数据网址:http://www.sogou.com/labs/resource/q.php
搜狗实验室提供【用户查询日志(SogouQ)】数据分为三个数据集,大小不一样
迷你版(样例数据, 376KB):http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.mini.zip
精简版(1天数据,63MB):http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.reduced.zip
完整版(1.9GB):http://www.sogou.com/labs/resource/ftp.php?dir=/Data/SogouQ/SogouQ.zip



添加依赖:
<dependency> <groupId>com.hankcs</groupId> <artifactId>hanlp</artifactId> <version>portable-1.7.7</version> </dependency>
测试:
package cn.itcast.core import java.util import com.hankcs.hanlp.HanLP import com.hankcs.hanlp.seg.common.Term /** * Author itcast * Desc HanLP入门案例 */ object HanLPTest { def main(args: Array[String]): Unit = { val words = "[HanLP入门案例]" val terms: util.List[Term] = HanLP.segment(words) println(terms) //直接打印java的list:[[/w, HanLP/nx, 入门/vn, 案例/n, ]/w] import scala.collection.JavaConverters._ println(terms.asScala.map(_.word)) //转为scala的list:ArrayBuffer([, HanLP, 入门, 案例, ]) val cleanWords1: String = words.replaceAll("\[|\]", "") //将"["或"]"替换为空"" //"HanLP入门案例" println(cleanWords1) //HanLP入门案例 println(HanLP.segment(cleanWords1).asScala.map(_.word)) //ArrayBuffer(HanLP, 入门, 案例) val log = """00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html""" val cleanWords2 = log.split("\s+")(2) //[360安全卫士] .replaceAll("\[|\]", "") //360安全卫士 println(HanLP.segment(cleanWords2).asScala.map(_.word)) //ArrayBuffer(360, 安全卫士) } }

案例:
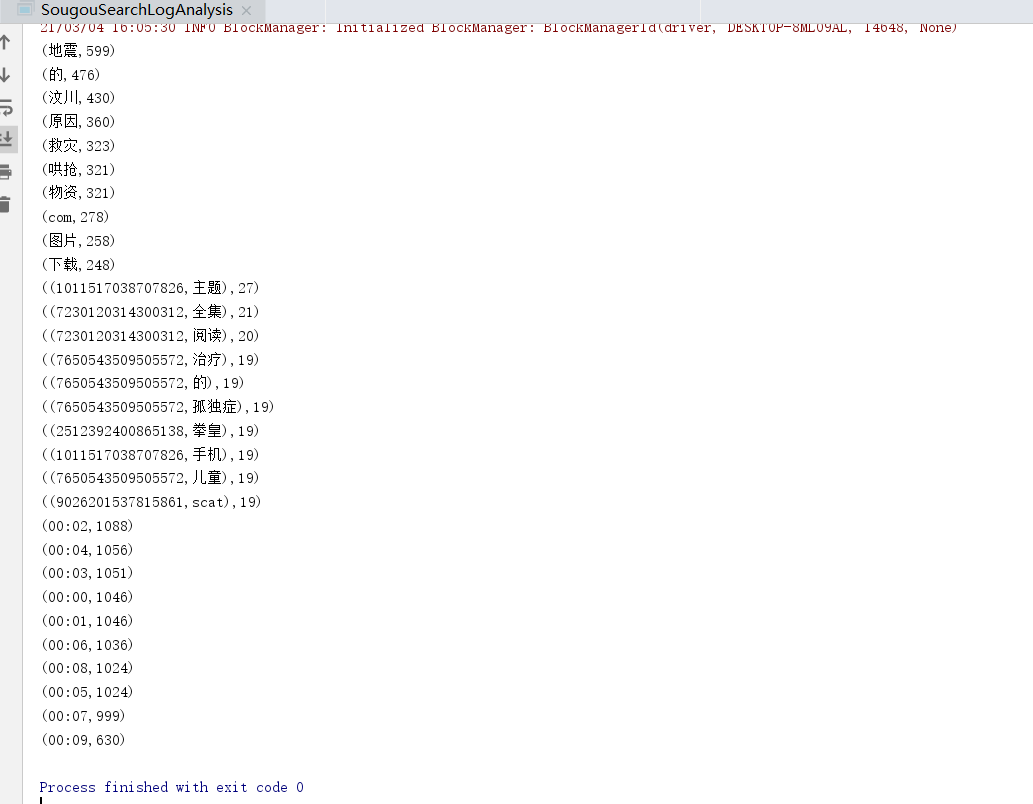
package cn.itcast.core import com.hankcs.hanlp.HanLP import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import shapeless.record import spire.std.tuples import scala.collection.immutable.StringOps import scala.collection.mutable /** * Author itcast * Desc 需求:对SougouSearchLog进行分词并统计如下指标: * 1.热门搜索词 * 2.用户热门搜索词(带上用户id) * 3.各个时间段搜索热度 */ object SougouSearchLogAnalysis { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //TODO 1.加载数据 val lines: RDD[String] = sc.textFile("data/input/SogouQ.sample") //TODO 2.