程序语言的发展
机器语言
程序语言,最初的计算机语言是机器语言,完全是0和1组成的二进制串
如:01010101
11010101
汇编语言
因为01010101的字符串,冗长,不利于维护,所以产生了带助记符的汇编语言
举例:fua = 01010101
fub = 11010101
c语言
在汇编的基础上开发了c语言
有了常量,变量,字符串,等运算规则
java、c#、php、python
在c语言的基础长有发展了java、c#、php、python 等各种语言
这些语言都需要安装运行环境,也可以理解成软件,
Python前世今生
python的创始人为吉多·范罗苏姆(Guido van Rossum)。1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。互联网公司广泛使用Python来做的事一般有:自动化运维、自动化测试、大数据分析、爬虫、Web 等。
注视:上述重点字体表示该公司主要使用Python语言开发
为什么是Python而不是其他语言?
C 和 Python、Java、C#等
C语言: 代码编译得到 机器码 ,机器码在处理器上直接执行,每一条指令控制CPU工作
其他语言: 代码编译得到 字节码 ,虚拟机执行字节码并转换成机器码再后在处理器上执行
Python 和 C Python这门语言是由C开发而来
对于使用:Python的类库齐全并且使用简洁,如果要实现同样的功能,Python 10行代码可以解决,C可能就需要100行甚至更多.
对于速度:Python的运行速度相较与C,绝逼是慢了
Python 和 Java、C#等
对于使用:Linux原装Python,其他语言没有;以上几门语言都有非常丰富的类库支持
对于速度:Python在速度上可能稍显逊色
所以,Python和其他语言没有什么本质区别,其他区别在于:擅长某领域、人才丰富、先入为主。
Python的种类
- Cpython
Python的官方版本,使用C语言实现,使用最为广泛,CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 - Jyhton
Python的Java实现,Jython会将Python代码动态编译成Java字节码,然后在JVM上运行。 - IronPython
Python的C#实现,IronPython将Python代码编译成C#字节码,然后在CLR上运行。(与Jython类似) - PyPy(特殊)
Python实现的Python,将Python的字节码字节码再编译成机器码。 - RubyPython、Brython ...
以上除PyPy之外,其他的Python的对应关系和执行流程如下:

Python环境
安装Python
windows:
1、下载安装包 https://www.python.org/downloads/
2、安装 默认安装路径:C:python27
3、配置环境变量 【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【Python安装目录追加到变值值中,用 ; 分割】 如:原来的值;C:python27,切记前面有分号
linux:
无需安装,原装Python环境 ps:如果自带2.6,请更新至2.7 更新Python
windows:
卸载重装即可
linux:
Linux的yum依赖自带Python,为防止错误,此处更新其实就是再安装一个Python
查看默认Python版本 python -V
1、安装gcc,用于编译Python源码 yum install gcc
2、下载源码包,https://www.python.org/ftp/python/
3、解压并进入源码文件
4、编译安装 ./configure make all make install
5、查看版本 /usr/local/bin/python2.7 -V
6、修改默认Python版本 mv /usr/bin/python /usr/bin/python2.6 ln -s /usr/local/bin/python2.7 /usr/bin/python
7、防止yum执行异常,修改yum使用的Python版本 vi /usr/bin/yum 将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6
Python入门
Python的运行方式
终端运行方式:
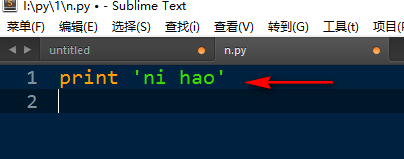
打开Python终端,输入print "ni hao"
>>> print "ni hao" 回车
ni hao
这样就将ni hao打印出来了

文件运行方式:
用编辑器将 print "ni hao" 写入编辑器,保存成Python文件,以.py 后缀方式保存
打开终端不启动Python 输入Python 文件路径 如:I:py1 .py 回车执行

这样就执行了n.py并把文件内容读出来了
两者之间的区别,终端执行是执行一次关闭终端后不保留代码,文件执行是可以多次执行,并且代码写入了.py文件里
注意:Python2.7和3.5的函数区别 如:print函数
2.7 print "ni hao"
3.5 print ("ni hao")
两个版本之间在函数的书写格式上,3.5必须加括号() 2.7 可以加括号() 也可以不加
Python解释器
可以理解为解释代码或者代码文件的软件
上面可以看到我们在终端里输入了 Python I:py1 .py 这样就是说告诉了系统用Python解释器,解释I:py1 .py这个文件
如果想要访问文件时自动执行python解释器,例输入: ./n.py ,那么就需要在 n.py文件的头部指定解释器
如果需要解释器自动执行一种字符编码方式解释,也需要在头部指定字符编码
如

这样当系统访问文件时,就告诉了系统,我这个文件需要Python解释器解释 并且以utf-8的编码
假如这个文件在根目录下,如此一来,执行: ./n.py 即可。
注意:执行前需给予 n.py 执行权限,chmod 755 n.py
内容编码
字符编码的发展
ascii (只能识别英文)
8位 = 01010101 2**8(2的8次方)= 256 种组合就可以表示所有的英文,字符,数字
也就是1个字节就能表示所有的英文,字符,数字
但是不能表示其他国家语言如中文
万国码 unicode (包含任何国家语言)
最少用2个字节来表示:
1个字节 = 8位 = 01010101
2个字节 = 16位 = 0101010101010101 2个字节就是 2**16(2的16次方)= 65536 种组合
也就是说万国码最少也要用两个字节来表示
中文是用3个字节来表示的
3个字节 = 24位 = 010101010101010101010101 3个字节就是 2**24(2的24次方)= 16777216 种组合
utf-8
有了万国码后人们又发现,造成了运算空间的浪费,明明可以用1个字节表示的也用了2个字节来表示,后来就又发明了utf-8
utf-8 是在万国码的基础上进行了加工
也就是utf-8会自动根据地区语言来判断用多少位识别
英文:8位
欧洲:16位
中文:24位
...
所以我们在写Python文件是要是有中文汉字,就需要告诉解释器用什么编码
如:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 print '你好 中国'
如果是Python3.5版本解释器,就可以不加编码,因为默认就是utf-8编码
也就是说,解释器默认是utf-8就可以不加,如果默认不是utf-8就必须加才能识别中文
编码和解码
编码和解码流程图
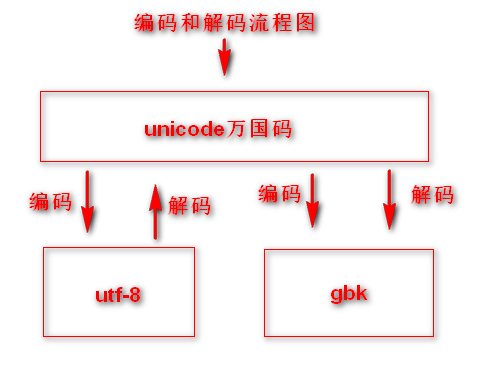
utf-8或者gbk等编码都是,由万国码编码而来的这个过程叫做(编码),将utf-8在还原成万国码这个过程叫做(解码)
在python中可以将某一段字符进行编码或者解码
decode() 函数 为解码 函数值:为要解码的编码(原本编码)
使用方法:要解码的字符串变量.decode(要解码的编码)
如:jiem = zifu.decode("utf-8")
encode() 函数 为编码 函数值:为要编的码(编码)
使用方法:要编码的解码变量.decode(要编的码)
举例:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 zifu = "中文字符" 4 #解码,需要指定原来的是什么编码 5 jiem = zifu.decode("utf-8") 6 #编码,需要指定要使用什么编码 7 bianm = jiem.encode("gbk") 8 print(bianm)
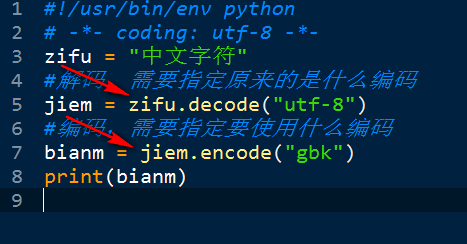
注意:如果是python3.5或者以上版本,可以省略解码的环境,直接第二步重新编码就可以,也就是可以直接将utf-8直接编码成gbk,(解码的过程解释器会自动完成)