LRU:least recently used
1. 设计LRU算法
首先要接收一个 capacity 参数作为缓存的最大容量,然后实现两个 API,一个是 put(key, val) 方法存入键值对,另一个是 get(key) 方法获取 key 对应的 val,如果 key 不存在则返回 -1。
注意:get 和 put 方法必须都是 $O(1)$ 的时间复杂度。
put时应该在队头,get时替换到队头,delete时删除队尾数据。
一个例子:
/* 缓存容量为 2 */ LRUCache cache = new LRUCache(2); // 你可以把 cache 理解成一个队列 // 假设左边是队头,右边是队尾 // 最近使用的排在队头,久未使用的排在队尾 // 圆括号表示键值对 (key, val) cache.put(1, 1); // cache = [(1, 1)] cache.put(2, 2); // cache = [(2, 2), (1, 1)] cache.get(1); // 返回 1 // cache = [(1, 1), (2, 2)] // 解释:因为最近访问了键 1,所以提前至队头 // 返回键 1 对应的值 1 cache.put(3, 3); // cache = [(3, 3), (1, 1)] // 解释:缓存容量已满,需要删除内容空出位置 // 优先删除久未使用的数据,也就是队尾的数据 // 然后把新的数据插入队头 cache.get(2); // 返回 -1 (未找到) // cache = [(3, 3), (1, 1)] // 解释:cache 中不存在键为 2 的数据 cache.put(1, 4); // cache = [(1, 4), (3, 3)] // 解释:键 1 已存在,把原始值 1 覆盖为 4 // 不要忘了也要将键值对提前到队头
2. 设计
总结点:查找和插入速度快、删除快,数据有顺序
结合hash表查找快和链表插入删除快,我们构造哈希链表结构。
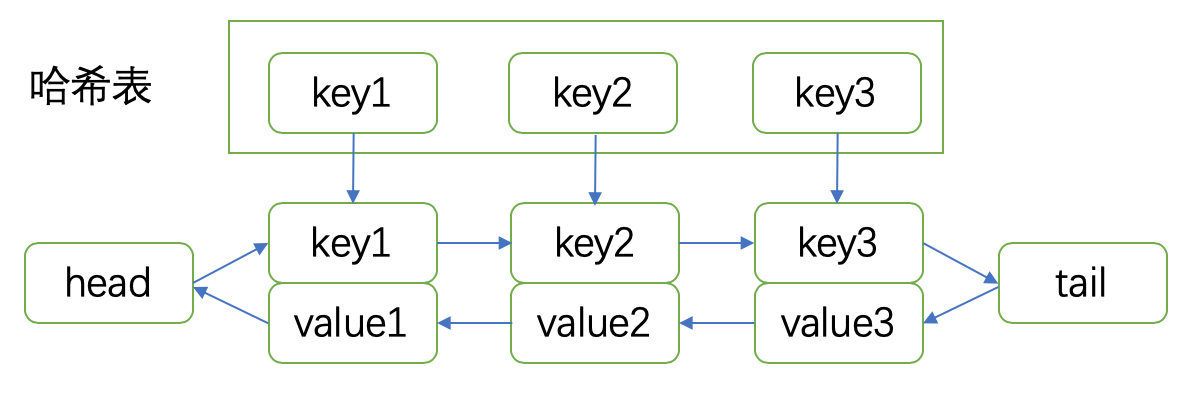
3. 代码实现
a 定义双链表节点类型
1 class Node { 2 public int key, value; 3 public Node next, prev; 4 public Node(int k, int v) { 5 this.key = k; 6 this.value = v; 7 } 8 }
b 实现双链表的操作
使用双链表的原因:我们需要删除操作。删除一个节点不仅需要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 $O(1)$。
1 class DoubleList { 2 // 在链表头部添加节点 x,时间 O(1) 3 public void addFirst(Node x); 4 5 // 删除链表中的 x 节点(x 一定存在),不存在返回-1 6 // 由于是双链表且给的是目标 Node 节点,时间 O(1) 7 public void remove(Node x); 8 9 // 删除链表中最后一个节点,并返回该节点,时间 O(1) 10 public Node removeLast(); 11 12 // 返回链表长度,时间 O(1) 13 public int size(); 14 }
c 实现代码
1 class LRUCache { 2 // key -> Node(key, value) 3 private HashMap<Integer, Node> map; 4 // Node(k1, v1) <-> Node(k2, v2)... 5 private DoubleList cache; 6 // 最大容量 7 private int cap; 8 9 public LRUCache(int capacity) { 10 this.cap = capacity; 11 map = new HashMap<>(); 12 cache = new DoubleList(); 13 } 14 15 public int get(int key) { 16 if (!map.containsKey(key)) 17 return -1; 18 int val = map.get(key).val; 19 // 利用 put 方法把该数据提前 20 put(key, val); 21 return val; 22 } 23 24 public void put(int key, int val) { 25 // 先把新节点 x 做出来 26 Node x = new Node(key, val); 27 28 if (map.containsKey(key)) { 29 // 删除旧的节点,新的插到头部 30 cache.remove(map.get(key)); 31 cache.addFirst(x); 32 // 更新 map 中对应的数据 33 map.put(key, x); 34 } else { 35 if (cap == cache.size()) { 36 // 删除链表最后一个数据 37 Node last = cache.removeLast(); 38 map.remove(last.key); 39 //这一步也说明了,在Node中存储key的原因 40 } 41 // 直接添加到头部 42 cache.addFirst(x); 43 map.put(key, x); 44 } 45 } 46 }