一、Hadoop引言
Hadoop是在2006年雅虎从Nutch(给予Java爬虫框架)工程中剥离一套分布式的解决方案.该方案参考了Goggle的GFS(Google File System)和MapReduce论文,当时发布的版本称为Hadoop-1.x,并且在2010年雅虎对Hadoop做又一次升级,该次升级的目的是优化了Hadoop的MapReduce框架,使得Hadoop更加易用,用户只需要少许配置,就可以使用hadoop实现海量数据存储和大规模数据集的分析.一个由Apache基金会所开发的分布式系统基础架构。
HDFS: hadoop distribute filesysterm
Map Reduce:hadoop中的分布式计算框架,实现对海量数据并行分析和计算.
YARN: hadoop 的资源调度系统
Common: 以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
二、HDFS (存储)
I、Hadoop Eco System(hadoop の 生态圈)
HDFS:分布式存储系统
mapreduce:并行计算框架
hbase:基于HDFS之上一款NoSQL数据库(名符其实海量数据存储解决方案)
hive:会一款SQL的解析引擎,可以将SQL翻译成MapReduce任务,将任务提交给MapReduce框架.
flume:分布式日志采集系统,用于搜集海量数据,并且存储到HDFS/Hbase.
Kafka:分布式消息系统,实现分布系统间解耦和海量数据的缓冲.
zookeeper:分布式协调服务,用于服务注册中心/配置中心/集群选举/状态监测/分布式锁
II、大数据分析方案哪些?
Map Reduce:代表基于磁盘离线大数据静态批处理框架-延迟较高30分钟+
Spark :代表基于内存近实时(离线)大数据静态批处理框架-几乎是Map Reduce的10~100倍速度
Storm|Spark Streaming| Flink|Kafka Stream:实时的流(流程)处理框架,达到对记录级别的数据显示毫秒级处理.
I、HDFS 环境搭建
1.安装JDK
- Window 安装64 bit CentOS(需要额外开启Intel 虚拟化技术)
- 安装JDK配置
JAVA_HOME
[root@CentOS ~]# yum install lrzsz -y
[root@CentOS ~]# rz #回车
rz waiting to receive.
Starting zmodem transfer. Press Ctrl+C to cancel.
Transferring jdk-8u171-linux-x64.rpm...
100% 171154 KB 17115 KB/sec 00:00:10 0 Errors
[root@CentOS ~]# rpm -ivh jdk-8u171-linux-x64.rpm
[root@CentOS ~]# vi /root/.bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source /root/.bashrc
[root@CentOS ~]# jps
1495 Jps
尝试
[root@CentOS ~]# yum install lrzsz -y组件,如果用户将JAVA_HOME配置在系统变量中/etc/profile需要在安装hadoop时候额外配置etc/hadoop/hadoop-env.sh,因此推荐配置在用户变量中.
- 配置主机名和IP映射关系
/etc/hosts
[root@CentOS ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.169.139 CentOS
在分布式系统中很多服务都是以主机名标示节点,因此配置IP和主机名的映射关系.用户可以查看以下文件
[root@CentOS ~]# cat /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=CentOS
- 关闭防火墙服务
[root@CentOS ~]# service iptables stop #关闭服务
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# chkconfig iptables off #关闭开机自起
[root@CentOS ~]# chkconfig --list | grep iptables
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
因为搭建分布式服务之间可能会产生相互的调度,为了保证正常的通信,一般需要关闭防火墙.
- 配置主机SSH免密码认证(秘钥)
SSH 为 Secure Shell 的缩写,SSH 为建立在应用层基础上的安全协议,专为远程登录会话和其他网络服务提供安全性的协议。
基于口令的安全验证:基于口令用户名/密码
基于密匙的安全验证:
需要依靠密匙,也就是你必须为自己创建一对密匙,并把公用密匙放在需要访问的服务器上。如果你要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用你的密匙进行安全验证。服务器收到请求之后,先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用你的私人密匙解密再把它发送给服务器。
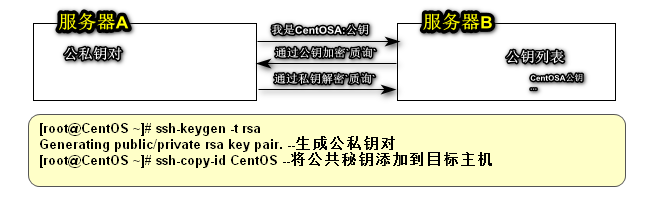
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
c3:b7:c4:e3:5e:6f:db:69:48:23:1e:f7:81:9b:d1:8e root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| |
| . . |
| S = o |
| = = * o |
| + * X .|
| . o E.=.|
| . .+o.|
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.169.139)' can't be established.
RSA key fingerprint is f0:63:ed:d6:21:3b:b5:47:ad:e2:7f:98:bd:8f:54:94.
Are you sure you want to continue connecting (yes/no)? `yes`
Warning: Permanently added 'centos,192.168.169.139' (RSA) to the list of known hosts.
root@centos's password:`****`
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
2.HADOOP HDFS安装与配置
参考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
解压并且配置HADOOP_HOME
[root@CentOS ~]# tar -zxf hadoop-2.6.0_x64.tar.gz -C /usr/
