来自:
https://www.zhihu.com/question/41540197
https://www.douban.com/note/518998773/
链接:https://www.zhihu.com/question/41540197/answer/91698989
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在图像中,尤其是分类问题中应用AP,是一种评价ranking方式好不好的指标:
举例来说,我有一个两类分类问题,分别5个样本,如果这个分类器性能达到完美的话,ranking结果应该是+1,+1,+1,+1,+1,-1,-1,-1,-1,-1.
但是分类器预测的label,和实际的score肯定不会这么完美。按照从大到小来打分,我们可以计算两个指标:precision和recall。比如分类器认为打分由高到低选择了前四个,实际上这里面只有两个是正样本。此时的recall就是2(你能包住的正样本数)/5(总共的正样本数)=0.4,precision是2(你选对了的)/4(总共选的)=0.5.
图像分类中,这个打分score可以由SVM得到:s=w^Tx+b就是每一个样本的分数。
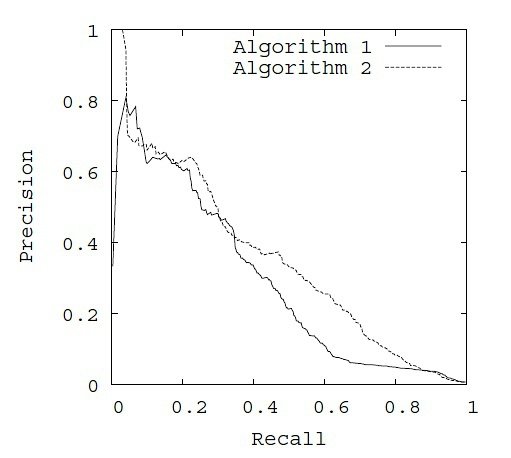
从上面的例子可以看出,其实precision,recall都是选多少个样本k的函数,很容易想到,如果我总共有1000个样本,那么我就可以像这样计算1000对P-R,并且把他们画出来,这就是PR曲线:
这里有一个趋势,recall越高,precision越低。这是很合理的,因为假如说我把1000个全拿进来,那肯定正样本都包住了,recall=1,但是此时precision就很小了,因为我全部认为他们是正样本。recall=1时的precision的数值,等于正样本所占的比例。
所以AP,average precision,就是这个曲线下的面积,这里average,等于是对recall取平均。而mean average precision的mean,是对所有类别取平均(每一个类当做一次二分类任务)。现在的图像分类论文基本都是用mAP作为标准。
1.使用AP会比accuracy要合理。对于accuracy,如果有9个负样本和一个正样本,那么即使分类器什么都不做全部判定为负样本accuracy也有90%。但是对于AP,recall=1那个点precision会掉到0.1.曲线下面积就会反映出来。
2.在实际中计算AP时,如果是matlab的话,可以直接调用vl_feat中的vl_pr:VLFeat - Tutorials这里面详细地给出了概念的解释以及计算方式。
在机器学习中,ROC(Receiver Operator Characteristic)曲线被广泛应用于二分类问题中来评估分类器的可信度,但是当处理一些高度不均衡的数据集时,PR曲线能表现出更多的信息,发现更多的问题。
1.ROC曲线和PR曲线是如何画出来的?
在二分类问题中,分类器将一个实例的分类标记为是或否,这可以用一个混淆矩阵来表示。混淆矩阵有四个分类,如下表:
actual positive actual negative
predicted positive TP FP
predicted negative FN TN
其中,列对应于实例实际所属的类别,行表示分类预测的类别。
TP(True Positive):指正确分类的正样本数,即预测为正样本,实际也是正样本。
FP(False Positive):指被错误的标记为正样本的负样本数,即实际为负样本而被预测为正样本,所以是False。
TN(True Negative):指正确分类的负样本数,即预测为负样本,实际也是负样本。
FN(False Negative):指被错误的标记为负样本的正样本数,即实际为正样本而被预测为负样本,所以是False。
TP+FP+TN+FN:样本总数。
TP+FN:实际正样本数。
TP+FP:预测结果为正样本的总数,包括预测正确的和错误的。
FP+TN:实际负样本数。
TN+FN:预测结果为负样本的总数,包括预测正确的和错误的。
这里面的概念有些绕,需要慢慢理解,/(ㄒoㄒ)/~~。以这四个基本指标可以衍生出多个分类器评价指标,如下图:

在PR曲线中,以Recall(貌似翻译为召回率或者查全率)为x轴,Precision为y轴。Recall与TPR的意思相同,而Precision指正确分类的正样本数占总正样本的比例。如下图: