HashMap是java里比较常用的一个集合类,我们一般用来缓存一些处理后的结果。但当你做一个Android项目时,在代码中定义这样一个变量,实例化时,Eclipse却给出了一个 performance 警告。

意思是说Map已经不用了,使用SparseArray<Object>代替,以获取更好性能。为什么用SparseArray呢,单从字面意思,SparseArray就是稀疏数组(参见 http://hi.baidu.com/piaopiao_0423/item/d8cc2b99729f8380581461d1)。
所谓稀疏数组就是数组中大部分的内容值都未被使用(或都为零),在数组中仅有少部分的空间使用。因此造成内存空间的浪费,为了节省内存空间,并且不影响数组中原有的内容值,我们可以采用一种压缩的方式来表示稀疏数组的内容。
假设有一个9*7的数组,其内容如下:
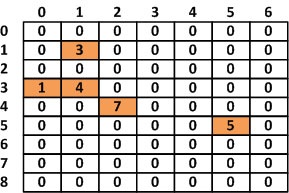 图 1 二维数组示例
图 1 二维数组示例
在此数组中,共有63个空间,但却只使用了5个元素,造成58个元素空间的浪费。以下我们就使用稀疏数组重新来定义这个数组:
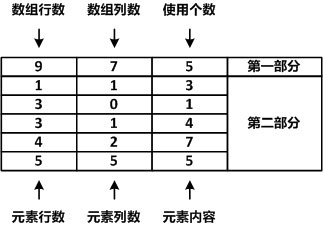 图 2 使用稀疏数组进行压缩
图 2 使用稀疏数组进行压缩
其中在稀疏数组中第一部分所记录的是原数组的列数和行数以及元素使用的个数、第二部分所记录的是原数组中元素的位置和内容。经过压缩之后,原来需要声明大小为63的数组,而使用压缩后,只需要声明大小为6*3的数组,仅需18个存储空间。
我们再来看看源码中SparseArray到底做了哪些事情:
类结构

继续阅读SparseArray的源码,从构造方法我们可以看出,它和一般的List一样,可以预先设置容器大小,默认的大小是10:

也可以自定义容量

再来看看它对数据的“增删改查”。
它有两个方法可以添加键值对:

有四个方法可以执行删除操作:

修改数据起初以为只有setValueAt(int index, E value)可以修改数据,但后来发现put(int key, E value)也可以修改数据,我们查看put(int key, E value)的源码可知,在put数据之前,会先查找要put的数据是否已经存在,如果存在就是修改,不存在就添加。
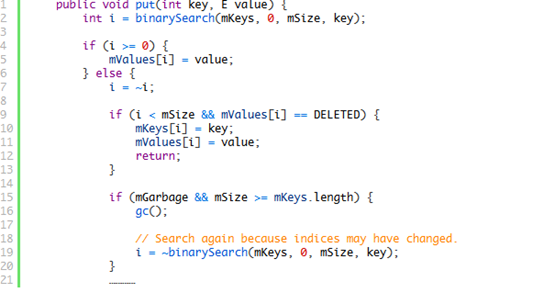
所以,修改数据实际也有两种方法:

最后再来看看如何查找数据。有两个方法可以查询取值:
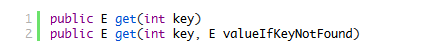
其中get(int key)也只是调用了 get(int key,E valueIfKeyNotFound),最后一个从传参的变量名就能看出,传入的是找不到的时候返回的值.get(int key)当找不到的时候,默认返回null。
查看第几个位置的键:

有一点需要注意的是,查看键所在位置,由于是采用二分法查找键的位置,所以找不到时返回小于0的数值,而不是返回-1。返回的负值是表示它在找不到时所在的位置。
查看第几个位置的值:

查看值所在位置,没有的话返回-1:

最后,发现其核心就是折半查找函数(binarySearch),算法设计的很不错。

相应的也有SparseBooleanArray,用来取代HashMap<Integer, Boolean>,SparseIntArray用来取代HashMap<Integer, Integer>,大家有兴趣的可以研究。
总结:SparseArray是android里为<Interger,Object>这样的Hashmap而专门写的类,目的是提高内存效率,其核心是折半查找函数(binarySearch)。注意内存二字很重要,因为它仅仅提高内存效率,而不是提高执行效率,所以也决定它只适用于android系统(内存对android项目有多重要,地球人都知道)。SparseArray有两个优点:1.避免了自动装箱(auto-boxing),2.数据结构不会依赖于外部对象映射。我们知道HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置,存放的都是数组元素的引用,通过每个对象的hash值来映射对象。而SparseArray则是用数组数据结构来保存映射,然后通过折半查找来找到对象。但其实一般来说,SparseArray执行效率比HashMap要慢一点,因为查找需要折半查找,而添加删除则需要在数组中执行,而HashMap都是通过外部映射。但相对来说影响不大,最主要是SparseArray不需要开辟内存空间来额外存储外部映射,从而节省内存。