处理数据 //封装数据 val SogouRecordRDD: RDD[SogouRecord] = lines.map(line => {//map是一个进去一个出去 val arr: Array[String] = line.split("\s+") SogouRecord( arr(0), arr(1), arr(2), arr(3).toInt, arr(4).toInt, arr(5) ) }) //切割数据 /* val wordsRDD0: RDD[mutable.Buffer[String]] = SogouRecordRDD.map(record => { val wordsStr: String = record.queryWords.replaceAll("\[|\]", "") //360安全卫士 import scala.collection.JavaConverters._ //将Java集合转为scala集合 HanLP.segment(wordsStr).asScala.map(_.word) //ArrayBuffer(360, 安全卫士) })*/ val wordsRDD: RDD[String] = SogouRecordRDD.flatMap(record => { //flatMap是一个进去,多个出去(出去之后会被压扁) //360安全卫士==>[360, 安全卫士] val wordsStr: String = record.queryWords.replaceAll("\[|\]", "") //360安全卫士 import scala.collection.JavaConverters._ //将Java集合转为scala集合 HanLP.segment(wordsStr).asScala.map(_.word) //ArrayBuffer(360, 安全卫士) }) //TODO 3.统计指标 //--1.热门搜索词 val result1: Array[(String, Int)] = wordsRDD .filter(word => !word.equals(".") && !word.equals("+")) //过滤 .map((_, 1)) .reduceByKey(_ + _) .sortBy(_._2, false) .take(10) //--2.用户热门搜索词(带上用户id) val userIdAndWordRDD: RDD[(String, String)] = SogouRecordRDD.flatMap(record => { //flatMap是一个进去,多个出去(出去之后会被压扁) //360安全卫士==>[360, 安全卫士] val wordsStr: String = record.queryWords.replaceAll("\[|\]", "") //360安全卫士 import scala.collection.JavaConverters._ //将Java集合转为scala集合 val words: mutable.Buffer[String] = HanLP.segment(wordsStr).asScala.map(_.word) //ArrayBuffer(360, 安全卫士) val userId: String = record.userId words.map(word => (userId, word)) }) val result2: Array[((String, String), Int)] = userIdAndWordRDD .filter(t => !t._2.equals(".") && !t._2.equals("+")) .map((_, 1)) .reduceByKey(_ + _) .sortBy(_._2, false) .take(10) //--3.各个时间段搜索热度 val result3: Array[(String, Int)] = SogouRecordRDD.map(record => { val timeStr: String = record.queryTime val hourAndMitunesStr: String = timeStr.substring(0, 5) (hourAndMitunesStr, 1) }).reduceByKey(_ + _) .sortBy(_._2, false) .take(10) //TODO 4.输出结果 result1.foreach(println) result2.foreach(println) result3.foreach(println) //TODO 5.释放资源 sc.stop() } //准备一个样例类用来封装数据 /** * 用户搜索点击网页记录Record * @param queryTime 访问时间,格式为:HH:mm:ss * @param userId 用户ID * @param queryWords 查询词 * @param resultRank 该URL在返回结果中的排名 * @param clickRank 用户点击的顺序号 * @param clickUrl 用户点击的URL */ case class SogouRecord( queryTime: String, userId: String, queryWords: String, resultRank: Int, clickRank: Int, clickUrl: String ) }