前言
其实multiprocessing模块与threading模块的接口都非常相似,但是有一些地方有一些细微差别。所以本文是基于前面的threading模块的一些知识对multiprocessing模块进行讲解的。
他们的主要区别有以下几点
1.创建子进程的方式针对不同平台有着差异化
2.关于守护线程的设置接口是
setDaemon(True),而关于守护进程的接口是deamon = True3.
multiprocessing模块下的获取进程名与设置进程名没有threading模块下的getName()和setName(),而是直接采取属性name进行操作4.多进程中数据共享不能使用普通的
queue模块下提供的队列进行数据共享,而应使用multiprocessing中提供的Queue5.
multiprocessing模块下中提供的Queue先进先出队列没有task_done()与join(),他们都在JoinableQueue中,并且该模块下没有提供LifoQueue后进先出队列与PriorityQueue优先级队列
多进程与多线程工作的区别
多线程工作方式
多线程的工作方式实际上在第一篇的时候,我们已经说过了。因为线程必须存在于进程之中,是最小的执行单元,所以你可以将它如此理解:
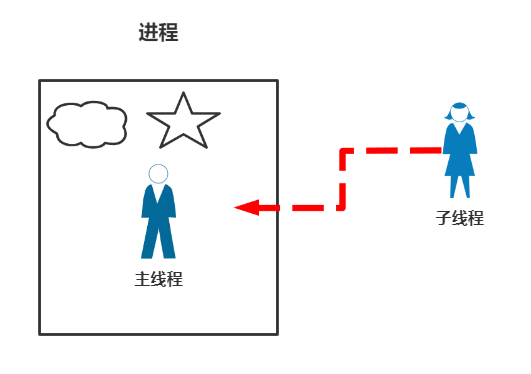
其实就是不断的往进程这个小房间加人,那么它的优点如下:
开一条新的线程比开一条新的进程开销要小很多
并且对于线程的切换来说代价也要小很多
多条线程共有该进程下的所有资源,数据共享比较容易实现
而CPython由于GIL锁的设定,所以它的多线程是残缺不全的,因此在很多时候我们依然要用到多进程,虽然这种情况比较少。
多进程工作方式
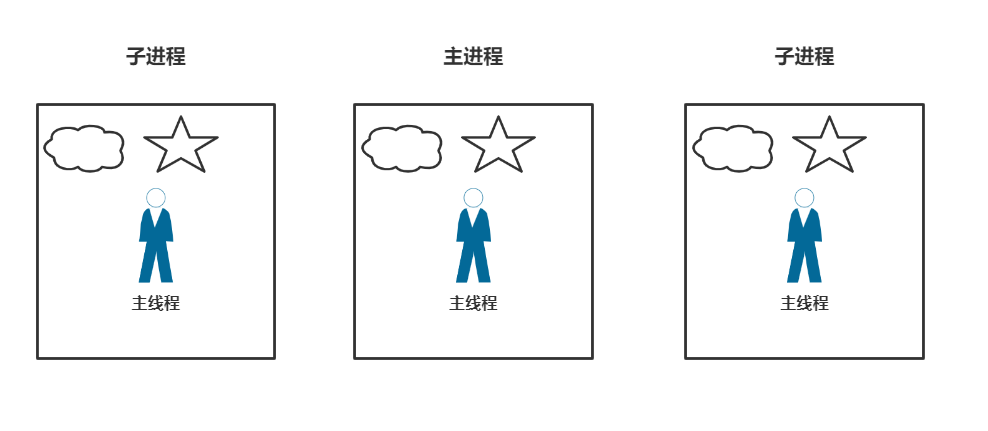
其实就是不断的造出一模一样的小房间,那么它的优点如下:
虽然说,新开一条进程比新开一条线程的代价大很多,但是由于CPython中GIL锁的设定想在多线程的情况下实现并行是不可能的,只有多进程才能够实现并行。
可以说是唯一优点了,但是我们依然要学习一下multiprocessing模块,它的学习代价并不是很大,所以接下来正式进入multiprocessing模块的学习。
基本使用
针对不同平台的进程启动方式
对于进程启动方式来说,其实multiprocessing模块中对于不同平台下有不同的启动方式。如下:
spawn:这玩意儿相当于创建了一个新的解释器进程,对比其他两种方法,这种方法速度上比较慢,但是它是Windows平台下默认的启动方式(Unix系统下可用)。并且在windows平台下,我们应该在if __name__ == '__main__'下进行新进程的启动。但是我依然认为不管在哪个平台下不论线程还是进程都应该在if __name__ == '__main__'这条语句下启动。
fork:这种启动方式是通过os.fork()来产生一个新的解释器分叉,是Unix系统的默认启动方式。
forkserver:这个我也看不太明白,直接把官方文档搬过来。如果有懂的大神可以解释一下。程序启动并选择
forkserver启动方法时,将启动服务器进程。从那时起,每当需要一个新进程时,父进程就会连接到服务器并请求它分叉一个新进程。分叉服务器进程是单线程的,因此使用 可在Unix平台上使用,支持通过Unix管道传递文件描述符。
import multiprocessing as mp def foo(q): q.put('hello') if __name__ == '__main__': # <--- 强烈注意!在windows平台下开多进程一定要在该条语句之下,否则会抛出异常!! mp.set_start_method('spawn') # 选择启动方式 q = mp.Queue() # 实例化出用于进程间数据共享的管道 p = mp.Process(target=foo, args=(q,)) p.start() # 启动进程任务,等待CPU调度执行 print(q.get()) # 从管道中拿出数据 p.join() # 阻塞至子进程运行完毕
实例化Process类创建子进程
其实感觉上面的方法都已经将本章要写的内容举例了一个七七八八,但是我们接着往下看。与threading模块中创建多线程的方式一样,multiprocessing模块创建多进程的方式也有两种,所以我们将之前的示例拿过来直接改一改就好。
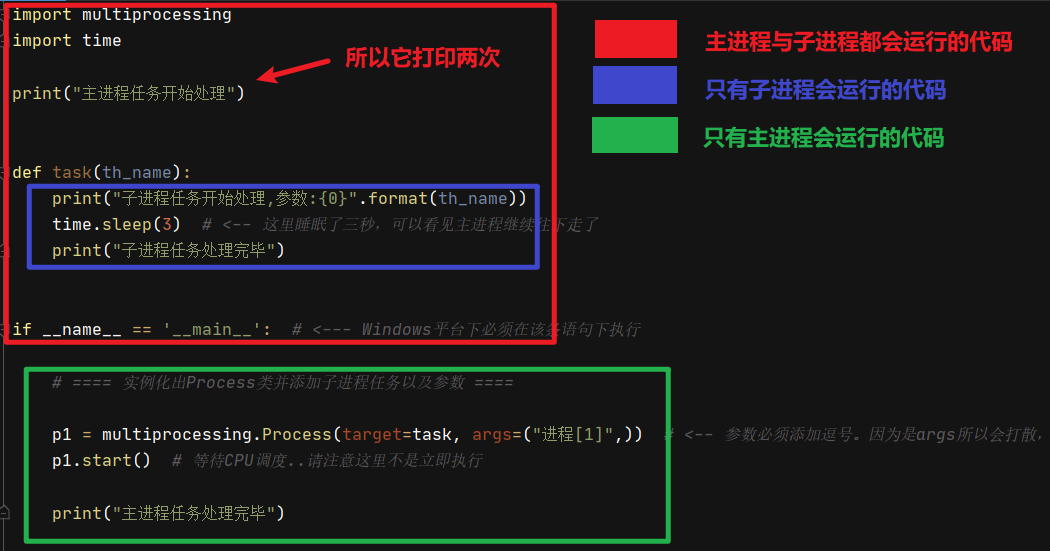
import multiprocessing import time print("主进程任务开始处理") def task(th_name): print("子进程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子进程任务处理完毕") if __name__ == '__main__': # <--- Windows平台下必须在该条语句下执行 # ==== 实例化出Process类并添加子进程任务以及参数 ==== p1 = multiprocessing.Process(target=task, args=("进程[1]",)) # <-- 参数必须添加逗号。因为是args所以会打散,如果不加逗号则不能进行打散会抛出异常 p1.start() # 等待CPU调度..请注意这里不是立即执行 print("主进程任务处理完毕") # ==== 执行结果 ==== """ 主进程任务开始处理 主进程任务处理完毕 主进程任务开始处理 子进程任务开始处理,参数:进程[1] 子进程任务处理完毕 """
这里我们看执行结果,主进程任务开始处理打印了两次,而主进程任务处理完毕打印了一次,这是为什么呢?由于我们是在Windows平台下,所以它默认的进程启动方式为spawn,即创建了一个新的解释器进程并开始执行,所以上面的主进程任务开始处理就打印了两次,一次是主进程,一次是新创建的子进程。而下面由于if __name__ == '__main__':这条语句,子进程并不会执行该语句下面的代码块,所以主进程任务处理完毕就只打印了一次。
自定义类继承Process并覆写run方法
import multiprocessing import time print("主进程任务开始处理") class Processing(multiprocessing.Process): """自定义类""" def __init__(self, th_name): self.th_name = th_name super(Processing, self).__init__() def run(self): print("子进程任务开始处理,参数:{0}".format(self.th_name)) time.sleep(3) print("子进程任务处理完毕") if __name__ == '__main__': p1 = Processing("进程[1]") p1.start() # 等待CPU调度..请注意这里不是立即执行 print("主进程任务处理完毕") # ==== 执行结果 ==== """ 主进程任务开始处理 主进程任务处理完毕 主进程任务开始处理 子进程任务开始处理,参数:进程[1] 子进程任务处理完毕 """
multiprocessing方法大全
multiprocessing模块中的方法参考了thrading模块中的方法。但是我们一般用下面两个方法就够了,他们都可以拿到具体的进程对象。
| multiprocessing模块方法大全 | |
|---|---|
| 方法/属性名称 | 功能描述 |
| multiprocessing.active_children() | 查看当前进程存活了的所有子进程对象,以列表形式返回。 |
| multiprocessing.current_process() | 获取当前进程对象。 |
| 好伙伴os模块 | |
|---|---|
| 方法/属性名称 | 功能描述 |
| os.getpid() | 返回进程ID。 |
| os.getppid() | 返回当前进程的父进程ID。 |
进程对象方法大全
| 进程对象方法大全(即Process类的实例对象) | |
|---|---|
| 方法/属性名称 | 功能描述 |
| start() | 启动进程,该方法不会立即执行,而是告诉CPU自己准备好了,可以随时调度,而非立即启动。 |
| run() | 一般是自定义类继承Process类并覆写的方法,即线程的详细任务逻辑。 |
| join(timeout=None) | 主进程默认会等待子进程运行结束后再继续执行,timeout为等待的秒数,如不设置该参数则一直等待。 |
| name | 可以通过 = 给该进程设置一个通俗的名字。如直接使用该属性则返回该进程的默认名字。 |
| is_alive() | 查看进程是否存活,返回布尔值。 |
| daemon | 可以通过 = 给该进程设置一个守护进程。如直接使用该属性则是查看进程是否为一个守护进程,返回布尔值。默认为False。 |
| pid | 返回进程ID。在生成该进程之前,这将是 None 。 |
| exitcode | 子进程的退出代码。如果进程尚未终止,这将是 None 。负值 -N 表示子进程被信号 N 终止。 |
| authkey | 进程的身份验证密钥(字节字符串)。 |
| sentinel | 系统对象的数字句柄,当进程结束时将变为 "ready" 。 |
| terminate() | 终止进程。 |
| kill() | 同上 |
| close() | 关闭 |
| 注意 | |
守护进程daemon
import multiprocessing import time print("主进程任务开始处理") def task(th_name): print("子进程任务开始处理,参数:{0}".format(th_name)) time.sleep(3) print("子进程任务处理完毕") if __name__ == '__main__': p1 = multiprocessing.Process(target=task, args=("进程[1]",)) p1.daemon = True # <-- 设置进程对象p1为守护进程,注意这一步一定要放在start之前。 p1.start() # 等待CPU调度..请注意这里不是立即执行 time.sleep(2) print("主进程任务处理完毕") # ==== 执行结果 ==== # print("子进程任务处理完毕") 可以看到该句没有执行 """ 主进程任务开始处理 主进程任务开始处理 子进程任务开始处理,参数:进程[1] 主进程任务处理完毕 """
设置与获取进程名
import multiprocessing import time print("主进程任务开始处理") def task(th_name): print("子进程任务开始处理,参数:{0}".format(th_name)) obj = multiprocessing.current_process() # 获取当前进程对象 print("获取当前的进程名:{0}".format(obj.name)) print("开始设置进程名") obj.name = "yyy" print("获取修改后的进程名:{0}".format(obj.name)) time.sleep(3) print("子进程任务处理完毕") if __name__ == '__main__': # ==== 第一步:实例化出Process类并添加子进程任务以及参数 ==== t1 = multiprocessing.Process(target=task, args=("进程[1]",),name="xxx") t1.start() # 等待CPU调度..请注意这里不是立即执行 print("主进程名:",multiprocessing.current_process().name) # 直接使用属性 name print("主进程任务处理完毕") # ==== 执行结果 ==== """ 主进程任务开始处理 主进程名: MainProcess 主进程任务处理完毕 主进程任务开始处理 子进程任务开始处理,参数:进程[1] 获取当前的进程名:xxx 开始设置进程名 获取修改后的进程名:yyy 子进程任务处理完毕 """
锁相关演示
锁的使用和threading模块中锁的使用相同,所以我们举例一个Lock锁即可。
import multiprocessing lock = multiprocessing.Lock() # 实例化同步锁对象 # 注意!!! 在Windows平台下,我们应该将锁的实例化放在上面,这样子进程才能拿到锁对象。否则就会抛出异常!!!或者也可以将锁对象传入当做形参进行传入,二者选其一 num = 0 def add(): lock.acquire() # 上锁 global num for i in range(10000000): # 一千万次 num += 1 lock.release() # 解锁 def sub(): lock.acquire() # 上锁 global num for i in range(10000000): # 一千万次 num -= 1 lock.release() # 解锁 if __name__ == '__main__': t1 = multiprocessing.Process(target=add, ) t2 = multiprocessing.Process(target=sub, ) t1.start() t2.start() t1.join() t2.join() print("最终结果:", num) # ==== 执行结果 ==== 三次采集 """ 最终结果: 0 最终结果: 0 最终结果: 0 """


from multiprocessing import Process, Lock def f(l, i): l.acquire() try: print('hello world', i) finally: l.release() if __name__ == '__main__': lock = Lock() # 将锁实例化后传入 for num in range(10): Process(target=f, args=(lock, num)).start()
三种进程数据共享的方式
multiprocessing.Queue
这里一定要使用multiprocessing中的Queue,如果你想用队列中的task_done()与join()方法,你应该导入JoinableQueue这个队列。
| multiprocessing.Queue方法大全 | |
|---|---|
| 方法名称 | 功能描述 |
| Queue.qsize() | 返回当前队列的大小 |
| Queue.empty() | 判断当前队列是否为空 |
| Queue.full() | 判断当前队列是否已满 |
| Queue.put(item, block=True, timeout=None) | 将item放入队列中,block参数为如果要操作的队列目前已满是否阻塞,timeout为超时时间。 |
| Queue.put_nowait(item) | 相当于 put(item, False),如果操作的队列已满则不进行阻塞,而是抛出Full异常。 |
| Queue.get(block=True, timeout=None) | 将项目从队列中取出,block参数为如果要操作的队列目前为空是否阻塞,timeout为超时时间。 |
| Queue.get_nowait() | 相当于 get(False),如果要操作的队列为空则不进行阻塞,而是抛出Empty异常。 |
| Queue.close() | 指示当前进程将不会再往队列中放入对象。一旦所有缓冲区中的数据被写入管道之后,后台的线程会退出。这个方法在队列被gc回收时会自动调用。 |
| Queue.join_thread() | 等待后台线程。这个方法仅在调用了 |
| Queue.cancel_join_thread() | 防止 |
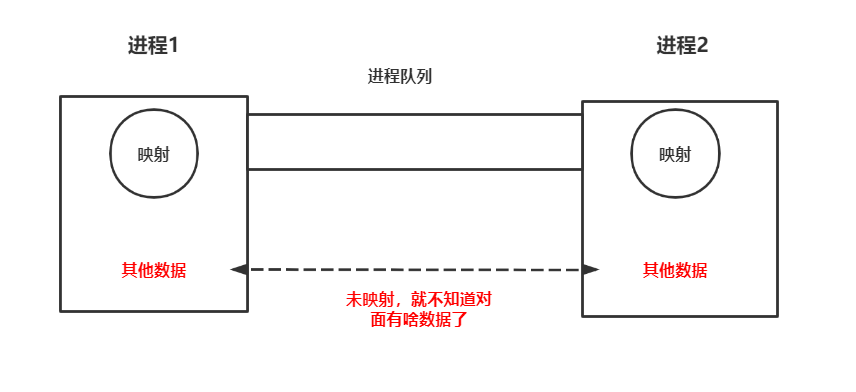
