流的编程模型
通常使用流操作集合,用更简便的用法,更高效方式实现对集合的操作
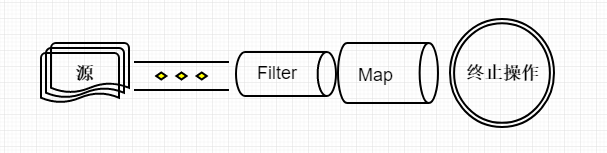
从源中获取流 --> 中间操作 ---> 汇聚流
我们在Stream基础上添加了一系列的中间操作,进一步加工Stream,终止操作操作会把Stream从新汇聚起来,我们可以选择统计数量,平均值,也可以选择把他们转换会集合的状态,得到新的集合
获取流的三种方式:
- Stream的静态方法
of()
支持可变参数
public static<T> Stream<T> of(T... values);
- Arrays的静态方法
Arrays.stream(数组)
- 通过集合的stream方法
List<Integer> list = Arrays.asList(1, 2, 3);
Stream stream4 = list.stream();
中间操作 与 汇聚操作
| 中间操作方法 | 作用 |
|---|---|
| filter(Predicate pre) | 过滤, 接受参数,返回boolean,满足条件的stream被保存下来 |
| limit(long maxSize) | 从开始截取保留maxSize个元素 |
| skip(long n) | 从开始舍弃n元素 |
| distinct() | 去重 |
| sorted() | 排序 |
| map(Function<T,R> fun) | 接受T,映射成R并返回 |
| flatMap(Function<T,R> fun) | 接受T,映射成R并返回, 并将流打平 |
| IntStream.range(start,end) | IntStream特有的方法,生成[start , end-1]的流 |
| IntStream.rangeClosed(start,end) | IntStream特有的方法,生成[start , end]的流 |
| 汇聚操作方法 | 作用 |
|---|---|
| sum() | 求和 |
| max(Comparator<? super T> comparator); | 最大值 |
| min(Comparator<? super T> comparator); | 最小值 |
| count() | 返回元素的个数 |
| T reduce(T identity, BinaryOperator |
汇聚,初始值identity, 每两个元素执行BinaryOperator规定的行为添加在identity上, 最终返回identity, 如累加 |
| T reduce(BinaryOperator |
汇聚,初始值0, 每两个元素执行BinaryOperator规定的行为 |
| collect(Collector col); | 最常用的汇聚 |
如果我们中间把Stream转换成了特化流, 如IntStream, 那么sum(),min(),max()全是已经帮我们实现好了的,不用重写比较器
举个例子: 将数组中的元素 先*2, 再累加求和
// list是源
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5,6);
System.out.println(list.stream().map(i->i*2).reduce(0,(I,J)->I+J));
System.out.println(list.stream().map(i->i*2).reduce(0,Integer::sum));
- 从源中获取流
- 中间操作map映射,接受一个Function函数入参,接受一个参数返回一个值,上面我们把i映射成了2*i,
- 汇聚操作,有重载, 我们选择有初始值的,设为0 , 第二个参数是BinaryOperator 继承了Bifunction, 接受两个相同类型的参数,返回一个值,上面是每两个元素进行求和
collect()
List<String> list1 = Arrays.asList("hi", "你好", "hello");
List<String> collect = list1.stream().collect(Collectors.toList());
上面可以看到,通过Collectors.toList()把流转换从新汇聚成了集合, 当然不仅仅局限于List
| Collectors | 作用 |
|---|---|
| Collectors.toSet() | 流汇聚成set |
| Collectors.toList() | 流汇聚成List |
| Collectors.toMap() | 流汇聚成Map |
| Collectors.toCollection(Supplier) | 流汇指定类型的集合,Supplier,一般是构造方法引用 |
| Collectors.toConcurrentMap() | 流汇聚成toConcurrentMap |
| Collectors.joining() | 将每个stream拼接起来 |
汇聚操作分三步走:
- 创建出需要汇聚成的最终需要返回的集合对象
- 将流中的每一个元素添加到集合对象中
- 将集合对象返回
list1.stream().collect(()->new ArrayList<String>(),
(theList,list1Item)->theList.add(list1Item),
(result,list)->result.addAll(list));
使用方法引用的方式去实现
list1.stream().collect(ArrayList::new,ArrayList::add,ArrayList::addAll);
分组
将一个集合使用流的方式分组groupingBy(), 返回值Map<String,List
Map<String, List<student>> map = list.stream().collect(Collectors.groupingBy(item -> item.getName()));
groupingBy的重载方法
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream)`
第二个参数Collector,我们同样使用Collectors的静态方法实现, 它可以针对每一个小组进行下一步操作, 如求总数counting(),求平均值averagingInt(ToIntFunction())
分区
分区和分组相伴相生:
Collectors:
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)
入参是Predicate类型的,接受一个参数,返回boolean值, 分区实际上就是根据条件分成两组,只不过现在称它是两个区
例:
// 80分以前的为一个区,其他为一个区
Map<Boolean, List<student>> collect1 = list.stream().collect(Collectors.partitioningBy(i -> i.getScore() > 80));
// 低于80分的个数 高于80分的个数
Map<Boolean, Long> collect2 = list.stream().collect(Collectors.partitioningBy(j -> j.getScore() > 80, Collectors.counting()));
System.out.println(collect2);
map中,ture为满足条的组, flase为不满足条件的组
flatMap流的打平
例: 将多个相同类型的集合,打平成一个Stream,获取新集合
Stream.of(Arrays.asList(1),Arrays.asList(2,3),Arrays.asList(4,5,6))
.flatMap(Collection::stream).map(i->i*i).collect(Collectors.toList()).forEach(System.out::println)
例: 将一个集合中元素去重
List<String> list = Arrays.asList("hello welcome", "world hello", "hello welcome world");
list.stream().map(item->item.split(" ")).flatMap(Arrays::stream).distinct().forEach(System.out::println);
当我们执行到这里,list.stream().map(item->item.split(" ")) 它的返回值类型是: Stream<String[]> 可以看到,是把源集合根据 空格 分成了多个Stream, 每一个Stream中包含的是复杂类型,数组,这样,我们再去重的话,其实是在数组之间的去重,而不是元素之间,因此我们需要将Stream<String[]>打平,转换成Stream<String str>,这样再去重就达到了我们的目的
例: 交叉打印
List<String> list1 = Arrays.asList("hi", "你好", "hello");
List<String> list2 = Arrays.asList("wangwu", "zhaoliu", "zhangsan", "lisi");
list1.stream().map(item1->list2.stream().map(item2->item1+" "+item2)).forEach(System.out::println);
如上,并未做出Stream的打平,我们将list1中的每一个元素item 映射成, item+list2中的每一个元素, 但是出现的map的嵌套, 它的返回值是 Stream<Stream
所以我们要向下面那样,把流打平:
list1.stream().flatMap(item1->list2.stream().map(item2->item1+ " "+item2)).forEach(System.out::println);
总结: 当出现下面的返回情况时,考虑flatMap,打平流
- Stream<List
list> - Stream<String[] array>
- Stream<Stream
>
Stream的其他方法
Stream<String> generate = Stream.generate(UUID.randomUUID()::toString);
generate.findFirst().ifPresent(System.out::println);
// 若不加限制,创建出无限流
Stream<Integer> stream = Stream.iterate(1, i -> i + 2).limit(6);
特化的流
| 方法名 | 作用 |
|---|---|
| map(Function<T,R>) | Function<T,R> 接受T类型,映射成R类型 |
| mapToInt(ToIntFunction |
统一泛型 Integer |
| mapToDouble(ToDoubleFunction |
统一泛型 Double |
| mapToLong(ToLongFunction |
统一泛型 Long |
如: mapToInt(item->item.lenth)我们可以把item映射成它的长度,进而可以进行下一步过滤等
转换成了特定流之后,可以实现特定的方法可以使用它替我们实现了 min,max,sort,avg针对特定类型的操作
流的惰性求值
例:
list.stream().map(item -> {
String result = item.substring(0, 1).toUpperCase() + item.substring(1);
System.out.println("test");
return result;
}).forEach(System.out::println);
list.stream().map(item -> {
String result = item.substring(0, 1).toUpperCase() + item.substring(1);
System.out.println("test");
return result;
});
参照文章一开始图片, Stream来资源, 我们在Stream基础上添加了一系列的中间操作Map,把每一个item的首字母转换成大写,进一步加工Stream,终止操作操作ForEach会把Stream从新汇聚起来, 流的惰性求值体现在哪里呢? 就是说,只要Stream没有碰到终止操作,我们添加在它身上的中间操作都不会被执行, 就像上面,我们把forEach()去嗲,text不会被打印
另外,添加的终止操作是forEach,这意味着她会遍历全部的元素,每一个Stream都会尝试被我们的中间操作处理; 但是,不一定一直是这个样,若我们把forEach替换成 findFirst(), 毫无疑问,只要出现一个单位的stream,成功被全部的中间操作处理,操作就停止了
这也是流的执行流程,并不是说我们在中间添加100个中间操作,流中的每一个单位Stream都得循环100次再执行终止操作, 相反,只有一个循环,这个100个中间组成的一个循环
流陷阱
流是一次性的,流被使用后,不能重复使用,但是如果我们调用Stream的中间操作返回了新的Stream,却不出现异常