一:闭包
1.1 什么是闭包


def outerFun(): name="Aaron" # 外层函数outerFun 中的变量 name def innerFun(): print(name) # 内层函数innerFun 引用了外层函数中的 name return innerFun f1= outerFun() f1() # 输出结果 Aaron
def outerFun(): nameList=[] # 外层函数outerFun 中的变量 nameList def innerFun(name): nameList.append(name) # 内层函数innerFun 引用了外层函数中的 nameList,并对其进行修改 print(nameList) return innerFun f1= outerFun() f1("赵") f1("钱") f1("孙") f2= outerFun() f2("Tom") f1("李") f2("Tony") ''' ['赵'] ['赵', '钱'] ['赵', '钱', '孙'] ['Tom'] ['赵', '钱', '孙', '李'] ['Tom', 'Tony'] '''
- 结论:外部变量跟着各自的闭包走,可传递。但闭包之间不受影响
def outfun(namelist=[]): def inner(name): namelist.append(name) print(namelist) return inner f = outfun() f("赵") f("钱") f("孙") f1 = outfun(namelist=["1"]) f1("2") f1("3") f("李") f1("4") """前方高能""" f2 = outfun() f2("A")
1.2 如何判断函数是否是闭包
def outerFun(): name="Aaron" # 外层函数outerFun 中的变量 name def innerFun(): print(name) # 内层函数innerFun 引用了外层函数中的 name return innerFun f1= outerFun() print(f1.__closure__) #输出结果 (<cell at 0x00E7FE10: str object at 0x00E7FDE0>,) print(outerFun.__closure__) # 输出结果 None
1.3 闭包的特点
- 安全
- 常驻内存
1.4 闭包练习题
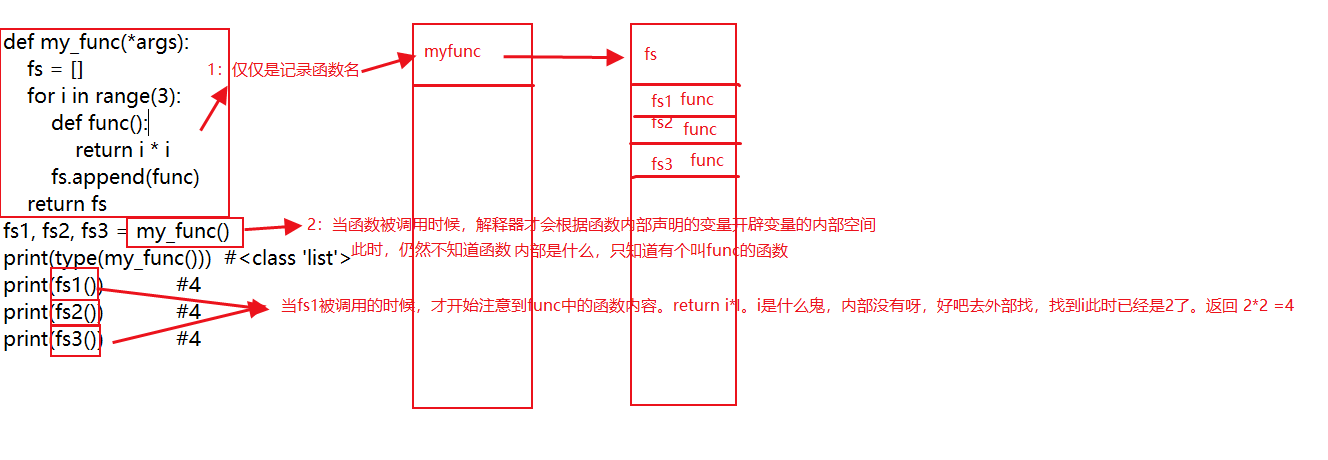
def my_func(*args): fs = [] for i in range(3): def func(): return i * i fs.append(func) return fs fs1, fs2, fs3 = my_func() print(type(my_func())) #<class 'list'> print(fs1()) #4 print(fs2()) #4 print(fs3()) #4
python解释器开始执⾏之后, 就会在内存中开辟⼀个空间, 每当遇到⼀个变量的时候, 就把变量名和值之间的关系记录下来, 但是当遇到函数定义的时候, 解释器只是把函数名读入内存, 表⽰这个函数存在了, ⾄于函数内部的变量和逻辑, 解释器是不关⼼的. 也就是说⼀开始的时候函数只是加载进来, 仅此⽽已, 只有当函数被调⽤和访问的时候, 解释器才会根据函数内部声明的变量来进⾏开辟变量的内部空间. 随着函数执⾏完毕, 这些函数内部变量占⽤的空间也会随着函数执⾏完毕⽽被清空.