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOS ~]# source /root/.bashrc
[root@CentOS ~]# echo $HADOOP_HOME
/usr/hadoop-2.6.0
HADOOP_HOME环境变量被第三方产品所依赖例如:hbase/hive/flume/Spark在集成Hadoop的时候,是通过读取> HADOOP_HOME环境变量确定HADOOP位置.
配置etc/hadoop/core-site.xml*
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.6.0/hadoop-${user.name}</value>
</property>
配置etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
配置etc/hadoop/slaves
CentOS
- 启动HDFS
1.如果是第一次启动HDFS,需要格式化namenode
[root@CentOS ~]# hdfs namenode -format
...
19/01/02 20:19:37 INFO common.Storage: Storage directory /usr/hadoop-2.6.0/hadoop-root/dfs/name has been successfully formatted.
...
格式化成功后,用户可以看到以下目录结构
[root@CentOS ~]# yum install -y tree
[root@CentOS ~]# tree /usr/hadoop-2.6.0/hadoop-root/
/usr/hadoop-2.6.0/hadoop-root/
└── dfs
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
3..启动HDFS服务
[root@CentOS ~]# start-dfs.sh
Starting namenodes on [CentOS]
CentOS: namenode running as process 1846. Stop it first.
CentOS: starting datanode, logging to /usr/hadoop-2.6.0/logs/hadoop-root-datanode-CentOS.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is f0:63:ed:d6:21:3b:b5:47:ad:e2:7f:98:bd:8f:54:94.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop-2.6.0/logs/hadoop-root-secondarynamenode-CentOS.out
[root@CentOS ~]# jps
2370 Jps
2133 DataNode
1846 NameNode
2267 SecondaryNameNode
[root@CentOS ~]# stop-dfs.sh
Stopping namenodes on [CentOS]
CentOS: stopping namenode
CentOS: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
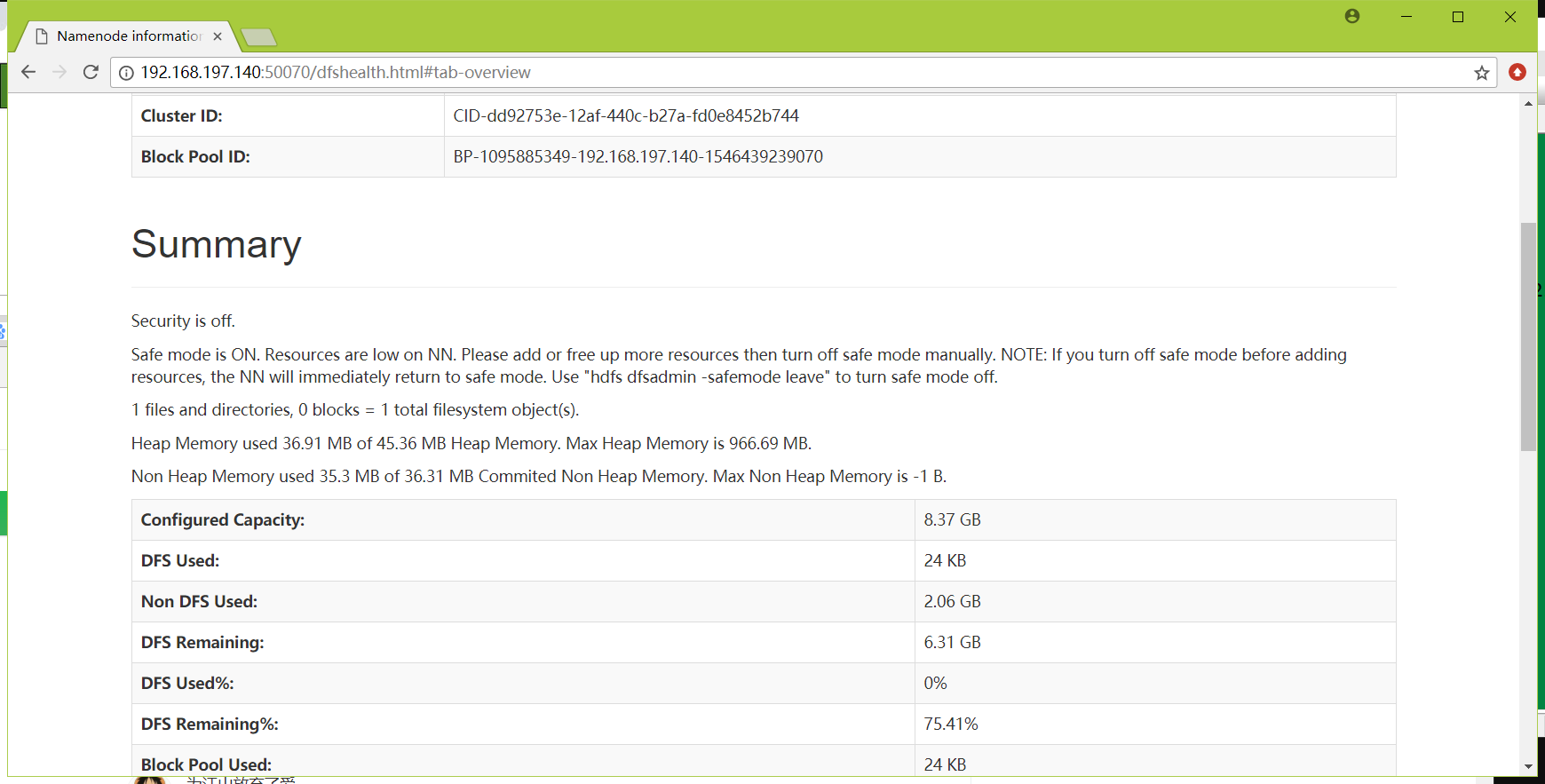
或者用户可以访问浏览器:http://192.168.197.140:50070
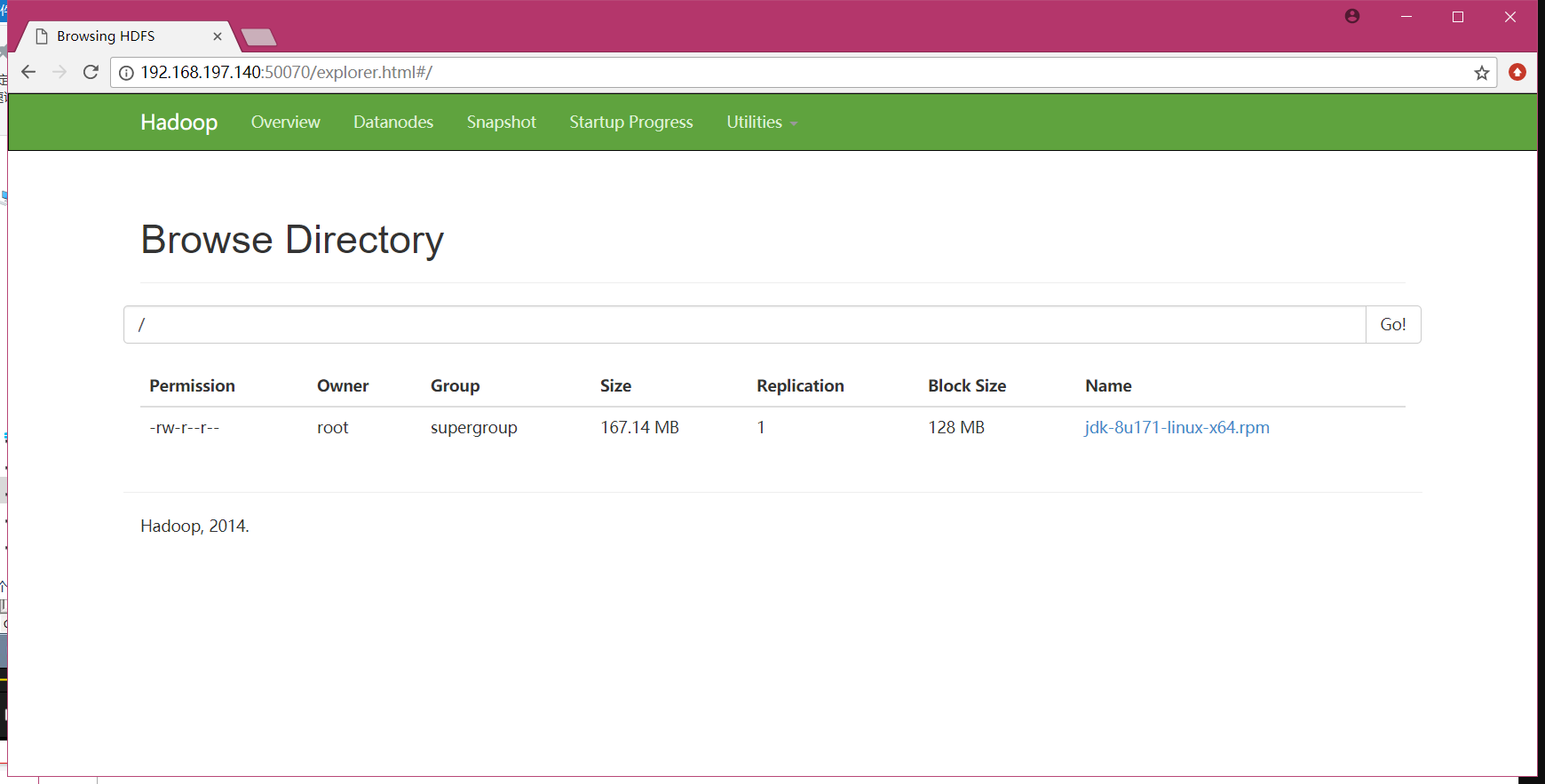
[root@CentOS ~]# hdfs dfs -put /root/jdk-8u171-linux-x64.rpm /
[root@CentOS ~]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 1 root supergroup 175262413 2019-01-02 20:29 /jdk-8u171-linux-x64.rpm
4.开启 HDFS 的回收站
etc/hadoop/core-site.xml
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
设置1分钟延迟,1分钟以后被删除文件会被系统彻底删除.防止用户误操作
[root@CentOS ~]# hdfs dfs -rm -r -f /bb.log
19/01/03 12:27:08 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://CentOS:9000/bb.log' to trash at: hdfs://CentOS:9000/user/root/.Trash/Current
[root@CentOS ~]# hdfs dfs -rm -r -f -skipTrash /aa.log
Deleted /aa.log