进程队列multiprocessing.Queue不同于线程队列queue.Queue,进程队列的消耗和底层实现比线程队列的要复杂许多。还是因为各进程之间不能共享任何数据,所以只能通过映射的方式来传递数据。进程队列multiprocessing.Queue作为数据安全类型的数据结构,放在多进程中做通信使用是非常合适的,但是同时它的消耗也是非常大的,能不使用则尽量不要使用。
import time import multiprocessing from multiprocessing import Queue,JoinableQueue def task_1(q): print("正在装东西..") time.sleep(3) q.put("玫瑰花") # 正在装东西 q.task_done() # 通知对方可以取了 def task_2(q): q.join() # 阻塞等待通知,接到通知说明队列里里有东西了。 print("取到了",q.get()) # 取东西 if __name__ == '__main__': q = JoinableQueue(maxsize=5) # 实例化队列 t1 = multiprocessing.Process(target=task_1,args=(q,),name="小明") # 将队列传进子进程任务中 t2 = multiprocessing.Process(target=task_2,args=(q,),name="小花") t1.start() t2.start() # ==== 执行结果 ==== """ 正在装东西.. 取到了 玫瑰花 """
什么线程队列queue.Queue不能做到进程间数据共享呢,这是因为进程队列multiprocessing.Queue会采取一种映射的方式来同步数据,所以说进程队列的资源消耗比线程队列要庞大很多。线程中所有信息共享,所以线程队列根本不需要映射关系。进程队列只是告诉你可以这样使用它达到进程间的数据共享,但是并不推荐你滥用它。
multiprocessing.Pipe
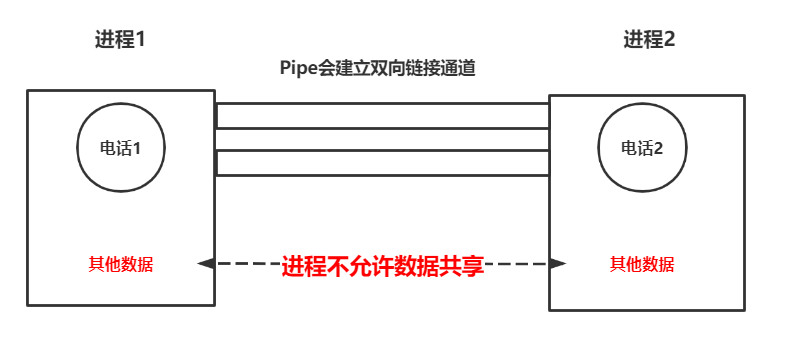
除开使用进程队列来实现进程间的通信,multiprocessing还提供了Pipe管道来进行通信。他的资源消耗较少并且使用便捷,但是唯一的缺点便是只支持点对点。
Pipe有点类似socket通信。但是比socket通信更加简单,它不需要去做字符串处理字节,先来看一个实例:
import multiprocessing from multiprocessing import Pipe def task_1(conn1): conn1.send("hello,我是task1") print(conn1.recv()) def task_2(conn2): print(conn2.recv()) conn2.send("我收到了,我是task2") if __name__ == '__main__': conn1,conn2 = Pipe() # 创建两个电话 p1 = multiprocessing.Process(target=task_1,args=(conn1,)) # 一人一部电话 p2 = multiprocessing.Process(target=task_2,args=(conn2,)) p1.start() p2.start() p1.join() p2.join() # ==== 执行结果 ==== """ hello,我是task1 我收到了,我是task2 """
multiprocessing.Manager
除了进程队列multiprocessing.Queue,管道Pipe,multiprocessing还提供了Manager作为共享变量来提供使用,但是这种方式是不应该被直接使用的因为它本身相较于进程队列Queue是数据不安全的。当多个进程同时修改一个共享变量势必导致结果出现问题,所以要想使用共享变量还得使用multiprocessin提供的进程锁才行。
Manager类是数据不安全的;
Mangaer类支持的类型非常多,如:value, Array, List, Dict, Queue(进程池通信专用), Lock等。
Mangaer实现了上下文管理器,可使用with语句创建多个对象。具体使用方法我们来看一下:
import multiprocessing from multiprocessing import Manager def task_1(dic): dic["task_1"] = "大帅哥" def task_2(dic): dic["task_2"] = "大美女" print(dic.get("task_1")) if __name__ == '__main__': with Manager() as m: # !!!!! 注意 !!!!!!! 如果对 Manager()中的数据类型进行频繁的操作,而进程又特别多的时候,请使用 Rlock 锁进行处理,这有可能引发线程不安全!!! dic = m.dict() # 实例化出了一个字典,除此之外还有很多其他的数据类型 p1 = multiprocessing.Process(target=task_1,args=(dic,)) # 将字典传进来 p2 = multiprocessing.Process(target=task_2,args=(dic,)) p1.start() # 启动一定要放在with之后 p2.start() p1.join() p2.join() # ==== 执行结果 ==== """ 大帅哥 """
import multiprocessing from multiprocessing import Manager def task_1(dic): for i in range(1000): dic["count"] += 1 def task_2(dic): for i in range(1000): dic["count"] -= 1 if __name__ == '__main__': with Manager() as m: # !!!!! 注意 !!!!!!! 如果对 Manager()中的数据类型进行频繁的操作,而进程又特别多的时候,请使用 Rlock 锁进行处理,这有可能引发线程不安全!!! dic = m.dict({"count":0}) # 实例化出了一个字典,除此之外还有很多其他的数据类型 p1 = multiprocessing.Process(target=task_1,args=(dic,)) # 传字典 p2 = multiprocessing.Process(target=task_2,args=(dic,)) p1.start() p2.start() p1.join() p2.join() print(dic) # ==== 执行结果 ==== """ {'count': -23} """
import multiprocessing from multiprocessing import Manager from multiprocessing import RLock def task_1(dic,lock): with lock: for i in range(1000): dic["count"] += 1 def task_2(dic,lock): with lock: for i in range(1000): dic["count"] -= 1 if __name__ == '__main__': lock = RLock() # 实例化锁 with Manager() as m: # !!!!! 注意 !!!!!!! 如果对 Manager()中的数据类型进行频繁的操作,而进程又特别多的时候,请使用 Rlock 锁进行处理,这有可能引发线程不安全!!! dic = m.dict({"count":0}) # 实例化出了一个字典,除此之外还有很多其他的数据类型 p1 = multiprocessing.Process(target=task_1,args=(dic,lock,)) # 传字典,传锁 p2 = multiprocessing.Process(target=task_2,args=(dic,lock,)) p1.start() p2.start() p1.join() p2.join() print(dic) # ==== 执行结果 ==== """ {'count': 0} """