def my_func(*args): fs = [] for i in range(3): def func(_i=i): return _i * _i fs.append(func) return fs fs1, fs2, fs3 = my_func() print(type(my_func())) #<class 'list'> print(fs1()) #0 print(fs2()) #1 print(fs3()) #4
结论:返回闭包中不要引用任何循环变量,或者后续会发生变化的变量
二:迭代器
1.1 迭代器协议
a:对象必须提供一个next方法,
b:执行方法要么返回迭代中的下一项,要么抛弃一个Stopiteration异常,
c:只能向后不能向前。
1.2 可迭代对象
实现了迭代器协议的对象。(对象内部定义一个__iter__()方法)
1.3 使用迭代器访问对象
检验可迭代对象向 Iterable: 可迭代对象. 内部包含__iter__()函数 Iterator: 迭代器. 内部包含__iter__() 同时包含__next__().
常见的 str,list, tuple, dict, set,都是可以迭代的。
from collections.abc import Iterable from collections.abc import Iterator l = [1,2,3] l_iter = l.__iter__() #检查是否是可迭代的对象 print(isinstance(l,Iterable)) #True print(isinstance(l,Iterator)) #False print(isinstance(l_iter,Iterator)) #True print(isinstance(l_iter,Iterable)) #True
st="hello"; # 先将字符串对象转化为可迭代对象 iterSt = st.__iter__() while True: try: print(iterSt.__next__()) except StopIteration: # print('迭代完成') break
三:生成器
1.1 什么是生成器?生成器的获取方法
使用了 yield 的函数被称为生成器,其实质就是迭代器.
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
1.2 生成器特征
生成器函数:使用yield语句返回结果,在每个结果中间,挂起函数的状态,以便下次从此处继续执行。
不用调用__iter__(),生成器生成的元素直接可调用__next__()方法。
1.3 获取生成器:
def fun(): print(111) yield 222 g = fun() #生成器 print(g); #输出结果:<generator object fun at 0x00EA5D30>
2: 通过生成器推导式来实现生成器
生成器表达式: (结果 for 变量 in 可迭代对象 if 条件筛选)
gen = (i for i in range(1, 10) if i%2==0)
1.4 遍历生成器:
1: 通过__next__()(一次只能获取一个)
2:通过send()(一次只能获取一个,可以传递参数)
3:通过for循环
4:通过list()将其转换为列表
def fun(): a = yield 1 print("接收send传递的值", a) b = yield 2 c = yield 3 d = yield 4 e = yield 5 gen = fun() print("通过__next__()获取:", gen.__next__()) hh=gen.send("12") print(hh) print("结论一:可以看出生成器是惰性机制,也可以叫做是懒加载。用一次给一次,节省内存!") for i in gen: print(i) print("结论二:由于生成器和迭代器类似一旦用过,不能再次使用!") print(list(gen)) ''' 输出结果 通过__next__()获取: 1 接收send传递的值 12 2 结论一:可以看出生成器是惰性机制,也可以叫做是懒加载。用一次给一次,节省内存! 3 4 5 结论二:由于生成器和迭代器类似一旦用过,不能再次使用! [] '''
注意:send和__next__()的区别在于,send()可以传递参数。但是send可以给上一个yield的位置传递值, 不能给最后一个yield发送值。同时生成器某些元素用完以后就没有了。
1.5. 其他推导式
列表推导式: [ 结果 for 变量 in 可迭代对象 if 条件 ]
lst = [i for i in range(1, 10) if i%2==0] # [2, 4, 6, 8]
字典推导式:{结果 for 变量 in 可迭代对象 if 条件}
dic = {i-1:i for i in range(1, 10) if i%2==0} #{1: 2, 3: 4, 5: 6, 7: 8}
集合推导式:{结果 for 变量 in 可迭代对象 if 条件}
set = {i%2for i in range(1, 10) } #{0, 1}
1.6. 练习题
1.6.1 人口普查小练习
{"location":"北京",'count':100}
{"location":"上海",'count':300}
{"location":"广州",'count':200}
{"location":"深圳",'count':400}
# 通过with as 的方式打开文件不用关闭 def getPeople(): with open("人口普查","r",encoding="utf-8") as f: for i in f: yield i g = getPeople(); amount=sum(eval(i)["count"] for i in g) h=getPeople() for i in h: print(eval(i)["location"]+"的人数为:"+ str(eval(i)["count"]) +",占统计总人数的"+str(eval(i)["count"]/amount)+"%") ''' 北京的人数为:100,占统计总人数的0.1% 上海的人数为:300,占统计总人数的0.3% 广州的人数为:200,占统计总人数的0.2% 深圳的人数为:400,占统计总人数的0.4% '''
1.6.2 生产者消费者模式
