题目描述
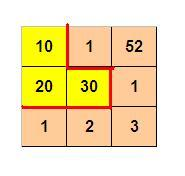
如图p1.jpg所示,3 x 3 的格子中填写了一些整数。
我们沿着图中的红色线剪开,得到两个部分,每个部分的数字和都是60。
本题的要求就是请你编程判定:对给定的m x n 的格子中的整数,是否可以分割为两个部分,使得这两个区域的数字和相等。
如果存在多种解答,请输出包含左上角格子的那个区域包含的格子的最小数目。
如果无法分割,则输出 0
程序输入输出格式要求:
程序先读入两个整数 m n 用空格分割 (m,n<10)
表示表格的宽度和高度
接下来是n行,每行m个正整数,用空格分开。每个整数不大于10000
程序输出:在所有解中,包含左上角的分割区可能包含的最小的格子数目。
例如:
用户输入:
3 3
10 1 52
20 30 1
1 2 3
则程序输出:
3
再例如:
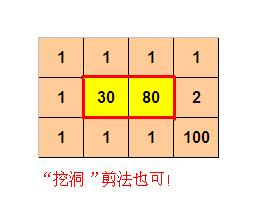
用户输入:
4 3
1 1 1 1
1 30 80 2
1 1 1 100
则程序输出:
10
(参见p2.jpg)
资源约定:
峰值内存消耗(含虚拟机) < 64M
CPU消耗 < 5000ms
请严格按要求输出,不要画蛇添足地打印类似:“请您输入…” 的多余内容。
所有代码放在同一个源文件中,调试通过后,拷贝提交该源码。
注意:不要使用package语句。不要使用jdk1.6及以上版本的特性。
注意:主类的名字必须是:Main,否则按无效代码处理。
import java.util.HashMap;
import java.util.HashSet;
import java.util.Scanner;
import java.util.Stack;
/**在蓝桥杯的测试里能AC
* 主要思想分成3部分:
* 1.统计矩阵里所有的数值的情况(这里用TreeMap可能会更好),搜索一个序列,这个序列加起来等于(总和/2 - 左上角的数),即这个序列加左上角的数等于总和的一半
* 2.从左上角开始遍历,测试1得到的数据能不能拼接到一个相连的块中
* 3.测试2得到的结果是不是正好将矩阵分成了两部分
* 采取1的原因在于直接遍历的计算量很大,实际是可能超时的,也可以进行记忆优化,我想大概可以使用HashMap<当前的和, 计算过与否>[10][10]作为搜索的记录
* 步骤1、2都有缺点,都能进一步优化,都能记忆处理
**/
public class Main {
static final int MAX = 10005; // 输入值得最大值
static final int MLEN = 105; // 输入矩阵的最大数据个数
static int m, n;
static int[] nums;
static int[] hash;
static int aim;
public static void main(String[] args) throws Exception {
Scanner sc = new Scanner(System.in);
m = sc.nextInt();
n = sc.nextInt();
nums = new int[n * m];
hash = new int[MAX]; // 散列
uf = new int[m * n]; // 类似并查集,最后判断是否分割成两部分使用
int all = 0; // 总和
for(int i = 0; i < nums.length; i ++) {
int t = sc.nextInt();
nums[i] = t;
hash[t] ++;
all += t;
}
sc.close();
hash[nums[0]] --; // 将位置0从中删除
if(all % 2 != 0) { // 和为奇数
System.out.println(0);
return;
}
aim = all / 2 - nums[0];
findAim(0, MAX-1);
if(!find)
System.out.println(0);
}
static int[] list = new int[105]; // 当前已经选择的数值
static int ind = 0; // 列表当前的下标
static boolean find = false; // 当找到了一个合理的答案之后,程序能快速结束
public static void findAim( // 查找一个能满足和为aim的序列
int sum, // 当前的和
int index) { // 遍历的位置
if(find)
return;
if(sum > aim)
return;
if(sum == aim) {
if(isValid()) {
System.out.println(ind + 1);
find = true;
}
return;
}
while(index > 0) {
if(hash[index] > 0) {
for(int i = hash[index]; i > -1; i --) { // 加上n个index的值 贪心为上
for(int j = 0; j < i; j ++) { // 更新链表
list[ind ++] = index;
}
findAim(sum + i*index, index-1);
ind -= i; // 回溯
}
return;
}else {
index --;
}
}
}
// 判断当前的list是否合法
// 需要判断
// 1.是否能将list数据和arr[0]拼接成一个整体
// 2.判断生成的结果是否可以分成两部分
static boolean isValid() {
validIndex = new HashSet<Integer>();
validIndex.add(1);
validIndex.add(m);
exist[0] = true; // 已经拥有0,0点
// 将list散列化 由于每一次都建立一个MAX大小的向量是不现实的,使用Map结构记录
tempMap.clear();
for(int i = 0; i < ind; i ++) {
Integer old = tempMap.put(list[i], 1); // 当前能够加入的值
if(old != null)
tempMap.put(list[i], 1 + old);
}
return dp(0);
}
