Food-11 实验笔记
数据介绍
食物类别:
Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.
面包,乳制品,甜点,鸡蛋,油炸食品,肉类,面条/意大利面,米饭,海鲜,汤,蔬菜/水果。
0 ,1 , 2, 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10
其中,
Training set: 9866张
Validation set: 3430张
Testing set: 3347张
实现过程
1)预处理数据:
cv2读数据,resize数据成128*128。做成Dataset形式,放到DataLoader中(方便shuffle、切batch)
2)模型:
CNN接FC。其中CNN的结构如下:


class Classifier(nn.Module): def __init__(self): # super继承父类 super(Classifier, self).__init__() # conv2d(in_channels, out_channels, kernel_size, stride, padding) # MaxPool2d(kernel_size, stride, padding) # input维度[3,128,128] self.cnn = nn.Sequential( nn.Conv2d(3, 64, 3, 1, 1), #[64, 128, 128] nn.BatchNorm2d(64), nn.ReLU(), nn.MaxPool2d(2, 2, 0), #[64, 64, 64] nn.Conv2d(64, 128, 3, 1, 1),#[128, 64, 64] nn.BatchNorm2d(128), nn.ReLU(), nn.MaxPool2d(2, 2, 0), #[128, 32, 32] nn.Conv2d(128, 256, 3, 1, 1),#[256, 32, 32] nn.BatchNorm2d(256), nn.ReLU(), nn.MaxPool2d(2, 2, 0),#[256, 16, 16] nn.Conv2d(256, 512, 3, 1, 1),#[512, 16, 16] nn.BatchNorm2d(512), nn.ReLU(), nn.MaxPool2d(2, 2, 0),#[512, 8, 8] nn.Conv2d(512, 512, 3, 1, 1),#[512, 8, 8] nn.BatchNorm2d(512), nn.ReLU(), nn.MaxPool2d(2, 2, 0),#[512, 4, 4] ) self.fc = nn.Sequential( nn.Linear(512*4*4, 1024), nn.ReLU(), nn.Linear(1024, 512), nn.Linear(512, 11) ) def forward(self, x): out = self.cnn(x) out = out.view(out.size()[0], -1) return self.fc(out)
3)训练:
对每个epoch,model train模式下,训练。model eval模式下,验证。不断调整超参。找到相对来说最好的参数后,将train与val数据集concatenate在一起再一起进行训练。将得到的模型保存下来。
4)测试:
把测试集丢到保存的模型中,并保存训练结果。
实现代码
本实验是台大李宏毅老师机器学习2020年的HW3
作业说明如下:
https://github.com/ziyeZzz/lhy_DL_Hw/blob/master/hw3_slides.pptx
code的official ref如下:
https://github.com/ziyeZzz/lhy_DL_Hw/blob/master/hw3_CNN.ipynb
自整理的code的ref如下:
https://github.com/ziyeZzz/machine_learning/blob/master/classification/Lihongyi-hw3-CNN-food11/hw3_food_classification.ipynb
调整过程
按原始official的实现方法,val acc可达69%
测试acc达到69%
[059/3000] 259.75 sec(s) Train Acc: 0.951449 Loss: 0.001090 | Val Acc: 0.696501 loss: 0.012728
[060/3000] 260.27 sec(s) Train Acc: 0.980134 Loss: 0.000519 | Val Acc: 0.686297 loss: 0.013414
测试1)如不使用transform
结果:会很快过拟合。测试acc达65%
[029/3000] 11.93 sec(s) Train Acc: 0.993108 Loss: 0.000260 | Val Acc: 0.636443 loss: 0.016154 [030/3000] 11.90 sec(s) Train Acc: 0.994831 Loss: 0.000174 | Val Acc: 0.634694 loss: 0.016754 [031/3000] 11.88 sec(s) Train Acc: 0.965234 Loss: 0.000840 | Val Acc: 0.588630 loss: 0.017759 [032/3000] 11.92 sec(s) Train Acc: 0.948713 Loss: 0.001185 | Val Acc: 0.552187 loss: 0.023395 [033/3000] 11.83 sec(s) Train Acc: 0.938476 Loss: 0.001462 | Val Acc: 0.612536 loss: 0.017101 [034/3000] 11.93 sec(s) Train Acc: 0.957125 Loss: 0.001032 | Val Acc: 0.598834 loss: 0.019387 [035/3000] 11.94 sec(s) Train Acc: 0.975066 Loss: 0.000582 | Val Acc: 0.647813 loss: 0.016691 [036/3000] 12.26 sec(s) Train Acc: 0.993513 Loss: 0.000197 | Val Acc: 0.646356 loss: 0.017769 [037/3000] 11.82 sec(s) Train Acc: 0.997567 Loss: 0.000124 | Val Acc: 0.523324 loss: 0.027722 [038/3000] 11.81 sec(s) Train Acc: 0.916988 Loss: 0.002157 | Val Acc: 0.520700 loss: 0.022304 [039/3000] 11.84 sec(s) Train Acc: 0.925502 Loss: 0.001917 | Val Acc: 0.603207 loss: 0.018548 [040/3000] 11.95 sec(s) Train Acc: 0.981756 Loss: 0.000470 | Val Acc: 0.621574 loss: 0.017166 [041/3000] 11.89 sec(s) Train Acc: 0.998480 Loss: 0.000076 | Val Acc: 0.654519 loss: 0.015744
测试2)transform时,把图片归一化到[-1,1],现在是[0,1]
实现方法:在transform中
transforms.ToTensor(), # 将图片转成tensor,并把数值normalize到[0,1]
transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5)),
[095/100] 15.06 sec(s) Train Acc: 0.981046 Loss: 0.000468 | Val Acc: 0.233236 loss: 0.060886 [096/100] 14.73 sec(s) Train Acc: 0.986317 Loss: 0.000316 | Val Acc: 0.262391 loss: 0.053779 [097/100] 14.72 sec(s) Train Acc: 0.991689 Loss: 0.000203 | Val Acc: 0.238192 loss: 0.062459 [098/100] 14.66 sec(s) Train Acc: 0.990979 Loss: 0.000229 | Val Acc: 0.239942 loss: 0.062005 [099/100] 14.59 sec(s) Train Acc: 0.995033 Loss: 0.000157 | Val Acc: 0.229446 loss: 0.070151 [100/100] 14.76 sec(s) Train Acc: 0.982870 Loss: 0.000433 | Val Acc: 0.173178 loss: 0.098251
val的结果如上所示,变得奇差无比,why????
我发现因为我val数据集没normalize到[-1,1]间,可能因为train和val数据分布不一致导致。那么对val也操作后:
果然好多了。。。。val的acc甚至可以达到70%
[045/100] 15.03 sec(s) Train Acc: 0.912528 Loss: 0.001948 | Val Acc: 0.665598 loss: 0.012324 [046/100] 15.29 sec(s) Train Acc: 0.894283 Loss: 0.002369 | Val Acc: 0.686297 loss: 0.010362 [047/100] 23.08 sec(s) Train Acc: 0.926110 Loss: 0.001675 | Val Acc: 0.655394 loss: 0.013134 [048/100] 24.21 sec(s) Train Acc: 0.941618 Loss: 0.001384 | Val Acc: 0.684548 loss: 0.012320 [049/100] 22.94 sec(s) Train Acc: 0.916278 Loss: 0.001910 | Val Acc: 0.638484 loss: 0.013741 [050/100] 19.86 sec(s) Train Acc: 0.931989 Loss: 0.001593 | Val Acc: 0.650437 loss: 0.013430 [051/100] 15.32 sec(s) Train Acc: 0.944456 Loss: 0.001276 | Val Acc: 0.665889 loss: 0.013202 [052/100] 15.09 sec(s) Train Acc: 0.947395 Loss: 0.001189 | Val Acc: 0.675510 loss: 0.012964 [053/100] 14.99 sec(s) Train Acc: 0.956416 Loss: 0.001025 | Val Acc: 0.635277 loss: 0.015925 [054/100] 15.16 sec(s) Train Acc: 0.932191 Loss: 0.001506 | Val Acc: 0.638484 loss: 0.016541 [055/100] 15.14 sec(s) Train Acc: 0.935029 Loss: 0.001551 | Val Acc: 0.676385 loss: 0.013396 [056/100] 15.22 sec(s) Train Acc: 0.951348 Loss: 0.001114 | Val Acc: 0.684840 loss: 0.012859 [057/100] 15.11 sec(s) Train Acc: 0.930570 Loss: 0.001630 | Val Acc: 0.644606 loss: 0.016157 [058/100] 15.23 sec(s) Train Acc: 0.965437 Loss: 0.000842 | Val Acc: 0.691254 loss: 0.013474 [059/100] 15.89 sec(s) Train Acc: 0.946382 Loss: 0.001232 | Val Acc: 0.667638 loss: 0.013778 [060/100] 17.95 sec(s) Train Acc: 0.968984 Loss: 0.000699 | Val Acc: 0.704665 loss: 0.012827 [061/100] 18.07 sec(s) Train Acc: 0.982060 Loss: 0.000444 | Val Acc: 0.694752 loss: 0.013444 [062/100] 18.07 sec(s) Train Acc: 0.976079 Loss: 0.000604 | Val Acc: 0.661516 loss: 0.018054
那么问题来了,什么时候把图片归一化到[0,1]之间,什么时候又需要归一化到[-1,1]之间呢?
测试3)convert成RGB会不会变好一些呢?
因为cv2默认读出来是BGR,显示图片会泛蓝。改成RGB的方法:
#在用cv2读出图片后,加上[2,1,0]把index倒过来 img = cv2.imread(os.path.join(data_dir, file)) img = img[:,:,[2,1,0]]
transform到[-1,1]之间后的结果
[050/100] 15.41 sec(s) Train Acc: 0.921650 Loss: 0.001845 | Val Acc: 0.695335 loss: 0.011956
[051/100] 15.33 sec(s) Train Acc: 0.944050 Loss: 0.001387 | Val Acc: 0.649563 loss: 0.014059
可以看到差不多50步的时候,就已经是70%的acc了。所以转不转RGB也并没有什么要紧的。因为已经做过BN了
测试4)画混淆矩阵看一下,是哪些类别容易弄错呢
import seaborn as sns from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt sns.set() f,ax=plt.subplots() y_true = [0,0,1,2,1,2,0,2,2,0,1,1] y_pred = [1,0,1,2,1,0,0,2,2,0,1,1] C2= confusion_matrix(y_true, y_pred, labels=[0, 1, 2]) print(C2) #打印出来看看 sns.heatmap(C2,annot=True,ax=ax) #画热力图 # 在实际代码中 # 在epoch循环中 if epoch==49: val_pred_y += val_pred val_real_y += data[1] # 数据处理成数组形式 val_real = [int(y.numpy()) for y in val_real_y] val_pred = [np.argmax(y.cpu().data.numpy()) for y in val_pred_y] # 然后开始画图 sns.set() f,ax=plt.subplots(figsize = (12, 10)) C2= confusion_matrix(val_real, val_pred, labels=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) #print(C2) #打印出来看看 sns.heatmap(C2,annot=True,ax=ax,linewidth=.5,cmap='YlGnBu') #画热力图 ax.set_title('confusion matrix') #标题 ax.set_xlabel('predict') #x轴 ax.set_ylabel('true') #y轴 #画出来就是下图所示啦
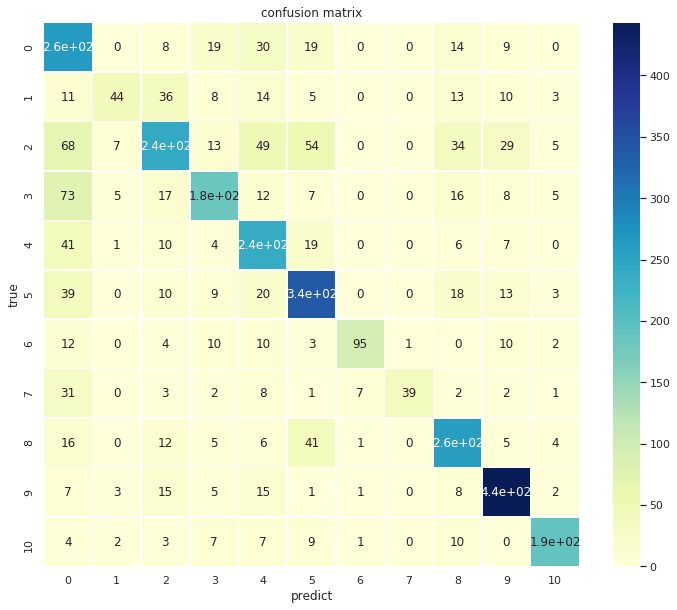
可以发现:
海鲜和肉类,面包和甜点、油炸食品等有重合。
这几类看图片确实会有一些重合。
通过上面几个尝试都可以看出,训练集是过拟合了。
测试5)加上dropout试一下
加了dropout后确实变好了,val的acc可到75%左右
[482/500] 15.93 sec(s) Train Acc: 0.994932 Loss: 0.000161 | Val Acc: 0.734402 loss: 0.013944 [483/500] 16.05 sec(s) Train Acc: 0.995844 Loss: 0.000114 | Val Acc: 0.748105 loss: 0.013561 [484/500] 16.03 sec(s) Train Acc: 0.996452 Loss: 0.000100 | Val Acc: 0.757726 loss: 0.013194 [485/500] 16.10 sec(s) Train Acc: 0.997162 Loss: 0.000073 | Val Acc: 0.744023 loss: 0.015371
目前实现方法:
在CNN层nn.ReLU前加dropout,然后FC层也加dropout,不过比例不同。CNN层dropout的比例更少(0.1),FC层更多(0.3)。因为FC层参数更多。
# 在CNN层ReLU前加dropout self.cnn = nn.Sequential( nn.Conv2d(3, 64, 3, 1, 1), #[64, 128, 128] nn.BatchNorm2d(64), nn.Dropout(0.1), nn.ReLU(), nn.MaxPool2d(2, 2, 0), #[64, 64, 64], ....., ....., ) # 在FC层 self.fc = nn.Sequential( nn.Linear(512*4*4, 1024), nn.Dropout(0.3), nn.ReLU(), nn.Linear(1024, 512), nn.Dropout(0.3), nn.Linear(512, 11) )
网上查的说,一般都是在FC层用dropout。一般不用于卷积层,因为在卷积层中图像相邻像素共享很多相同信息,如某些被删除,它们包含的信息仍可通过其他仍活动的相邻像素传递。简而言之,就是在CNN层加了也没用。
所以卷积层中的dropout只是增加了对噪声输入的鲁棒性,而不是在全连接层中观察到的模型平均效果。
测试6)那么试一下只在FC层加dropout
[496/500] 15.32 sec(s) Train Acc: 0.994628 Loss: 0.000129 | Val Acc: 0.750729 loss: 0.022423 [497/500] 15.36 sec(s) Train Acc: 0.996351 Loss: 0.000109 | Val Acc: 0.753936 loss: 0.021338 [498/500] 15.27 sec(s) Train Acc: 0.995642 Loss: 0.000103 | Val Acc: 0.748980 loss: 0.022345 [499/500] 15.12 sec(s) Train Acc: 0.996452 Loss: 0.000098 | Val Acc: 0.756268 loss: 0.022865 [500/500] 15.15 sec(s) Train Acc: 0.995642 Loss: 0.000205 | Val Acc: 0.756851 loss: 0.021429
效果和在CNN中也加了dropout的差不多。看来在CNN中加或不加,影响确实不大。
测试7)Dropout的超参数及位置再调整
两个ReLu的比例都设成0.5,或只保留在ReLu前的dropout,并把比例设为0.6
self.fc = nn.Sequential( nn.Linear(512*4*4, 1024), nn.Dropout(0.6), nn.ReLU(), nn.Linear(1024, 512), nn.Linear(512, 11) )
val差不多都是74%左右,也没有啥提升。
一般来说减少过拟合的步骤
- 添加更多数据
- 使用数据增强
- 使用泛化性能更佳的模型结构
- 添加正规化(多数情况下是 Dropout,L1 / L2正则化也有可能)
- 降低模型复杂性
那再试试第五个方法吧,降低模型复杂度试试:
-----------------