def consumer(name): print('我是【%s】,我准备开始吃包子了' %name) while True: baozi = yield print("【%s】很开心的吃掉了【%s】" %(name,baozi)) def producer(): c1=consumer('张三') c2=consumer("李四") c1.__next__() c2.__next__() for i in range(10): if i % 2 == 0: c1.send("包子 %s" %i ) else: c2.send("包子 %s" %i) producer() ''' 我是【张三】,我准备开始吃包子了 我是【李四】,我准备开始吃包子了 【张三】很开心的吃掉了【包子 0】 【李四】很开心的吃掉了【包子 1】 【张三】很开心的吃掉了【包子 2】 【李四】很开心的吃掉了【包子 3】 【张三】很开心的吃掉了【包子 4】 【李四】很开心的吃掉了【包子 5】 【张三】很开心的吃掉了【包子 6】 【李四】很开心的吃掉了【包子 7】 【张三】很开心的吃掉了【包子 8】 【李四】很开心的吃掉了【包子 9】 '''
# 猴子吃桃问题:猴子第一天摘下若干个桃子,当即吃了一半,还不瘾,又多吃了一个 # 第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下 # 的一半零一个。到第10天早上想再吃时,见只剩下一个桃子了。求第一天共摘了多少。 # 方法一,递归调用 def getNum(day,cou=1): cou =2 *(cou + 1) ; day-=1 if day==1: return cou; return getNum(day, cou) print(getNum(10)) # 方法二,递归调用 def f(n): if n ==1: return 1 return (f(n-1)+1)*2 print(f(10)) # 方法三,reduce函数 s=1 func=lambda x:(x+1)*2 for x in range(9): s=func(s) print(s)
1.6.3 判断输出结果
def add(a, b): return a + b def test(): for r_i in range(1,4): yield r_i g=test() for n in [2,10]: g=(add(n,i) for i in g) print(list(g)) #[21, 22, 23] #根据生成器惰性机制,只有在list(g)的时候才开始调用,此时g的内容是什么? # 当n=2 时 g=(add(n,i) for i in g) 但是此时仍然没有执行 # 当n=10 时 g=add(n,i) for i in (add(n,i) for i in g) ),开始执行。 # 内存计算后得:g=add(n,i) for i in [11,12,13] # 再次计算可得:[21,22,23]
四:装饰器
1.1 什么是装饰器?
装饰器 = 高阶函数 + 函数嵌套 + 闭包
本质就是函数,功能是为其他函数添加附加功能
原则:对修改封闭,对扩展开放
1:不能修改被修饰函数的源代码
2:不能修改被修饰函数的调用方式
# 装饰器=高阶函数+函数嵌套+闭包 # 高阶函数:传入参数或输出结果是一个函数 # 函数嵌套:函数中定义函数 import time def timmer(func): def wrapper(): startTime= time.time() func(); endTime= time.time() print("被测试函数一共运行:"+str(endTime-startTime)+"秒") return wrapper @timmer #语法糖,相当于#test=timmer(test) def test(): time.sleep(0.3); print("test函数运行完毕") test()
# 装饰器=高阶函数+函数嵌套+闭包 # 高阶函数:传入参数或输出结果是一个函数 # 函数嵌套:函数中定义函数 import time def timmer(func): def wrapper(*args,**kwargs): startTime= time.time() res=func(*args,**kwargs); endTime= time.time() print("被测试函数一共运行:"+str(endTime-startTime)+"秒") return res return wrapper @timmer #语法糖,相当于#test=timmer(test) def test(a,b): return a+b print(test(100,200))
# 装饰器=高阶函数+函数嵌套+闭包 # 高阶函数:传入参数或输出结果是一个函数 # 函数嵌套:函数中定义函数 import time # 添加一个参数,如果参数是n就打n折 def disCount(n=1): def timmer(func): def wrapper(*args,**kwargs): startTime= time.time() res=func(*args,**kwargs)*n; endTime= time.time() print("今天是国庆节,每位客户打的折扣为:"+str(n*10)) return res return wrapper return timmer #@timmer #语法糖,相当于#test=timmer(test) @disCount(n=0.9) def test(a,b): return a+b print(test(100,200))