CSRF(Cross-site request forgery跨站请求伪造,也被称成为“one click attack”或者session riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。
一、CSRF攻击原理
CSRF攻击原理比较简单,如图1所示。其中Web A为存在CSRF漏洞的网站,Web B为攻击者构建的恶意网站,User C为Web A网站的合法用户。
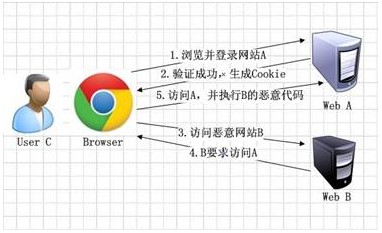
图1 CSRF攻击原理
1. 用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
2.在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
3. 用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
4. 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
5. 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行。
二、CSRF漏洞防御
CSRF漏洞防御主要可以从三个层面进行,即服务端的防御、用户端的防御和安全设备的防御。
1、 服务端的防御
.1.1 验证HTTP Referer字段
根据HTTP协议,在HTTP头中有一个字段叫Referer,它记录了该HTTP请求的来源地址。在通常情况下,访问一个安全受限页面的请求必须来自于同一个网站。比如某银行的转账是通过用户访问http://bank.test/test?page=10&userID=101&money=10000页面完成,用户必须先登录bank.test,然后通过点击页面上的按钮来触发转账事件。当用户提交请求时,该转账请求的Referer值就会是转账按钮所在页面的URL(本例中,通常是以bank. test域名开头的地址)。而如果攻击者要对银行网站实施CSRF攻击,他只能在自己的网站构造请求,当用户通过攻击者的网站发送请求到银行时,该请求的Referer是指向攻击者的网站。因此,要防御CSRF攻击,银行网站只需要对于每一个转账请求验证其Referer值,如果是以bank. test开头的域名,则说明该请求是来自银行网站自己的请求,是合法的。如果Referer是其他网站的话,就有可能是CSRF攻击,则拒绝该请求。
1.2 在请求地址中添加token并验证
CSRF攻击之所以能够成功,是因为攻击者可以伪造用户的请求,该请求中所有的用户验证信息都存在于Cookie中,因此攻击者可以在不知道这些验证信息的情况下直接利用用户自己的Cookie来通过安全验证。由此可知,抵御CSRF攻击的关键在于:在请求中放入攻击者所不能伪造的信息,并且该信息不存在于Cookie之中。鉴于此,系统开发者可以在HTTP请求中以参数的形式加入一个随机产生的token,并在服务器端建立一个拦截器来验证这个token,如果请求中没有token或者token内容不正确,则认为可能是CSRF攻击而拒绝该请求。
1.3 在HTTP头中自定义属性并验证
自定义属性的方法也是使用token并进行验证,和前一种方法不同的是,这里并不是把token以参数的形式置于HTTP请求之中,而是把它放到HTTP头中自定义的属性里。通过XMLHttpRequest这个类,可以一次性给所有该类请求加上csrftoken这个HTTP头属性,并把token值放入其中。这样解决了前一种方法在请求中加入token的不便,同时,通过这个类请求的地址不会被记录到浏览器的地址栏,也不用担心token会通过Referer泄露到其他网站。
2、 其他防御方法
1. CSRF攻击是有条件的,当用户访问恶意链接时,认证的cookie仍然有效,所以当用户关闭页面时要及时清除认证cookie,对支持TAB模式(新标签打开网页)的浏览器尤为重要。
2. 尽量少用或不要用request()类变量,获取参数指定request.form()还是request. querystring (),这样有利于阻止CSRF漏洞攻击,此方法只不能完全防御CSRF攻击,只是一定程度上增加了攻击的难度。
代码示例:
Java 代码示例
下文将以 Java 为例,对上述三种方法分别用代码进行示例。无论使用何种方法,在服务器端的拦截器必不可少,它将负责检查到来的请求是否符合要求,然后视结果而决定是否继续请求或者丢弃。在 Java 中,拦截器是由 Filter 来实现的。我们可以编写一个 Filter,并在 web.xml 中对其进行配置,使其对于访问所有需要 CSRF 保护的资源的请求进行拦截。
在 filter 中对请求的 Referer 验证代码如下
清单 1. 在 Filter 中验证 Referer
// 从 HTTP 头中取得 Referer 值
String referer=request.getHeader("Referer");
// 判断 Referer 是否以 bank.example 开头
if((referer!=null) &&(referer.trim().startsWith(“bank.example”))){
chain.doFilter(request, response);
}else{
request.getRequestDispatcher(“error.jsp”).forward(request,response);
}
以上代码先取得 Referer 值,然后进行判断,当其非空并以 bank.example 开头时,则继续请求,否则的话可能是 CSRF 攻击,转到 error.jsp 页面。
如果要进一步验证请求中的 token 值,代码如下
清单 2. 在 filter 中验证请求中的 token
HttpServletRequest req = (HttpServletRequest)request;
HttpSession s = req.getSession();
// 从 session 中得到 csrftoken 属性
String sToken = (String)s.getAttribute(“csrftoken”);
if(sToken == null){
// 产生新的 token 放入 session 中
sToken = generateToken();
s.setAttribute(“csrftoken”,sToken);
chain.doFilter(request, response);
} else{
// 从 HTTP 头中取得 csrftoken
String xhrToken = req.getHeader(“csrftoken”);
// 从请求参数中取得 csrftoken
String pToken = req.getParameter(“csrftoken”);
if(sToken != null && xhrToken != null && sToken.equals(xhrToken)){
chain.doFilter(request, response);
}else if(sToken != null && pToken != null && sToken.equals(pToken)){
chain.doFilter(request, response);
}else{
request.getRequestDispatcher(“error.jsp”).forward(request,response);
}
}
首先判断 session 中有没有 csrftoken,如果没有,则认为是第一次访问,session 是新建立的,这时生成一个新的 token,放于 session 之中,并继续执行请求。如果 session 中已经有 csrftoken,则说明用户已经与服务器之间建立了一个活跃的 session,这时要看这个请求中有没有同时附带这个 token,由于请求可能来自于常规的访问或是 XMLHttpRequest 异步访问,我们分别尝试从请求中获取 csrftoken 参数以及从 HTTP 头中获取 csrftoken 自定义属性并与 session 中的值进行比较,只要有一个地方带有有效 token,就判定请求合法,可以继续执行,否则就转到错误页面。生成 token 有很多种方法,任何的随机算法都可以使用,Java 的 UUID 类也是一个不错的选择。
除了在服务器端利用 filter 来验证 token 的值以外,我们还需要在客户端给每个请求附加上这个 token,这是利用 js 来给 html 中的链接和表单请求地址附加 csrftoken 代码,其中已定义 token 为全局变量,其值可以从 session 中得到。
清单 3. 在客户端对于请求附加 token
Tornado 使用经验【防范 跨站伪造请求CSRF 或 XSRF;2、防止伪造 cookie 】
最近在做一个网站的后端开发。因为初期只有我一个人做,所以技术选择上很自由。在 web 服务器上我选择了 。虽然曾经也读过它的源码,并做过一些小的 demo,但毕竟这是第一次在工作中使用,难免又发现了一些值得分享的东西。
首先想说的是它的安全性,这方面确实能让我感受到它的良苦用心。这主要可以分为两点:
- 防范 跨站伪造请求 (Cross-site request forgery,简称 CSRF 或 XSRF)。
CSRF 的意思简单来说就是,攻击者伪造真实用户来发送请求。
举例来说,假设某个银行网站有这样的 URL:
http://bank.example.com/withdraw?amount=1000000&for=Eve
当这个银行网站的用户访问该 URL 时,就会给 Eve 这名用户一百万元。用户当然不会轻易地点击这个 URL,但是攻击者可以在其他网站上嵌入一张伪造的图片,将图片地址设为该 URL:
那么当用户访问那个恶意网站时,浏览器就会对该 URL 发起一个 GET 请求,于是在用户毫不知情的情况下,一百万就被转走了。<img src="http://bank.example.com/withdraw?amount=1000000&for=Eve">
要防范上述攻击很简单,不允许通过 GET 请求来执行更改操作(例如转账)即可。不过其他类型的请求照样也不安全,假如攻击者构造这样一个表单:
不明真相的用户点了下“转发”按钮,结果钱就被转走了…<form action="http://bank.example.com/withdraw" method="post"> <p>转发抽奖送 iPad 啊!</p> <input type="hidden" name="amount" value="1000000"> <input type="hidden" name="for" value="Eve"> <input type="submit" value="转发"> </form>
要杜绝这种情况,就需要在非 GET 请求时添加一个攻击者无法伪造的字段,处理请求时验证这个字段是否修改过。
Tornado 的处理方法很简单,在请求中增加了一个随机生成的 _xsrf 字段,并且 cookie 中也增加这个字段,在接收请求时,比较这 2 个字段的值。
由于非本站的网页是不能获取或修改 cookie 的,这就保证了 _xsrf 无法被第三方网站伪造(HTTP 嗅探例外)。
当然,用户自己是可以随意获取和修改 cookie 的,不过这已经不属于 CSRF 的范畴了:用户自己伪造自己所做的事情,当然由他自己来承担。
要使用该功能的话,需要在生成 tornado.web.Application 对象时,加上 xsrf_cookies=True 参数,这会给用户生成一个名为 _xsrf 的 cookie 字段。
此外还需要你在非 GET 请求的表单里加上 xsrf_form_html(),如果不用 Tornado 的模板的话,在 tornado.web.RequestHandler 内部可以用 self.xsrf_form_html() 来生成。
对于 AJAX 请求来说,基本上是不需要担心跨站的,所以 Tornado 1.1.1 以前的版本并不对带有 X-Requested-With: XMLHTTPRequest 的请求做验证。
后来 Google 的工程师指出,恶意的浏览器插件可以伪造跨域 AJAX 请求,所以也应该进行验证。对此我不置可否,因为浏览器插件的权限可以非常大,伪造 cookie 或是直接提交表单都行。
不过解决办法仍然要说,其实只要从 cookie 中获取 _xsrf 字段,然后在 AJAX 请求时加上这个参数,或者放在 X-Xsrftoken 或 X-Csrftoken 请求头里即可。嫌麻烦的话,可以用 jQuery 的 $.ajaxSetup() 来处理:
$.ajaxSetup({ beforeSend: function(jqXHR, settings) { type = settings.type if (type != 'GET' && type != 'HEAD' && type != 'OPTIONS') { var pattern = /(.+; *)?_xsrf *= *([^;" ]+)/; var xsrf = pattern.exec(document.cookie); if (xsrf) { jqXHR.setRequestHeader('X-Xsrftoken', xsrf[2]); } } }});
此外再顺便谈谈 跨站脚本 (Cross-site scripting,简称 XSS)。和 CSRF 相反的是,XSS 是利用被攻击网站自身的漏洞,在该网站上注入攻击者想执行的脚本代码,让浏览该网站的用户执行。
不过只要不让用户随意输入 HTML(例如对 < 和 > 进行转义),对 HTML 元素的属性做验证(例如属性里的引号要转义,src 和 事件处理等属性不能随意填写 JavaScript 代码等),并检查 CSS(含 style 属性)中的 expression 即可避免。 - 防止伪造 cookie。
前面提到的 CSRF 和 XSS 都是攻击者在用户不知情的情况下,冒用他的名义来进行操作;而伪造 cookie 则是攻击者自己主动伪造其他用户来进行操作。
举例来说,假设网站的登录验证就是检查 cookie 中的用户名,只要符合的话,就认为该用户已登录。那么攻击者只要在 cookie 中设置 username=admin 之类的值,就可以冒充管理员来操作了。
要防止 cookie 被伪造,首先需要提到设置 cookie 时的两个参数: secure 和 httponly 。这两个参数并不在 tornado.web.RequestHandler.set_cookie() 的参数列表里,而是作为关键字参数传递,并在 Cookie.Morsel._reserved 中定义的。
前者是指这个 cookie 只能通过安全连接传递(即 HTTPS),这就使得嗅探者无法截获该 cookie;后者则要求其只能在 HTTP 协议下访问(即无法通过 JavaScript 来获取 document.cookie 中的该字段,并且设置后也不会通过 HTTP 协议向服务器发送),这便使得攻击者无法简单地通过 JavaScript 脚本来伪造 cookie。
不过对于恶意的攻击者,这两个参数并不能杜绝 cookie 被伪造。为此就需要对 cookie 做个签名,一旦被修改,服务器端可以判断出来。
Tornado 中提供了 set_secure_cookie() 这个方法来对 cookie 做签名。签名时需要提供一串秘钥(生成 tornado.web.Application 对象时的 cookie_secret 参数),这个秘钥可以通过如下代码来生成:
这个参数可以随机生成,但如果同时有多个 Tornado 进程来服务的话,或者有时会重启的话,还是共用一个常量比较好,并且注意不要泄露。base64.b64encode(uuid.uuid4().bytes + uuid.uuid4().bytes)
这个签名用的是 HMAC 算法 ,hash 算法采用的是 SHA1。简单来说就是把 cookie 名、值和时间戳的 hash 作为签名,再把“值|时间戳|签名”作为新的值。这样服务器端只要拿秘钥再次加密,比较签名是否有变化过即可判断真伪。
值得一提的是读源码时还发现这样一个函数:
读了半天也没发现和普通的字符串比较有什么优点,直到看了 StackOverflow 上的答案才知道:为了避免攻击者通过测试比较时间来判断正确的位数,这个函数让比较的时间比较恒定,也就杜绝了这种情况。(话说这答案看得我各种佩服啊,搞安全的专家果然不是我那么肤浅的…)def _time_independent_equals(a, b): if len(a) != len(b): return False result = 0 if type(a[0]) is int: # python3 byte strings for x, y in zip(a, b): result |= x ^ y else: # python2 for x, y in zip(a, b): result |= ord(x) ^ ord(y) return result == 0
接着是继承 tornado.web.RequestHandler。
在执行流程上,tornado.web.Application 会根据 URL 寻找一个匹配的 RequestHandler 类,并初始化它。它的 __init__() 方法会调用 initialize() 方法,所以只要覆盖后者即可,并且不需要调用父类的 initialize()。
接着根据不同的 HTTP 方法寻找该 handler 的 get/post() 等方法,并在执行前运行 prepare()。这些方法都不会主动调用父类的,因此有需要时,自行调用吧。
最后会调用 handler 的 finish() 方法,这个方法最好别覆盖。它会调用 on_finish() 方法,它可以被覆盖,用于处理一些善后的事情(例如关闭数据库连接),但不能再向浏览器发送数据了(因为 HTTP 响应已发送,连接也可能已被关闭)。
顺便说下怎么处理错误页面。
简单来说,执行 RequestHandler 的 _execute() 方法(内部依次执行 prepare()、get() 和 finish() 等方法)时,任何未捕捉的错误都会被它的 write_error() 方法捕捉,因此覆盖这个方法即可:
class RequestHandler(tornado.web.RequestHandler):
def write_error(self, status_code, **kwargs):
if status_code == 404:
self.render('404.html')
elif status_code == 500:
self.render('500.html')
else:
super(RequestHandler, self).write_error(status_code, **kwargs)此外,你还可能没到 _execute() 方法就出错了。
例如 initialize() 方法抛出了一个未捕捉的异常,这个异常会被 IOStream 捕捉到,然后直接关闭连接,不能向用户输出任何错误页面。
再比如没有找到一个能处理该请求的 handler,就会用 tornado.web.ErrorHandler 去处理 404 错误。这种情况可以替换这个类来实现自定义错误页面:
class PageNotFoundHandler(RequestHandler):
def get(self):
raise tornado.web.HTTPError(404)
tornado.web.ErrorHandler = PageNotFoundHandlerapplication = tornado.web.Application([
# ...
('.*', PageNotFoundHandler)
])接着说说处理登录。
Tornado 提供了 @tornado.web.authenticated 这个装饰器,在 handler 的 get() 等方法前加上即可。
它会依赖三处代码:
- 需要定义 handler 的 get_current_user() 方法,例如:
它的返回值为假时,就会跳转到登录页面了。def get_current_user(self): return self.get_secure_cookie('user_id', 0) - 创建 application 时设置 login_url 参数:
application = tornado.web.Application( [ # ... ], login_url = '/login' ) - 定义 handler 的 get_login_url() 方法。
如果不能使用默认的 login_url 参数(例如普通用户和管理员需要不同的登录地址),那么可以覆盖 get_login_url() 方法:
class AdminHandler(RequestHandler): def get_login_url(self): return '/admin/login'
class LoginHandler(RequestHandler):
def get(self):
if self.get_current_user():
self.redirect('/')
return
self.render('login.html')
def post(self):
if self.get_current_user():
raise tornado.web.HTTPError(403)
# check username and password
if success:
self.redirect(self.get_argument('next', '/'))def authenticated(method):
"""Decorate methods with this to require that the user be logged in."""
@functools.wraps(method)
def wrapper(self, *args, **kwargs):
if not self.current_user:
if self.request.headers.get('X-Requested-With') == 'XMLHttpRequest': # jQuery 等库会附带这个头
self.set_header('Content-Type', 'application/json; charset=UTF-8')
self.write(json.dumps({'success': False, 'msg': u'您的会话已过期,请重新登录!'}))
return
if self.request.method in ("GET", "HEAD"):
url = self.get_login_url()
if "?" not in url:
if urlparse.urlsplit(url).scheme:
# if login url is absolute, make next absolute too
next_url = self.request.full_url()
else:
next_url = self.request.uri
url += "?" + urllib.urlencode(dict(next=next_url))
self.redirect(url)
return
raise tornado.web.HTTPError(403)
return method(self, *args, **kwargs)
return wrapper然后说下获取用户的 IP 地址。
简单来说,在 handler 的方法里用 self.request.remote_ip 就能拿到了。
不过如果使用了反向代理,拿到的就是代理的 IP 了,这时候就需要在创建 HTTPServer 时增加 xheaders 的设置了:
if __name__ == '__main__':
from tornado.httpserver import HTTPServer
from tornado.netutil import bind_sockets
sockets = bind_sockets(80)
server = HTTPServer(application, xheaders=True)
server.add_sockets(sockets)
tornado.ioloop.IOLoop.instance().start()if settings.IPV4_ONLY:
import socket
sockets = bind_sockets(80, family=socket.AF_INET)
else:
sockets = bind_sockets(80)最后再提下生产环境下如何提高性能。Tornado 可以在 HTTPServer 调用 add_sockets() 前创建多个子进程,利用多 CPU 的优势来处理并发请求。
简单来说,代码如下:
if __name__ == '__main__':
if settings.IPV4_ONLY:
import socket
sockets = bind_sockets(80, family=socket.AF_INET)
else:
sockets = bind_sockets(80)
if not settings.DEBUG_MODE:
import tornado.process
tornado.process.fork_processes(0) # 0 表示按 CPU 数目创建相应数目的子进程
server = HTTPServer(application, xheaders=True)
server.add_sockets(sockets)
tornado.ioloop.IOLoop.instance().start()