对Discrete Mathematics Using a Computer的第一章Introduction to Haskell进行总结。环境Windows,关于函数的部分太长了,分开写。
常用的对列表list操作的函数common functions on lists,有些需要import Data.List才能使用。
length :: [a] -> Int --返回list中元素的数量
sort :: Ord a => [a] -> [a] --默认按升序排序
or :: [Bool] -> Bool --对Bool的list中的所有元素进行||,如果有True,则时True
and :: [Bool] -> Bool --对Bool的list中的所有元素进行&&,如果有False,则False
(!!) :: [a] -> Int -> a --返回指定下标的元素,下标从0开始,如:
[1, 2, 3] !! 0 => 1
"abcde" !! 2 => 'c'
elem :: Eq a => a -> [a] -> Bool --判断该元素是否在list中,在则True,不再则False
null :: [a] -> Bool --判断list是否为空,空则True,非空则False
head 和 tail对list[1,2,3,4,5,6,7,8,9,10]的结果是:
1 [2, 3, 4, 5, 6, 7, 8, 9, 10]
head --' <--------------tail-------------->
last 和 init对list[1,2,3,4,5,6,7,8,9,10]的结果是:
[1, 2, 3, 4, 5, 6, 7, 8, 9] 10
<---------------init------------> '-- last
take :: Int -> [a] -> [a] --从list中取出指定数量的元素,如:
take 0 [1, 2, 3] => []
take 2 [1, 2, 3] => [1, 2]
takeWhile :: (a -> Bool) -> [a] -> [a] --

dropWhile :: (a -> Bool) -> [a] -> [a] -- 与上同理
drop :: Int -> [a] -> [a] --从list中去除指定数量的元素,如:
drop 2 [1, 2, 3] => [3]
drop 0 [1, 2, 3] => [1, 2, 3]
nub :: Eq a => [a] -> [a] -- 该函数在Data.List中,将list中重复的元素删除,如:
nub [1, 1, 3, 3, 2, 1] => [1, 3, 2]
delete :: Eq a => a -> [a] -> [a] --将list中第一个出现的目标元素删除,如:
delete 3 [2, 3, 4, 3] => [2, 4, 3]
group :: Eq a => [a] -> [[a]] --将相邻的相同元素合成list,结果是list的list,如:
group [1, 1, 1, 3, 3, 2, 1] => [[1, 1, 1], [3, 3], [2], [1]]
(++) :: [a] -> [a] -> [a] --将两个相同类型的list连接在一起,如:
[1, 2] ++ [3, 4, 5] => [1, 2, 3, 4, 5]
[] ++ "abc" => "abc"
(\) :: Eq a => [a] -> [a] -> [a] --前面的list中的元素减去后面list的元素,如:
[1, 2, 3, 2] \ [2, 1] => [3, 2]
map :: (a -> b) -> [a] -> [b] --将原本只对一个元素应用的操作,应用到该list的所有元素中,类似于C的for循环。如:
map toUpper "the cat and dog" => "THE CAT AND DOG"
map (* 10) [1, 2, 3] => [10, 20, 30]
Note: 当操作很复杂时,用lambda的形式,即x->exp来代替,x则代表了list中的元素,这点对map、filter都可用,如:
getTwos xs = filter (ys -> length ys == 2) xs
flip :: (a -> b -> c) -> (b -> a -> c) --用于对调其他函数形参的位置,用于调用高阶函数的时候,形参位置不符合的时候,如:
any (flip elem "aeiou") "hmmmm"
any :: (a -> Bool) -> [a] ->Bool --高阶函数,如:
any (x -> elem x "aeiou") "sky" => False
all :: (a ->Bool) -> [a] -> Bool --高阶函数,如:
all (elem 'e') ["eclectic", "elephant", "legion"] => True
span ::(a -> Bool) -> [a] -> ([a], [a]) --将列表分为两类,结果为True的和False的。
filter :: (a -> Bool) -> [a] -> [a] --将list中结果为False的筛选除去留下结果为True的元素,如:

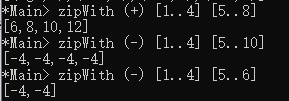
zip :: [a] -> [b] -> [(a, b)] --分别从[a]和[b]中取出元素两两配对pair(2-tuples),一方用完后,另一方剩余的舍弃掉,如:

zipWith :: (a -> b -> c) -> [a] -> [b] -> [c] --分别从[a]和[b]中取出元素作为参数,多余的舍弃。如:
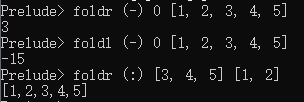
fold function: 和map类似,但结果是一个值,有3个参数:操作符 a list。a作为默认值,该函数是从a和list的一个元素进行操作符计算然后和下一个list中的元素进行操作,最终得出一个值,分为foldl和foldr对应了从list的不同方向进行操作。因为有a的存在保证的对空list也能进行操作,其结果就是a。
foldl :: (a -> b -> b) -> b -> [a] -> b {-
从[a]的左端开始进行操作, 如 foldl (-) a [p, q, r, s]
(-) a p ------------1 注意a在左侧
(-) ( ) q -----------2
(-) ( ) r --------3
(-) ( ) s ----4
-}
foldr :: (a -> b -> b) -> b -> [a] -> b {-
从[a]的右端开始进行操作, 如 foldr (-) a [p, q, r, s]
(-) s a --------1 注意a在右侧
(-) r ( ) -------2
(-) q ( ) ----3
(-) p ( ) ---4
-}
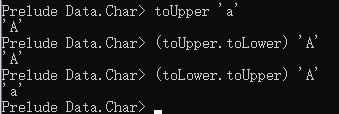
. 操作(the composition operator),相当于连续进行2个函数操作:函数2.函数1 a ,先执行函数1 a,再将其结果作为函数2的参数。如:
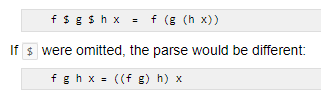
$ 将表达式中出现在$后面的内容在实际运行是最先运行,相当于给后面的加了括号。如: