分析:
在某牙直播 > 颜值区网页打开浏览器的抓包工具 > 刷新网页或者点击下一页 进行抓包> >
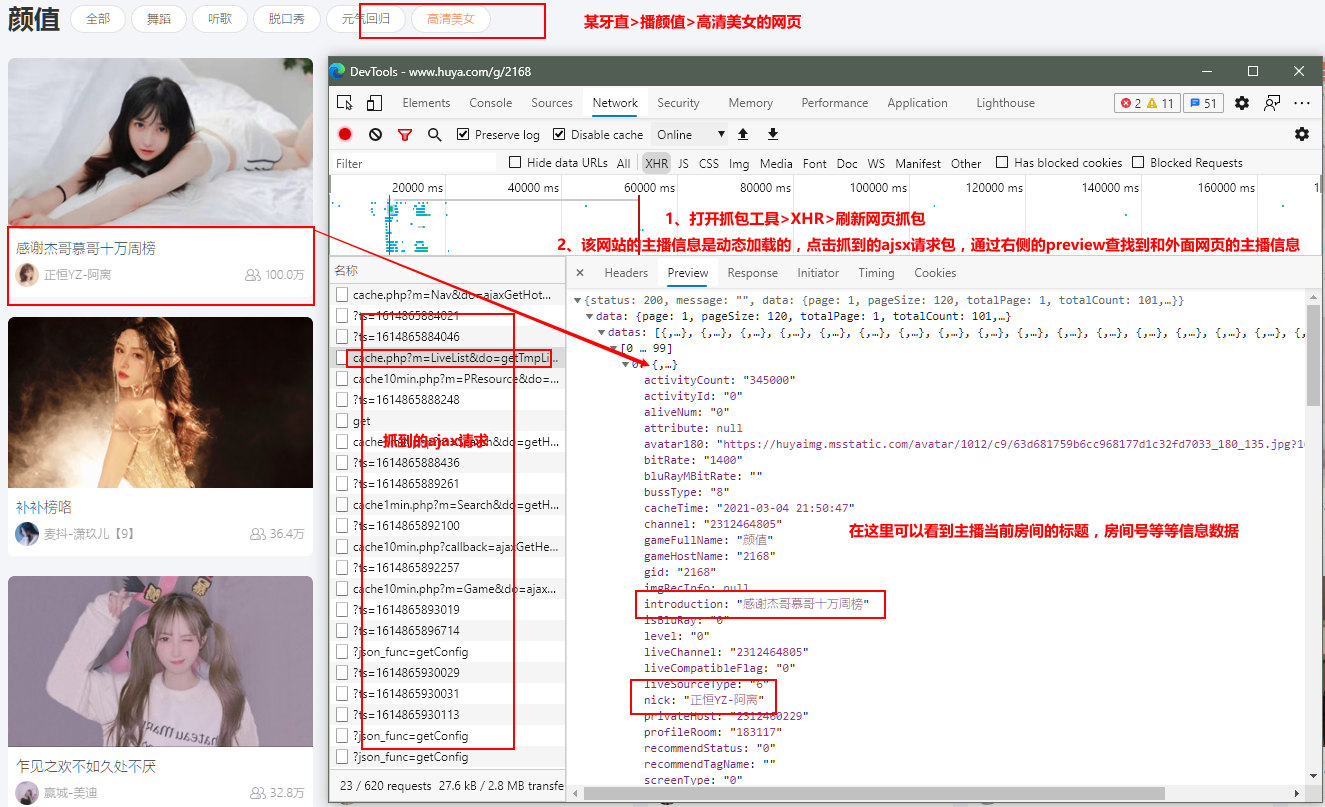
把里面有的url地址在浏览器打开,找出正确的主播直播间封面图片的地址:
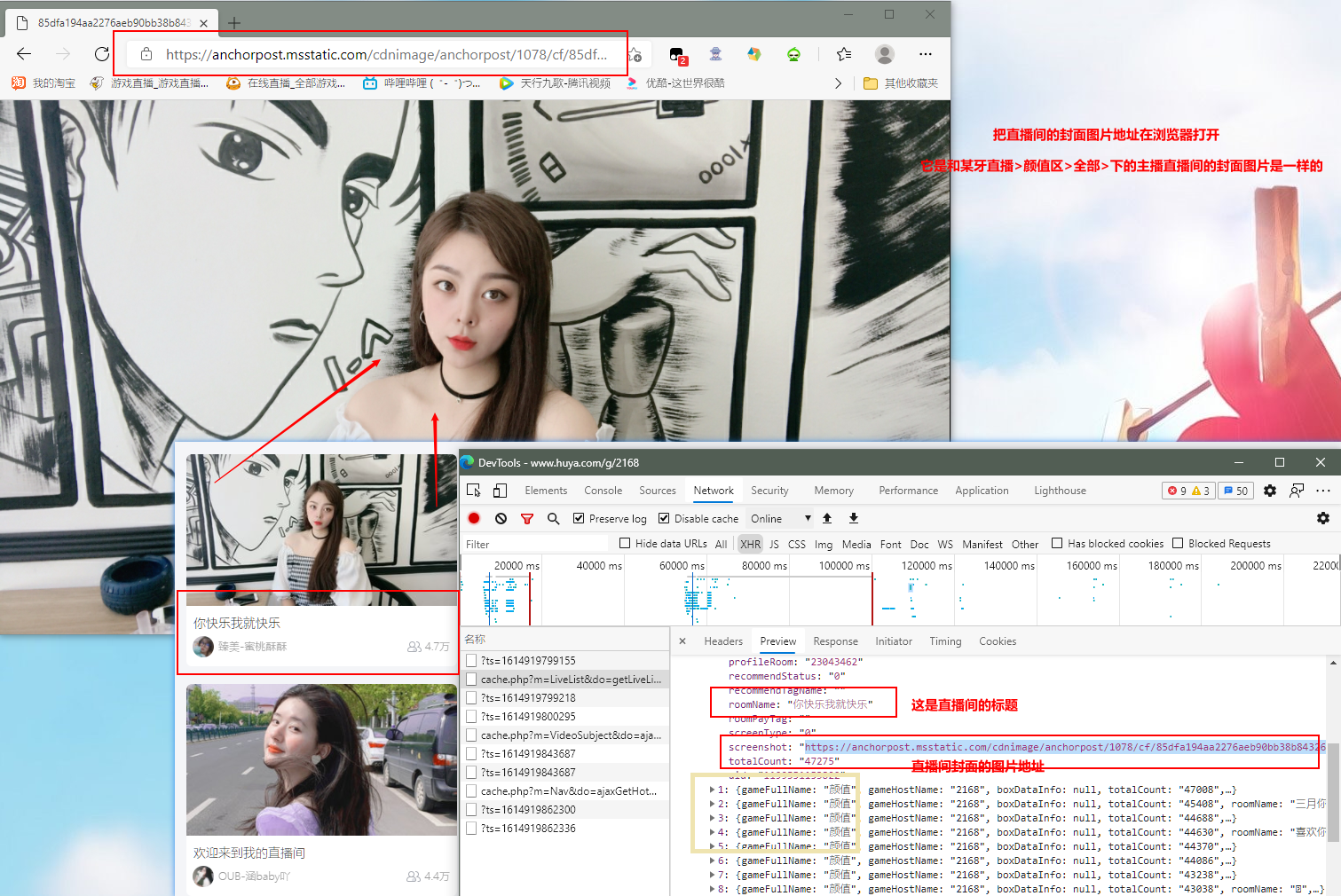
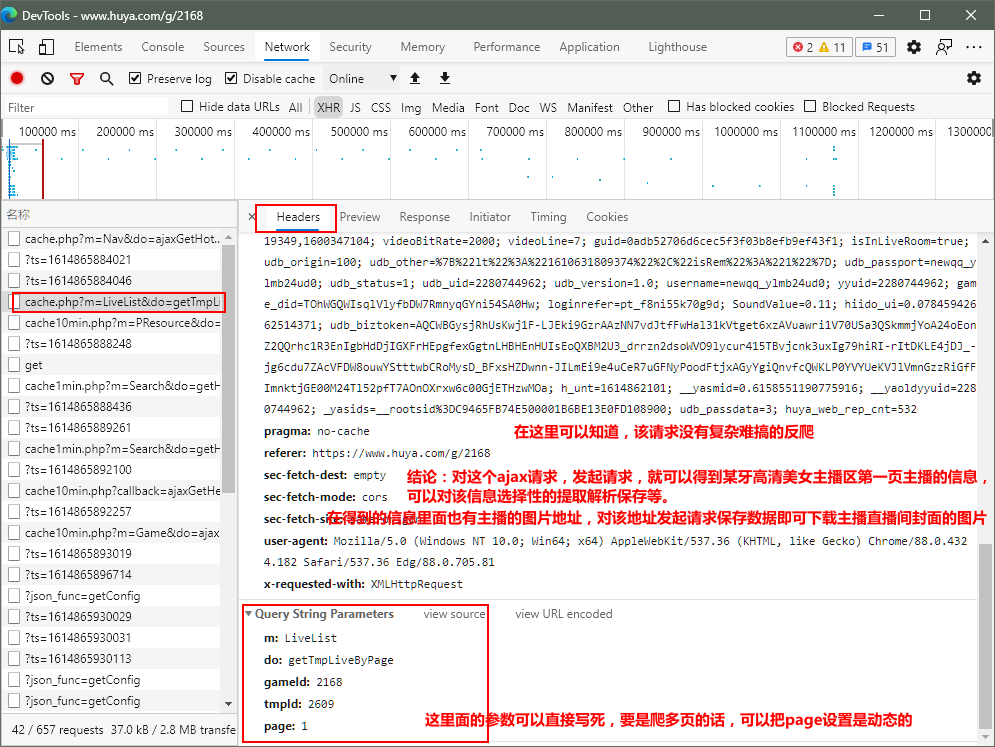
抓包分析结论:
代码实现部分:
颜值区首页当前主播的所有信息的ajax请求,没有复杂难搞的反爬,ajax请求url的请求变化的参数可以写死(要是下载多页的话,可以把页数的参数page动态化,可以抓取到第二页或者是第三页所以主播封面的图片)
由于ajax请求url的请求变化的参数不多,这里使用scrapy框架高效的下载某牙直播主播直播间封面的图片!
spiderName.py 爬虫文件部分的代码:
import scrapy
from huyaPro.items import HuyaproItem
class HuyaSpider(scrapy.Spider):
name = 'huya'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&page=1']#颜值区首页当前主播的所有信息的ajax请求url
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=2168&tagAll=0&page=%d'#设置颜值区主播下一页信息的请求通用url
pageNum = 2#设置页数是2
def parse(self, response):
dic_list = response.json()['data']['datas'] #数据解析,这里可以提前自己想要的
for dic in dic_list:
url = dic['screenshot']
# avatar180_url = dic['avatar180']
name = dic['nick']
profileRoom = dic['profileRoom']
png_name = name +'的直播间id:'+ profileRoom + '.png'#保存图片的命名(主播的昵称+直播间的房间号)
item = HuyaproItem()
item['url'] = url
item['name'] = name
item['profileRoom'] = profileRoom
item['png_name'] = png_name
yield item#提取到的数据提交给管道
if self.pageNum < 10:#手动请求获取到颜值区主播下一页所有主播的房间信息数据
new_url = format(self.url % self.pageNum)
self.pageNum += 1
yield scrapy.Request(url=new_url,callback=self.parse)
items.py代码:
import scrapy
class HuyaproItem(scrapy.Item):
url = scrapy.Field()
name = scrapy.Field()
profileRoom = scrapy.Field()
png_name = scrapy.Field()
pipelines.py代码:
from itemadapter import ItemAdapter
class HuyaproPipeline:#不用这个
def process_item(self, item, spider):
return item
from scrapy.pipelines.images import ImagesPipeline #提供了数据下载功能
import scrapy
class ImgsPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
try:
print('正在下载<{}>'.format(item['name']), '直播间封面图片...')
yield scrapy.Request(url=item['url'], meta={'item': item})
except Exception as i:#处理异常请求
print(i)
def file_path(self, request, response=None, info=None, *, item=None):
item = request.meta['item']
print('<{}>'.format(item['name']),'直播间的封面图片下载成功!')
filePath = item['png_name']
return filePath #返回保存图片的下载保存命名
def item_completed(self, results, item, info):
return item
settings.py 项目的配置文件设置:
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.52'
LOG_LEVEL = 'ERROR'
ROBOTSTXT_OBEY = False
IMAGES_STORE = './imgHuya'#保存图片文件夹名称
# 过期天数
IMAGES_EXPIRES = 5 #5天内抓取的都不会被重抓
ITEM_PIPELINES = {
'huyaPro.pipelines.ImgsPipeline': 300,
}#这里的'huyaPro.pipelines. 后面接的是在pipelines.py代码里面自己新定义下载图片的类名ImgsPipeline(本文在pipelines.py代码里面定义下载图片的是: class ImgsPipeline(ImagesPipeline):)
ok,这样爬虫工程项目就完成了,下面是跑工程的效果图:
