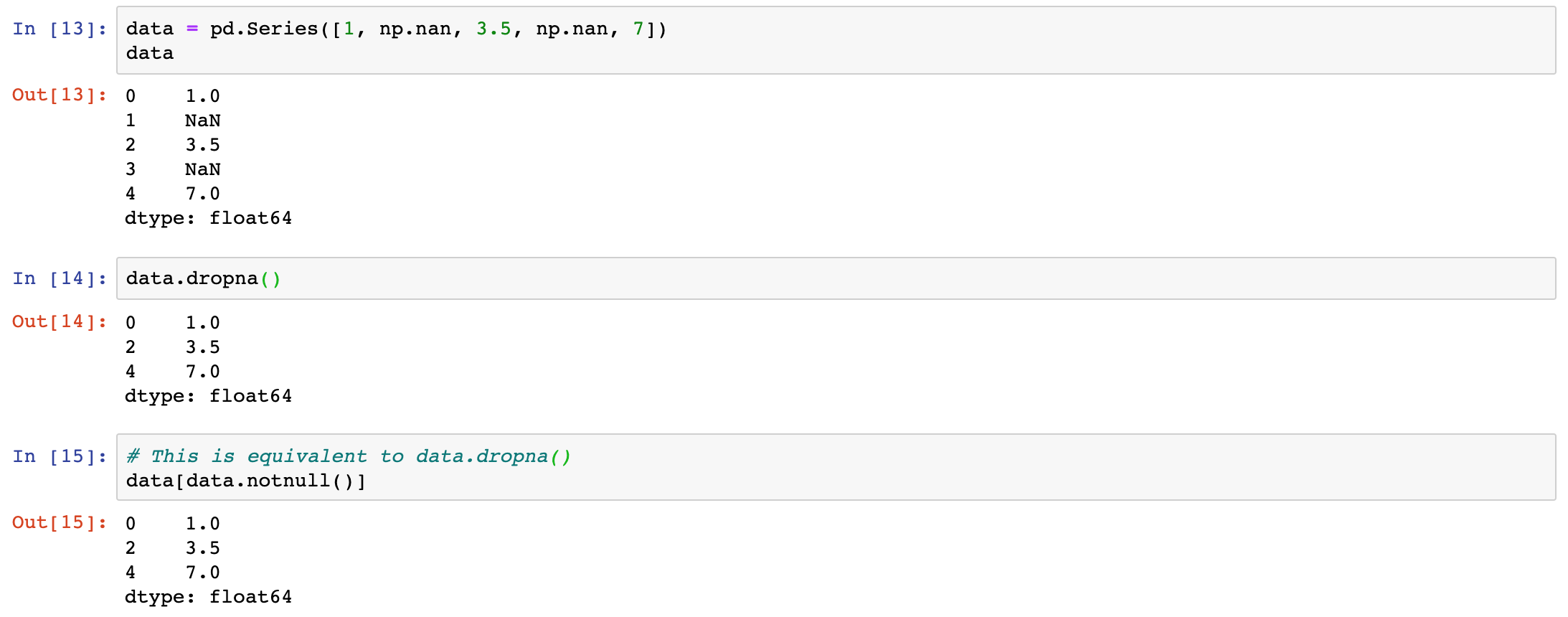
dropna
There are a few ways to filter out missing data. While you always have the option to do it by hand using pandas.isnull and boolean indexing, the dropna can be helpful. On a Series, it returns the Series with only the non-null data and index values.
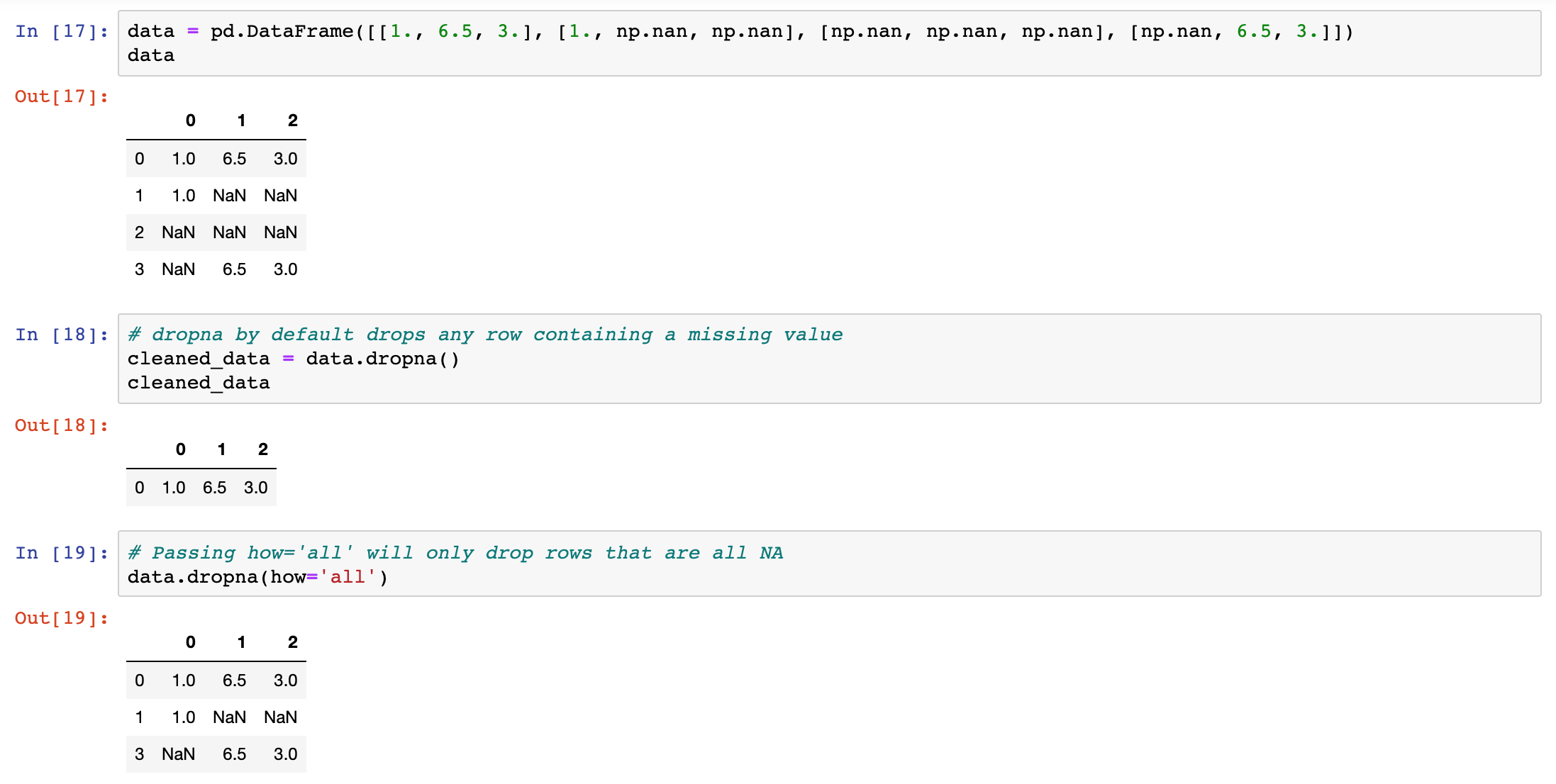
With DataFrame objects, things are a bit more complex. You may want to drop rows or columns that are all NA or only those containing any NAs.
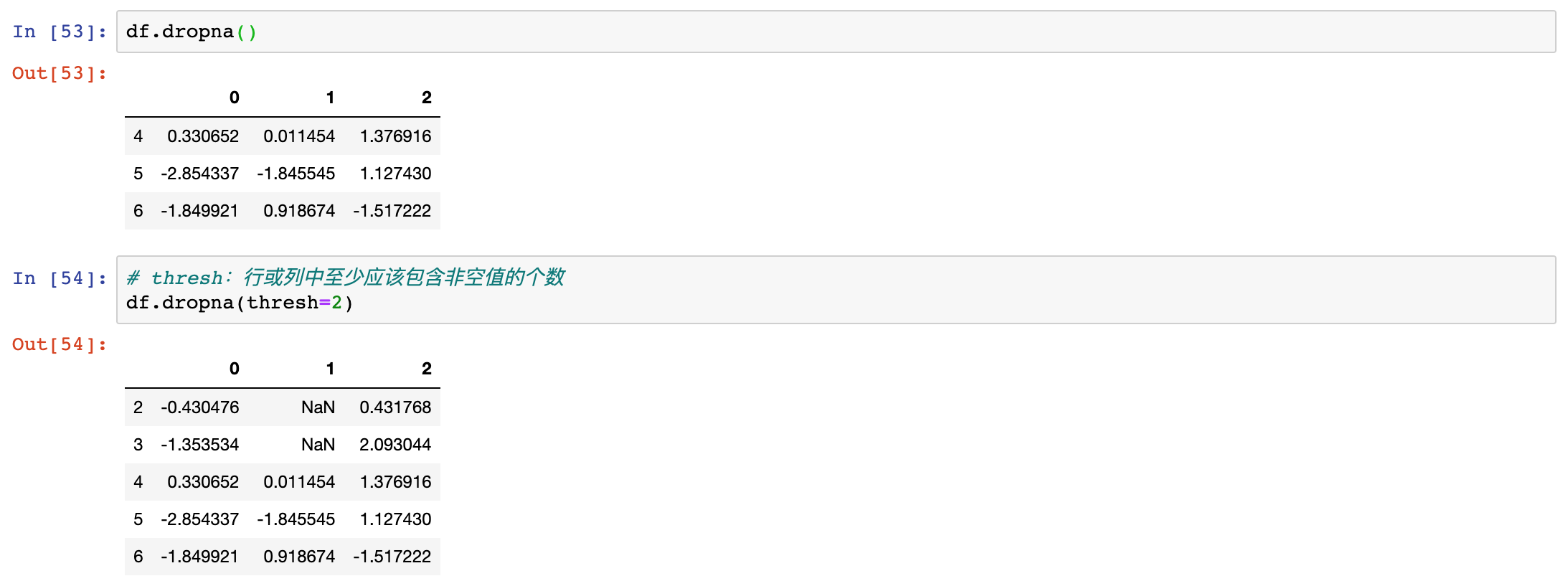
dropna by default drops any row containing a missing value.
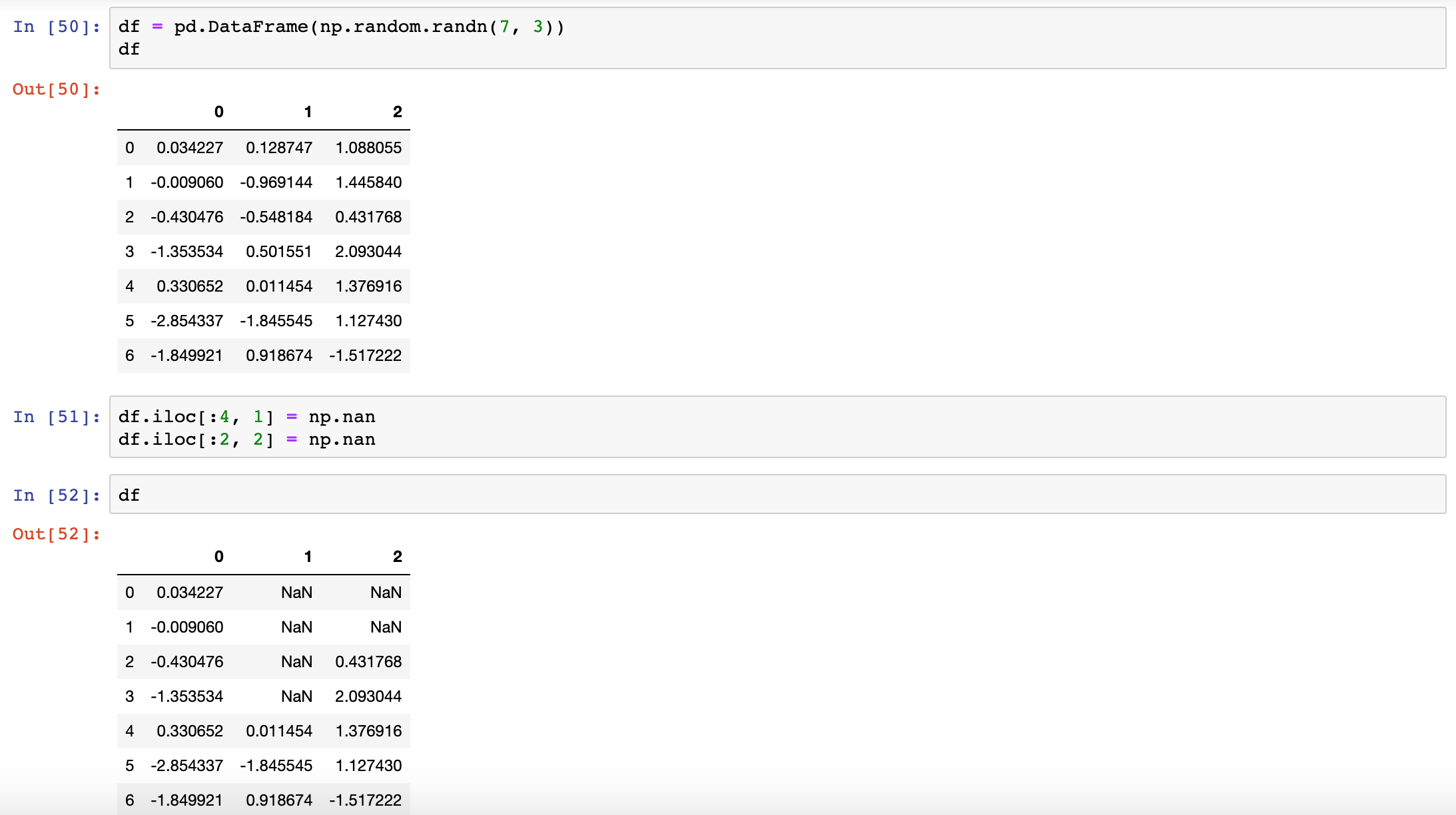
To drop columns in the same way, pass axis=1

thresh - Require that many non-NA value
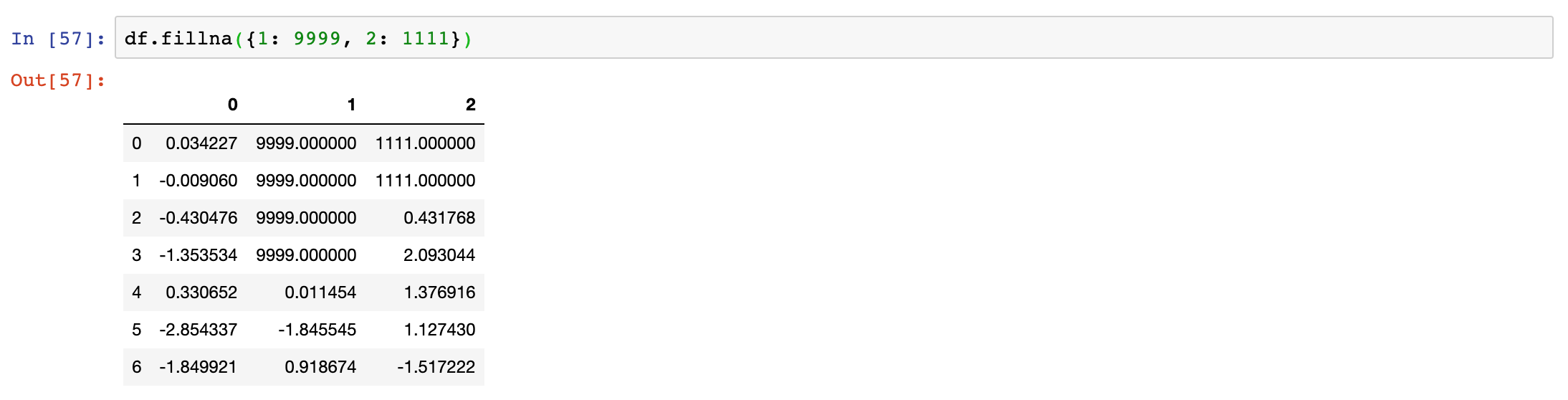
fillna

Calling fillna with a dict, you can use a different fill value for each column
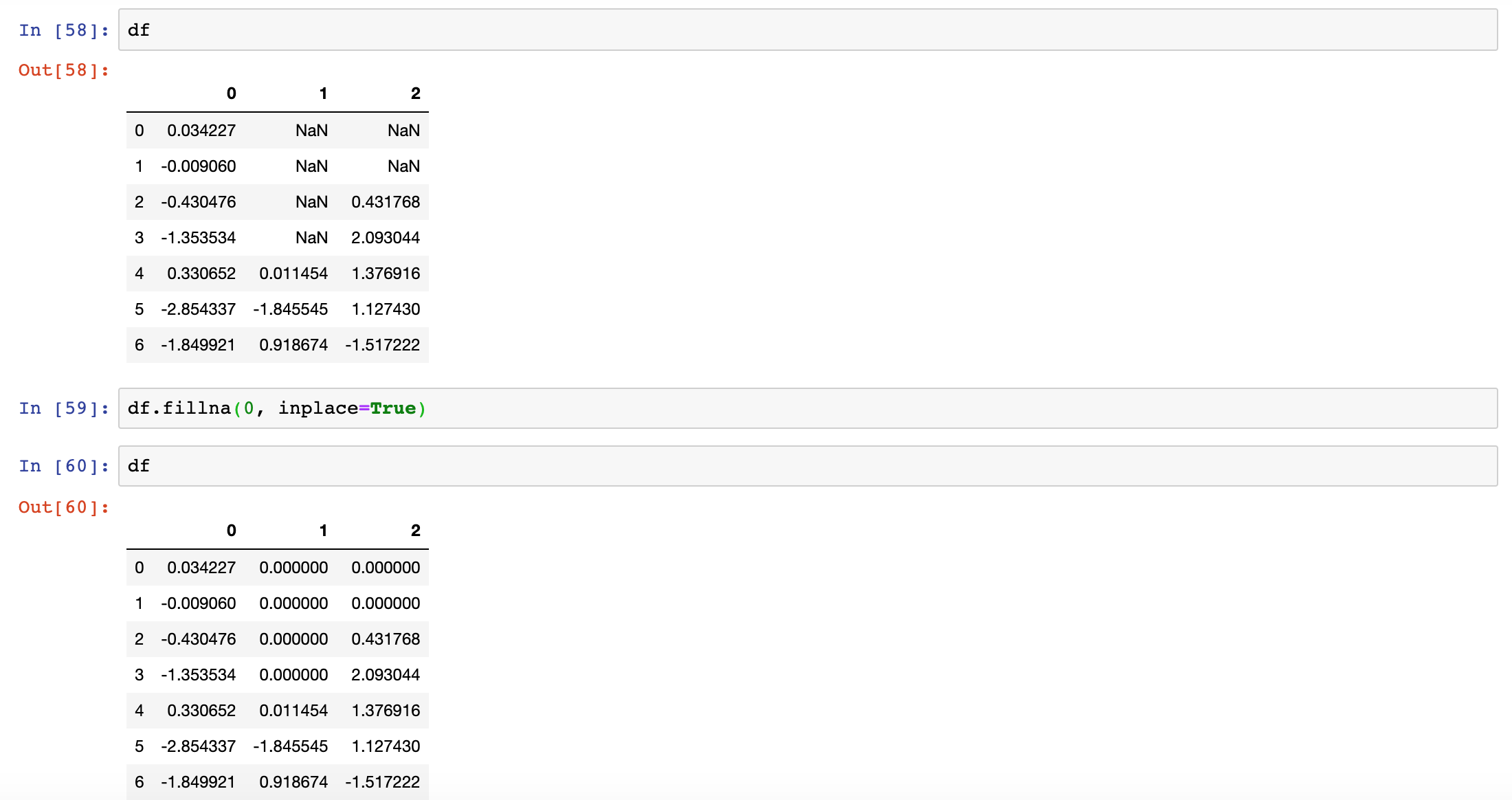
fillna returns a new object, but you can modify the existing object in-place
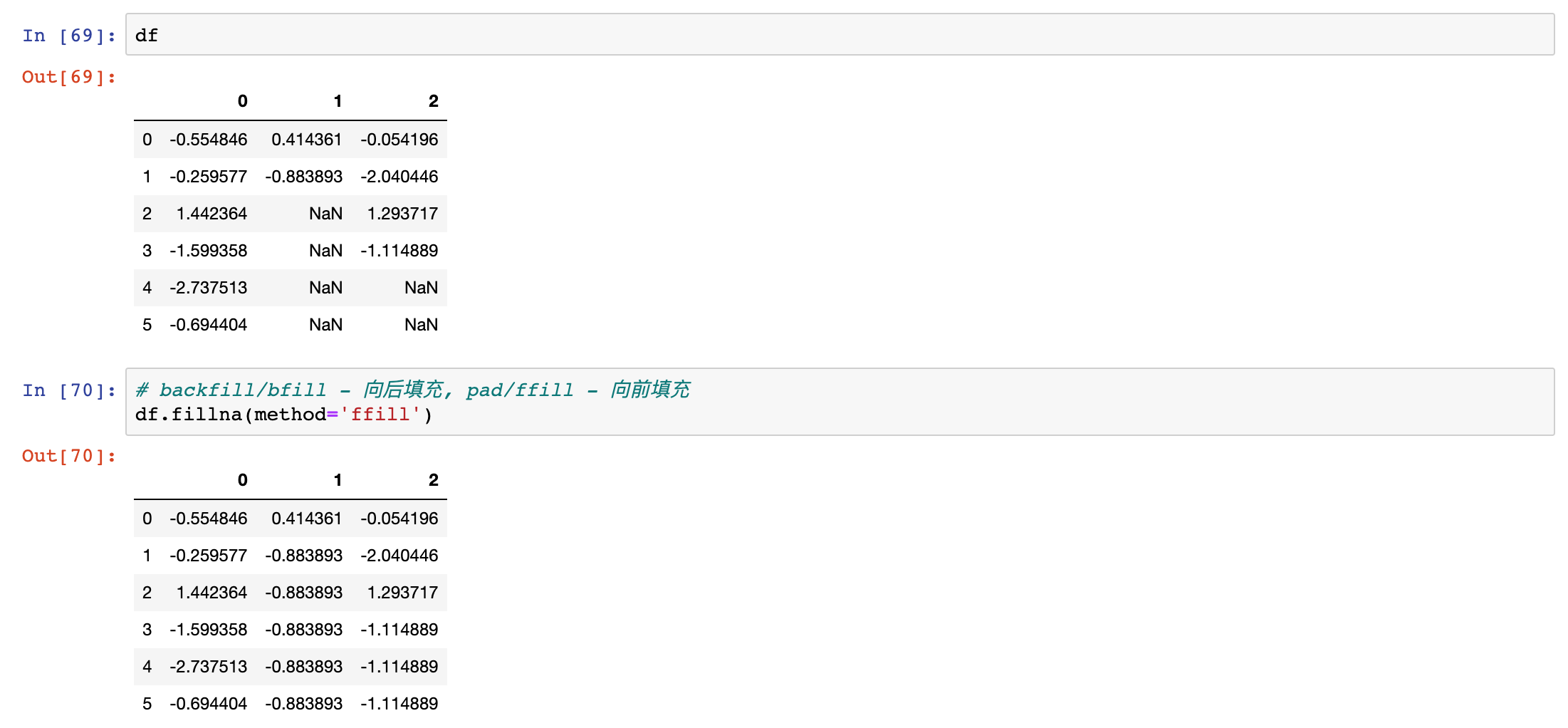
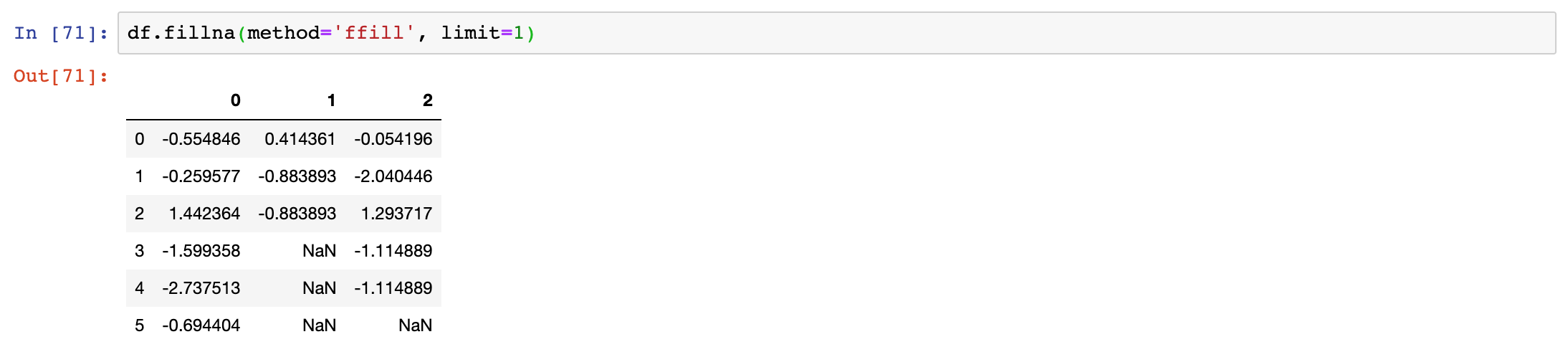
method{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None
Reference
Python for Data Analysis Second Edition
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.isnull.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.notnull.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.dropna.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.dropna.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.fillna.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.fillna.html