static HashSet<Integer> validIndex;
static HashMap<Integer, Integer> tempMap = new HashMap<Integer,Integer>(); // 记录list中需要的数据,以及其需要的次数
static boolean[] exist = new boolean[MLEN]; // 当前已经拥有的位置
static boolean dp(int count) {
if(count == ind) {
if(isTwoPart())
return true;
else
return false;
}
// 找到当前能加入的点
// 结束时,addStack中包含了当前能加入的点的位置
// addStack里面放的是能加入的位置
Stack<Integer> addStack = new Stack<Integer>();
for(int li:validIndex) { // 遍历当前的合法位置
Integer key = tempMap.get(nums[li]);
if(key != null && key != 0) {
addStack.add(li);
}
}
// 选定一个点,加入
while(!addStack.isEmpty()) {
int node = addStack.pop();
int type = addNode(node);
if(dp(count + 1))
return true;
removeNode(node, type);
}
return false;
}
public static int addNode(int node) { // 加入一个位置,返回变动的类型
int type = 0;
if((node+1)%m != 0 && !exist[node + 1]) // 如果没到行末
if(validIndex.add(node + 1)) type |= 1;
if((node+m) < m*n && !exist[node + m]) // 如果没到列末
if(validIndex.add(node + m)) type |= 2;
if((node-m) > 0 && !exist[node - m]) // 不是第一行
if(validIndex.add(node - m)) type |= 4;
if(node % m != 0 && !exist[node - 1]) // 不是第一列
if(validIndex.add(node - 1)) type |= 8;
validIndex.remove(node); // 删除自身
exist[node] = true;
tempMap.put(nums[node], tempMap.get(nums[node]) - 1); // 维护map
return type;
}
public static void removeNode(int node, int type) {
if((type & 1) != 0) validIndex.remove(node + 1);
if((type & 2) != 0) validIndex.remove(node + m);
if((type & 4) != 0) validIndex.remove(node - m);
if((type & 8) != 0) validIndex.remove(node - 1);
validIndex.add(node);
exist[node] = false;
tempMap.put(nums[node], tempMap.get(nums[node]) + 1); // 维护map
}
static int[] uf; // 类似并查集Union Find
// 判断是否真的将表格分成两个部分
public static boolean isTwoPart() {
for(int i = 0; i < uf.length; i ++){
uf[i] = -1;
}
// 由于nums[0]一定是被选上的,故,先统计从nums[0]开始能合并多少个节点
uf[0] = 1;
merge(0);
// 找到一个没有被选择的位置,合并
int index = 0;
for(int i = 1; i < exist.length; i ++) {
if(!exist[i]) {
index = i;
break;
}
}
uf[index] = 2;
merge(index);
// 经过上述两个合并,使uf中最起码存在两个集合,这两个集合是联通的,且一个被选取的,一个不被选取的
// 如果uf还存在-1,就说明存在不能被两个集合划分
for(int i = 0; i < uf.length; i ++) {
if(uf[i] == -1)
return false;
}
return true;
}
// 从index位置开始,将与其相连且标签(标签指是否是否被选取)与其一致的元素合并,考虑exist数组
public static void merge(int index) {
if((index+1)%m != 0 && exist[index] == exist[index+1]) check(index, index + 1);// 如果没到行末,并且行末和这个位置的标签一致
if((index+m) < m*n && exist[index] == exist[index+m]) check(index, index + m);
if((index-m) > 0 && exist[index] == exist[index-m]) check(index, index - m);
if(index % m != 0 && exist[index] == exist[index-1]) check(index, index - 1);
}
// 为了能简单merge的代码,抽取代码
// 实际作用是:在已经判明index和next都存在,并且两者标签相同时,应该进行怎样的操作
public static void check(int index, int next) {
if(uf[next] == uf[index]) // 说明是重复搜索
return;
else {
uf[next] = uf[index];
merge(next); // 对next进行搜索
}
}
}